一种全网络异常数据流分类方法与流程
本发明涉及信息安全技术领域,特别涉及一种全网络异常数据流分类方法。
背景技术:
随着网络的发展,网络异常行为包括网络故障、用户误操作、网络攻击和网络病毒传播等,这些异常行为常常引起网络中单条或多条链路上网络流量偏离正常的现象,这些异常行为中的任何一个引起网络流量异常时都有其固定的行为模式,比如DOS/DDOS等拒绝服务式攻击表现为大量受控主机向目标主机的流量汇聚,受控主机全都具有相同的目的地址;蠕虫病毒是一种常见的与网络安全相关的计算机病毒,它利用网络进行复制和传播,在传播时,通常会以宿主机器作为扫描源,扫描网络中的其它主机,并寻找漏洞,在整个网络中常表现为同一源地址对多个IP地址的特定端口的扫描,具有全局特性;木马和僵尸程序是黑客们最常利用的工具,木马是盗取用户个人信息或远程控制用户计算机的恶意程序,僵尸程序是被黑客集中控制的计算机集群,能够同时对目标网络进行拒绝服务式攻击,其网络流量具有相同的源IP地址;还有利用网络误配置、网络设备故障、网络Flash拥挤等导致的与网络故障和性能相关的异常等。因此为了在网络异常行为发生时快速地制定出应急方案,降低异常事件的危害,需要实时地对网络异常行为进行分类找到引起异常行为的根本原因。
现有技术中一般采用基于IP流的抽样方法抽取出异常数据流量,然后对异常数据流量进行分类采用有监督模式识别,即用一组已知类别的样本作为训练集,建立数学模型,再用己建立的模型对未知样本进行判别,以确定未知样本应归属的类别,这种模式的训练集一般首先限定了引起数据流量异常原因的类别特征,但是由于网络异常的复杂性和变化性,这种方法的精确性难以保证。
技术实现要素:
本发明的目的是针对上述现有技术的不足,而提供一种能够在未知引起数据流量异常原因的种类的情况下,对异常数据流进行简单、精确、高效的分类方法。
为解决上述技术问题,本发明采用的一个技术方案是:提供一种全网络异常数据流分类方法,该方法用于对抽取的计算机网络数据流量中的异常数据流进行分类,包括以下步骤:
步骤S1:对全网络数据流量进行异常数据流量抽取,并输出异常数据流量中的异常数据流的集合{S1、S2、…、Si};
步骤S2:计算上述异常数据流按包计数时的异常数据流的大小的平均值其中1≤p≤i,计算上述异常数据流按照字节计数时的包的大小的平均值其中1≤p≤i,提取上述异常数据流的至少一个特征,并分别统计提取的特征的分布熵H,以所述的以及各特征的分布熵H作为坐标值,将上述异常数据流进行特征向量化,形成多维空间中的点集;
步骤S3:将上述的点集根据Canopy计算方法进行粗聚类,得到该点集的聚类中心以及该聚类中心的中心点的个数K值;
步骤S4:根据上述聚类中心以及K值采用K-means计算方法将上述特征向量化后的异常数据流进行细聚类,最终得到异常数据流的精确分类结果。
在本发明全网络异常数据流分类方法的另一个实施例中,在步骤S2中,将上述的异常数据流进行特征向量化所提取的特征包括:源IP地址、目的IP地址、源端口号、目的端口号、输入的路由器接口、输出的路由器接口、前一跳自治系统号、后一跳自治系统号、源自治系统号、目的自治系统号。
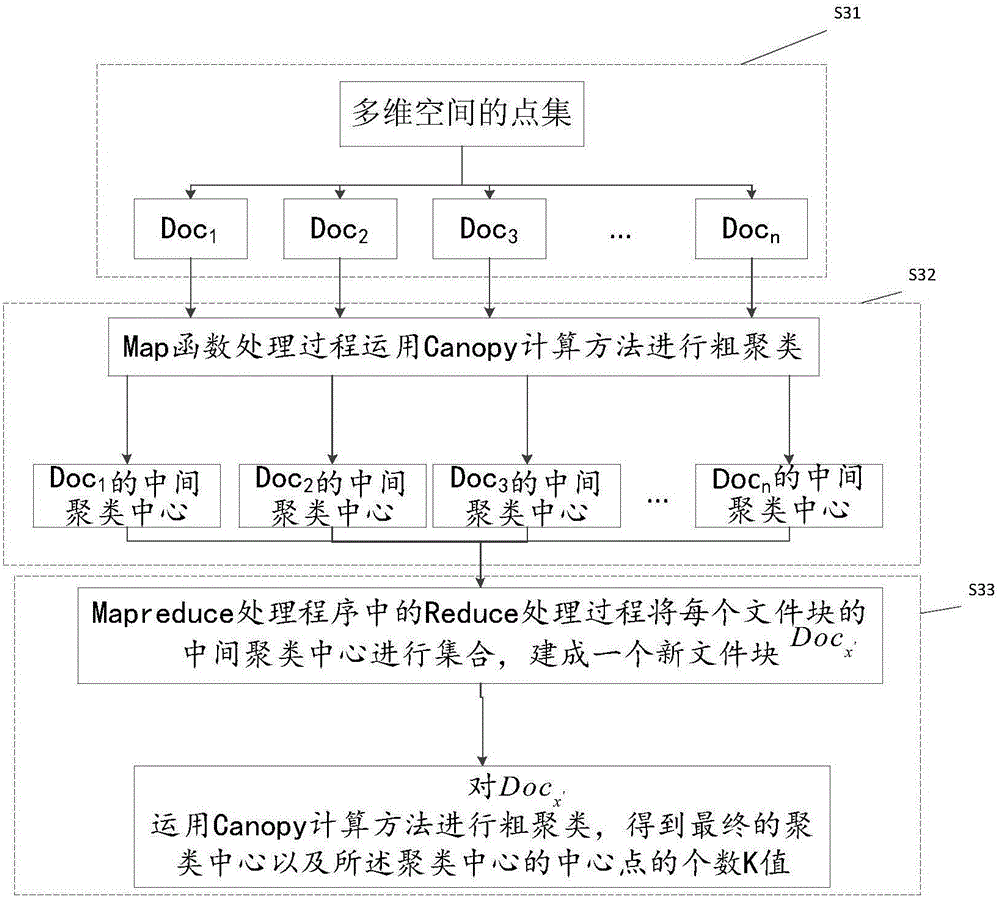
在本发明全网络异常数据流分类方法的另一个实施例中,在步骤S3中,将该点集根据Canopy计算方法进行粗聚类,得到聚类中心以及该聚类中心的中心点的个数K值的方法包括:
S31:将该点集分成大小固定的文件块Doc1、Doc2、…、Docn的集合{Doc1、Doc2、…、Docn};
