基于三维扫描的门禁识别系统的利记博彩app
本发明涉及门禁技术领域,更具体地,涉及一种基于三维扫描的门禁识别系统。
背景技术:
人脸识别系统以人脸识别技术为核心,是一项新兴的生物识别技术,是当今国际科技领域攻关的高精尖技术。人脸因具有不可复制、采集方便、不需要被拍者的配合,使得人脸识别系统具有广泛的应用。如今,人脸识别技术已经被广泛地应用于门禁等安防领域。
人脸识别技术主要还是依靠二维图像识别方式,其方法为根据二维平面人脸侧影或某视角提取并识别人脸特征。这种方法的可靠性差,受到被识别人的面部姿态、光照的影响较大。相对应地,三维人脸识别技术准确度高、适应性强、抗攻击性强、抗欺诈性强,比二维图像的人脸识别技术更加可靠。
然而,现有的三维人脸识别技术主要关注的是如何对面部关键识别部位建模以及克服光线带来的影响。但实际上,由于门禁应用的环境的特殊性,被识别人可能处于恶劣天气系统下,例如淋雨、下雪、雾霾等,造成了被识别人局部特征的不清楚,进而影响到了三维面部识别时的准确度。
技术实现要素:
为了克服气象条件对三维人脸识别技术在识别准确度上的不利影响,本发明提供了一种基于三维扫描的门禁识别系统,其特征在于,包括:基于多次扫描的三维人脸识别单元、数据库以及报警单元,所述基于多次扫描的三维人脸识别单元用于在待识别人处于雨或雪自然环境条件下时进行人脸识别,所述数据库存储能够通过所述三维人脸识别单元进行人脸识别的人员的声纹信息和面部正面图像,所述报警单元用于根据所述三维人脸识别单元进行报警。
进一步地,所述基于多次扫描的三维人脸识别单元包括:
声音信号采集模块,用于采集待识别人的声音信号,并基于此声音信号获得待识别人声称的身份信息;
待识别人正面的雨或雪的密度信息获取模块,用于采集待识别人所处的自然环境下的雨或雪的下落信息,以获得待识别人正面的雨或雪的密度信息;
实际三维面部图像信息采集模块,用于采集待识别人的实际三维面部图像信息;
三维识别的初始位置信息确定模块,用于根据雨或雪的下落信息、待识别人声称的身份信息和待识别人的实际三维面部图像信息,确定三维识别的初始位置信息;
待识别人的三维面部信息识别模块,用于根据初始位置信息,识别待识别人的三维面部信息;
待识别人的实际身份信息确定模块,用于根据待识别人的面部信息,确定待识别人的实际身份信息。
进一步地,所述声音信号采集模块包括:
提示问题发出子模块,用于向待识别人给出提示问题的语音信息,获得待识别人在预定时间内的声音信息;
声纹获取子模块,用于获得待识别人的声音信息的声纹;
声纹信息比较子模块,用于将待识别人的声音信息的声纹与预设的声纹信息集合进行比较,根据比较结果确定待识别人声称的身份信息。
进一步地,所述提示问题为随机给出的提示问题。
进一步地,所述待识别人正面的雨或雪的密度信息获取模块包括:
声音信息来源确定子模块,用于确定待识别人的声音信息来源的空间位置;
第一降水等级采集子模块,被设置在待识别人脚下,用于采集雨或雪的降水等级;
栅格式遮挡子模块,用于当降水等级超过预设降水等级阈值时,在待识别人头顶上方进行栅格式遮挡,以便于将降落到待识别人头上的雨或雪的降水等级控制在预设降水等级阈值以下;
雨或雪的密度信息采集子模块,用于采集待识别人正面的雨或雪的密度信息。
进一步地,所述雨或雪的密度信息采集子模块包括:
多张待识别人的正面图像获取子模块,用于在待识别人与正面扫描摄像头之间采集多张待识别人的正面图像;
待识别人声称的面部正面图像确定子模块,用于根据待识别人声称的身份信息,确定待识别人声称的面部正面图像;
第一清晰度信息获取子模块,用于在预设分析区域内,确定所述多张待识别人的正面图像和所述待识别人声称的面部正面图像之间的清晰度信息cj,所述预设分析区域为以预设采集点为中心、竖直方向的、半径为预设长度r的区域,所述预设采集点的空间z方向坐标为待识别人头顶预定距离处,且当进行栅格式遮挡时,该预设距离小于进行栅格式遮挡时距离待识别人头顶的距离,该采集点的空间x方向和y方向坐标为所述声音信息来源的空间位置处的x坐标和y坐标,所述清晰度信息cj与待识别人的面部的各部位的生理特征为基础,j为面部的各部位的数量且j≥5。
进一步地,所述实际三维面部图像信息采集模块包括基于声音来源的图像采集子模块,用于采集待识别人在所述声音信息来源的空间位置处为图像中心的实际三维面部图像信息。
进一步地,所述三维识别的初始位置信息确定模块包括:
待识别人声称的面部正面图像确定子模块,用于根据待识别人声称的身份信息,确定待识别人声称的面部正面图像;
参考