S32:将该文件块的集合{Doc1、Doc2、…、Docn}送入到Mapreduce处理程序中,使其中每个文件块Docx(其中1≤x≤n),对应一个Map函数处理过程,每个Map函数处理过程将对应的文件块Docx中的点,运用Canopy计算方法进行粗聚类,得到每个文件块Docx的中间聚类中心;
S33:Mapreduce处理程序中的Reduce处理过程将上述每个文件块Docx的中间聚类中心进行集合,建成一个新文件块Docx',将该新文件块Docx'再次运用Canopy计算方法进行粗聚类,得到最终的聚类中心以及该聚类中心的中心点的个数K值。
在本发明全网络异常数据流分类方法的另一个实施例中,上述Canopy计算方法包括:
S3A:设定两个阈值参数T1和T2,且T1<T2;
S3B:将上述的文件块中的第一个点存入到一个Canopy中,该第一个点作为该Canopy的中心点,并将该Canopy放入到Canopy集合中作为该Canopy集合的子集;
S3C:继续读取该文件块中的点M,利用距离计算方法计算该点M分别与上述Canopy集合中的所有子集的中心点的距离,分别得到距离值D1、D2、…、Dn;
S3D:将距离值D1、D2、…、Dn与上述的T1和T2比较,分以下情况处理:
距离值D1、D2、…、Dn中小于T2的,将该点M分别加入到这些距离值对应的子集中,如果小于T2的距离值中有小于T1的,则将该点M从该文件块中删除,如果小于T2的距离值均大于等于T1,则将该点M仍保留在该文件块中;
距离值D1、D2、…、Dn均大于T2,则将该点M存入到新建的Canopy中,并作为新建的Canopy的中心点,之后将该新建的Canopy也放入到上述的Canopy集合中作为子集;
S3E:依次读取该文件块中的点,每读取一个点,依次执行步骤S3C、S3D,直到不需要新建Canopy为止;
S3F:将得到的Canopy集合中的每个子集的度量值求均值,得到聚类中心。
在本发明全网络异常数据流分类方法的另一个实施例中,在步骤S2中,提取异常数据流的源IP地址srcIP和源端口号srcport两个特征,计算源IP地址的分布熵H(srcIP),计算源端口号的分布熵H(srcport),以所述H(srcIP)、H(srcport)、为坐标值,对所述异常数据流进行特征向量化。
在本发明全网络异常数据流分类方法的另一个实施例中,在步骤S3C中,该距离计算方法采用曼哈顿距离方法,方法如下:
式中:
D—两点距离;
xn—文件块Docx或Docx'中的任一点的源IP地址特征坐标值,—为中心点的源IP地址特征坐标值;
Yn—文件块Docx或Docx'中的任一点的源端口号特征坐标值,—为中心点的源端口号特征坐标值。
在本发明全网络异常数据流分类方法的另一个实施例中,在步骤S4中,采用K-means计算方法将该异常数据流进行细聚类的方法包括:
S41:根据步骤S3中所述的聚类中心的中心点的个数K值,将该点集分成大小固定的K个文件块A1、A2、…、Ak,并将步骤S3中所述的聚类中心作为K-means计算方法的初始中心;
S42:将该K个文件块A1、A2、…、Ak分别送入到Mapreduce处理程序中,使每个文件块对应一个Map函数处理过程;
S43:每个Map函数处理过程采用K-means计算方法,得到该初始中心的中心点key和该文件块Ax中的每个点value对应分配形成的{key,value}键值对,其中,1≤x≤k;
S44:每个Map函数处理过程将文件块中相同key的value值进行集合,形成“(key),{value1,value2,…,valuek}”格式的集合列表,并送入到Reduce处理过程中;
S45:再由该Reduce处理过程将不同的Map函数处理过程送进来的集合列表中相同key的value值进行统计集合,并把每个key的value值新建成一个文件块,得到新建的文件块B1、B2、…、Bo;
S46:分别计算该新建的文件块B1、B2、…、Bo的中心点,并将该文件块B1、B2、…、Bo的中心点的集合重新作为K-means计算方法的初始中心;
S47:将该文件块B1、B2、…、Bo作为新输入的文件块返回到步骤S42进行处理,再依次执行步骤S43、步骤S44、步骤S45、步骤S46,直到初始中心不再发生变化,得到最终的异常数据流的精确分类结果。
在本发明全网络异常数据流分类方法的另一个实施例中,所述K-means计算方法包括:
S4A:设定一个阈值T3;
S4B:将文件块中的点分别与初始中心的中心点计算距离,得到距离值D1'、D2'、…、Do';
S4C:该距离值D1'、D2'、…、Do'小于T3的点与该的中心点形成以该中心点为键,该点为值的{key,value}形式的键值对。
本发明的有益效果是:本发明提供的全网络异常数据流分类方法,采用了先将抽取的异常数据流根据提取的特征进行特征向量化,形成空间点集,然后对该空间点集根据Canopy计算方法进行粗聚类,得到该点集的聚类中心以及K值,再将该聚类中心作为初始中心,采用K-means计算方法将所述特征向量化后的异常数据流进行细聚类,最终得到异常数据流的精确分类结果。本发明采用的Canopy计算方法,不需要提前知道引起异常数据流的原因的种类,粗聚类计算得出初始的引起异常的原因的种类,然后再利用K-means算法简单高效的对异常数据流进行分类。本发明的方法将无规律的异常数据流划分为有规律的类别,从而提高本发明分类方法的计算质量,降低本发明分类方法的计算复杂度。本发明的方法适用在基于Mapreduce并行编程模型的程序中,能够充分满足全网络流量数据复杂且多的情况,简单、高效、准确的将异常的数据流进行分类。
附图说明
图1是根据本发明全网络异常数据流分类方法的一实施例的流程图;
图2是根据本发明全网络异常数据流分类方法的另一实施例中的基于Mapreduce并行编程模型中的Canopy计算方法进行粗聚类的方法的流程图;
图3是应用图2的实例图;
图4是根据本发明全网络异常数据流分类方法的另一实施例中的基于Mapreduce并行编程模型中的K-means计算方法进行细聚类的方法的流程图;
图5是应用图4的实例图。
具体实施方式
为了便于理解本发明,下面结合附图和具体实施例,对本发明进行更详细的说明。附图中给出了本发明的较佳的实施例。但是,本发明可以以许多不同的形式来实现,并不限于本说明书所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
需要说明的是,除非另有定义,本说明书所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是用于限制本发明。
图1是根据本发明一实施方式对全网络异常数据流分类方法的流程图。从图1可以看出,该流程始于开始,然后,依次执行步骤S1,对全网络数据流量进行异常数据流量抽取,并输出异常数据流量中的异常数据流的集合{S1、S2、…、Si};
步骤S2:计算所述异常数据流按包计数时的异常数据流的大小的平均值(其中1≤p≤i),计算所述异常数据流按照字节计数时的包的大小的平均值(其中1≤p≤i),提取所述异常数据流的至少一个特征,并分别统计提取的特征的分布熵H,以所述的以及各特征的分布熵H作为坐标值,将所述异常数据流进行特征向量化,形成多维空间中的点集;
步骤S3:将该点集根据Canopy计算方法进行粗聚类,得到聚类中心以及该聚类中心的中心点的个数K值;
步骤S4:根据该聚类中心以及该K值采用K-means计算方法将上述特征向量化后的异常数据流进行细聚类,最终得到异常数据流的精确分类结果。
在步骤S1中,该方法虽然将抽取的全网络异常数据流作为输入,但是却对异常数据流的抽取方法没有什么限制,两部分是相对独立运行的,抽取的方法可以使用现在常用的技术,例如现有技术中的基于IP流抽样方法等。
优选的,对于步骤S2中,将异常数据流进行特征向量化所提取的特征包括:源IP地址、目的IP地址、源端口号、目的端口号、输入的路由器接口、输出的路由器接口、前一跳自治系统号、后一跳自治系统号、源自治系统号、目的自治系统号。在互联网中,一个自治系统(AS)是一个有权自主地决定在本系统中应采用何种路由协议的小型单位。一个自治系统有时也被称为是一个路由选择域,一个自治系统将会分配一个全局的唯一的号码,我们把这个号码叫做自治系统号,前一跳和后一跳自治系统号是指,指在路由器在未连接到目的网络时会有一个提供后一跳路由的邻居路由器,用来传递数据到目的地,此时当有两个相邻的路由协议选择时,自治系统提供的两个号码。
其中特征:源IP地址、目的IP地址、源端口号、目的端口号说明了一条数据流在开始和结束时的主机;特征:输入的路由器接口、输出的路由器接口、前一跳自治系统号、后一跳自治系统号、源自治系统号、目的自治系统号说明的是一条数据流选择的网络路径,所以当抽取出异常数据流时,首先是将上述的特征提取出来,按照数据流的源端口号、源IP地址、源端自治系统号、前一跳自治系统号、输入的路由器接口、输出路由器接口、后一跳自治系统号、目的自治系统号、目的IP地址、目的端口号这样的顺序依次提取特征。分别计算出异常数据流按包计数时的异常数据流的大小的平均值(其中1≤p≤i),计算所述异常数据流按照字节计数时的包的大小的平均值(其中1≤p≤i),以及这十个特征的分布熵H,将这十个特征分布熵H、作为坐标值,将异常数据流特征向量化,提取这十个特征,能够使异常数据流分类更精确,分析异常原因时更清楚明了,不会出现遗漏的现象。
通过以上步骤S1和步骤S2优选的实施例抽取出了异常数据流以及将这些异常数据流进行向量化,形成点集,接下来就需要对该点集进行聚类处理,聚类最耗费时间的地方就是计算数据的相似性,所以本发明的方法采用首选对该点集做预处理,先进行一次粗聚类,其中粗聚类采用Canopy计算方法,该方法相对简单,并且计算代价较低。
下面以本发明的另一个实施例结合图2和图3,对步骤S3中根据Canopy计算方法进行粗聚类,得到上述点集的聚类中心以及该聚类中心的中心点的个数K值的方法进行说明,如图2所示基于Mapreduce并行编程模型中的Canopy计算方法进行粗聚类的方法的流程图,包括如下步骤:
S31:将步骤S2中所述的点集分成大小固定的文件块Doc1、Doc2、…、Docn的集合{Doc1、Doc2、…、Docn};
S32:将所述文件块的集合{Doc1、Doc2、…、Docn}送入到Mapreduce处理程序中,使其中每个文件块Docx,其中1≤x≤n,对应一个Map函数处理过程,每个Map函数处理过程将对应的文件块Docx中的点,运用Canopy计算方法进行粗聚类,得到所述每个文件块Docx的中间聚类中心;
S33:Mapreduce处理程序中的Reduce处理过程将所述每个文件块的中间聚类中心进行集合,建成一个新文件块Docx',将所述新文件块Docx'再次运用Canopy计算方法进行粗聚类,得到最终的聚类中心以及所述聚类中心的中心点的个数K值。
结合图3所示的应用上述Canopy计算方法进行粗聚类的实例,具体说明上述的方法。
首先,在步骤S2中,提取源IP地址srcIP和源端口号srcport两个特征,计算源IP地址的分布熵H(srcIP),计算源端口号的分布熵H(srcport),在以H(srcIP)、H(srcport)结合值和作为异常数据流的坐标值,将异常数据流进行特征向量化,形成{H(srcIP)、H(srcport)}格式的二维空间的点集,如图3中T1部分所示;
执行进入Mapreduce处理程序。
在步骤S31中,将步骤S2中的点集分成如图3中T2部分所示的两个文件块,T2-1[{8.1,8.1}、{7.1,7.1}、{6.2,6.2}、{7.1,7.1}、{2.1,2.1}、{1.1,1.1}、{3.0,3.0}、{0.1,0.1}]和T2-2[{8,8}、{7,7}、{6.1,6.1}、{9,9}、{2,2}、{1,1}、{0,0}、{2.9,2.9}];
在步骤S32中,将这两个文件块分别送入到Mapreduce处理程序中,使其中每个文件块对应一个Map函数处理过程,如图3所示T2-1文件块对应Mapper1,T2-2文件块对应Mapper2,每个Map函数处理过程运用Canopy计算方法进行粗聚类,得到如图3中的T3部分所示,T2-1文件块的中间聚类中心为[{7.125,7.125},{1.575,1.575},{0.1,0.1}],T2-2文件块的中间聚类中心为[{7.525,7.525},{1.475,1.475},{0,0}];
在步骤S33中,Mapreduce处理程序中的Reduce处理过程将两个文件块的中间聚类中心进行集合,建成一个如图3中的T4部分所示的新文件块[{7.125,7.125},{1.575,1.575},{0.1,0.1},{7.525,7.525},{1.475,1.475},{0,0}],再将该文件块再次运用Canopy计算方法进行粗聚类,得到如图3中的T5部分所示的最终的聚类中心[{7.325,7.325},{0.7875,0.7875}],以及该聚类中心的中心点的个数K=2。
该方法采用Mapreduce处理程序将分成固定大小的异常数据流文件块并行计算,能够充分满足全网络数据流量复杂且多的情况,简化了计算程序,缩短计算过程,提高方法的效率。
对于该Canopy计算方法首先先定义两个概念:
定义1(Canopy):对于给定的数据集合Y={yi|i=1,2,...n},对于任意xi∈Y,满足
则xi称为Canopy集合。
式中:
Cj——Canopy中心点;
T2——Canopy集合半径的阈值。
定义2(Canopy中心点):对于给定的数据集合Y={yi|i=1,2,...n},对于任意xi∈Y,满足:
则称Cm为非Canopy候选中心点。
把相近的数据放在一个子集内,这种对数据对象进行预处理的方法就做Canopy,经过处理的数据分为多个Canopy,Canopy之间可以重叠,但不会出现数据遗漏的情况。在使用Canopy计算方法时,要求输入两个阈值参数T1和T2,阈值参数不能过大,Canopy之间的重叠不能太多,参数过大或者重叠太多会大大减少后续需要计算相似性的数据个数,此时数据分类比较含糊。
以下将对上述步骤S3中Canopy计算方法进行描述包括:
S3A:设定两个阈值参数T1和T2,且T1<T2;
S3B:将文件块中的第一个点存入到一个Canopy中,该第一个点作为该Canopy的中心点,并将该Canopy放入到Canopy集合中作为该Canopy集合的子集;
S3C:继续读取该文件块中的点M,利用距离计算方法计算该点M分别与上述Canopy集合中的所有子集的中心点的距离,分别得到距离值D1、D2、…、Dn;
S3D:将距离值D1、D2、…、Dn与上述的T1和T2比较,分以下情况处理:
距离值D1、D2、…、Dn中小于T2的,将该点M分别加入到这些距离值对应的子集中,如果小于T2的距离值中有小于T1的,则将该点M从该文件块中删除,如果小于T2的距离值均大于等于T1,则将该点M仍保留在该文件块中;
距离值D1、D2、…、Dn均大于T2,则将该点M存入到新建的Canopy中,并作为新建的Canopy的中心点,之后将该新建的Canopy也放入到上述的Canopy集合中作为子集;
S3E:依次读取该文件块中的点,每读取一个点,依次执行步骤S3C、S3D,直到不需要新建Canopy为止;
S3F:将得到的Canopy集合中的每个子集的度量值求均值,得到聚类中心。
下面将以一个二维空间的点集形成的文件块{(8.1,8.1),(7.1,7.1),(6.2,6.2),(7.1,7.1),(2.1,2.1),(1.1,1.1),(0.1,0.1),(3.0,3.0)}为例对如何使用Canopy计算方法,进行详细说明:
设定的两个阈值参数T1=4和T2=8,读取文件块中的第一个点(8.1,8.1)存入到Canopy1中,并从该文件块中删除这个点,该点作为Canopy1的中心点,并将该Canopy1放入到Canopy集合中作为该Canopy集合的子集;然后开始遍历整个文件块中其它点与它的距离。
本例中优选的距离计算方法采用采用曼哈顿距离方法,方法如下:
式中:
D—两点距离;
xn—该文件块中的任一点的源IP地址特征坐标值,—为中心点的源IP地址特征坐标值;
Yn—该文件块中的任一点的源端口号特征坐标值,—为中心点的源端口号特征坐标值;
读取该文件块中的第二点(7.1,7.1),计算得到该点与Canopy1中心点(8.1,8.1)之间的距离为2,2小于T2,且同时小于T1,则将该点(7.1,7.1)加入到Canopy1,并从该文件块中删除该点;
继续读取第三个点(6.2,6.2),计算该点与Canopy1中心点(8.1,8.1)的距离是3.8,3.8小于T2,同时也小于T1,所以第三点(6.2,6.2)也是属于Canopy1。同样将其加入Canopy1中,并从该文件块中删除该点;
读取第四个点(7.1,7.1),该点与Canopy1中心点(8.1,8.1)的距离为2,2小于T2,同时也小于T1,将该点(7.1,7.1)加入到Canopy1中,并从该文件块中删除该点;
读取第五个点(2.1,2.1),计算该点与Canopy1中心点(8.1,8.1)的距离是12,大于T2,所以该点(2.1,2.1)不属于Canopy1,新建成一个Canopy2,将该点(2.1,2.1)加入到新建的Canopy2中,并作为其中心点,并将该点从该文件块中删除,将该Canopy2也放入到上述的Canopy集合中作为子集;
读取第六个点(1.1,1.1),计算该点到Canopy1中心点(8.1,8.1)的距离是14,14大于T2,到Canopy2中心点(2.1,2.1)的距离是2,2小于T2,同时也小于T1,所以将第六个点加入到Canopy2中,并将该点从该文件块中删除;
读取第七个点(0.1,0.1),计算该点到Canopy1中心点(8.1,8.1)的距离是16,16大于T2,到Canopy2中心点(2.1,2.1)的距离是4,4小于T2且4=T1,所以将第七个点加入到Canopy2中,但该点仍保留在该文件块中;
读取第八个点(3.0,3.0),计算该点到Canopy1中心点(8.1,8.1)的距离是10.2,10.2大于T2,到Canopy2中心点(2.1,2.1)的距离是1.8,1.8小于T2,且也小于T1,所以将该点加入到Canopy2。
此时所有的Canopy的状态是:
Canopy1(8.1,8.1):{(8.1,8.1),(7.1,7.1),(6.2,6.2),(7.1,7.1)}
Canopy2(2.1,2.1):{(2.1,2.1),(1.1,1.1),(0.1,0.1),(3.0,3.0)}
此时文件块中还剩下一个点是(0.1,0.1),将它自己作为一个新的Canopy即Canopy3(0.1,0.1);
此时Canopy集合中的Canopy的最后状态是:
Canopy1(8.1,8.1):{(8.1,8.1),(7.1,7.1),(6.2,6.2),(7.1,7.1)}
Canopy2(2.1,2.1):{(2.1,2.1),(1.1,1.1),(0.1,0.1),(3.0,3.0)}
Canopy3(0.1,0.1):{(0.1,0.1)};
最后将Canopy集合中的每个子集的坐标值分别求均值,得到每个Canopy的中心点,即
Canopy1为Canopy1(7.125,7.125)
Canopy2为Canopy2(1.575,1.575)
Canopy 3(0.1,0.1)
最终得到聚类中心{(7.125,7.125),(1.575,1.575),(0.1,0.1)},该聚类中心的中心点个数K=3。
通过以上对从步骤S3的优选实施例,得到了聚类中心以及聚类中心的中心个数K值,接下来将根据得到的聚类中心以及K值,对异常数据流进行细聚类。
图4所示是根据本发明全网络异常数据流分类方法的另一实施例中的基于Mapreduce并行编程模型中的K-means计算方法进行细聚类的方法的流程图。由图4可以看出该流程包括如下步骤:
S41:根据步骤S3中所述聚类中心的中心点的个数K值,将所述的多维空间的点集分成大小固定的K个文件块A1、A2、…、Ak,并将所述聚类中心作为K-means计算方法的初始中心;
S42:将所述K个文件块A1、A2、…、Ak分别送入到Mapreduce处理程序中,使每个文件块对应一个Map函数处理过程;
S43:每个Map函数处理过程采用K-means计算方法,得到所述初始中心的中心点key和所述文件块Ax(其中1≤x≤k)中的每个点value对应分配形成的{key,value}键值对;
S44:每个Map函数处理过程将文件块中相同key的value值进行集合,形成“(key),{value1,value2,…,valuek}”格式的集合列表,并送入到Reduce处理过程中;
S45:再由所述Reduce处理过程将不同的Map函数处理过程送进来的集合列表中相同key的value值进行统计集合,并把每个key的value值新建成一个文件块,得到新建的文件块B1、B2、…、Bo;
S46:分别计算所述新建的文件块B1、B2、…、Bo的中心点,并将所述文件块B1、B2、…、Bo的中心点的集合重新作为K-means计算方法的初始中心;
S47:将所述文件块B1、B2、…、Bo作为新输入的文件块返回到步骤S42进行处理,再依次执行步骤S43、步骤S44、步骤S45、步骤S46,直到初始中心不再发生变化,得到最终的异常数据流的精确分类结果。
下面结合图5所示的应用上述K-means计算方法进行细聚类的实例,具体说明上述的方法。
首先将聚类中心[{7.325,7.325},{0.7875,0.7875}]作为K-means计算方法的初始中心,K值为2。在步骤S41:根据聚类中心的中心点的个数K=2,将上述向量化后的点集如图5中F1部分所示,分成大小固定的2个文件块A1、A2。
在步骤S42中,将步骤S41中的2个文件块A1、A2分别送入到Mapreduce处理程序中,使每个文件块对应一个Map函数处理过程,如图5中所示,A1对应Mapper1,A2对应Mapper2。
在步骤S43中,每个Map函数处理过程采用K-means计算方法,得到初始中心的中心点[{7.325,7.325},{0.7875,0.7875}]和文件块A1、A2中的每个点value对应分配形成的{key,value}键值对,如图5中F2部分所示,例如{(7.325,7.325),(8.1,8.1)}。
在步骤S44中,每个Map函数处理过程将文件块中相同key的value值进行集合,形成如图5中F3部分所示的集合列表,例如“(7.325,7.325),{(8.1,8.1),(7.1,7.1),(6.2,6.2),(7.1,7.1)}”,并该集合列表送入到Reduce处理过程中。
在步骤S45中,再由所述Reduce处理过程将不同的Map函数处理过程送进来的集合列表中{7.325,7.325}和{0.7875,0.7875}这两个key的value值分别进行统计集合,并把每个key的value值新建成一个文件块,得到如图5中F4部分所示的新建的文件块B1、B2;
在步骤S46中:截止到步骤S45,第一轮的分类已经完成后再分别计算新建的文件块B1、B2的中心点,并将文件块B1、B2的中心点的集合重新作为K-means计算方法的初始中心;
在步骤S47中:将两个新建的文件块B1、B2作为新输入的文件块返回到步骤S42进行处理,再依次执行步骤S43、步骤S44、步骤S45、步骤S46,直到初始中心不再发生变化,得到最终的异常数据流的精确分类结果。
在上述步骤S43中用到了K-means计算方法,以下对该方法做具体的描述,该方法包括:
S4A:设定一个阈值T3;
S4B:将文件块中的点分别与初始中心的中心点[{7.325,7.325},{0.7875,0.7875}]计算距离,得到距离值D1'、D2'、…、Do';
S4C:距离值D1'、D2'、…、Do'小于T3的点与对应的中心点形成以该中心点为键,该点为值的{key,value}形式的键值对,例如图5中F2部分所示的{(7.325,7.325),(8.1,8.1)}。
本发明提出的新的分类方法,这种分类方法不需要预先知道异常数据流集中有多少种类的异常。这一点是非常重要的,因为操作者根本不能知晓在具体网络中有多少引起异常数据流的原因种类。本发明的分类方法将无规律的异常数据流划分为有规律的异常数据流的类别,依然保留K-means细聚类方法,从而提高算法的计算质量,降低计算复杂度,实现简单,计算效率高,分类效果好等优点。
本发明同时适用于Mapreduce处理程序,缩减了计算时间,进一步提高计算效率。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构变换,或直接或间接运用在其他相关的技术领域,均包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!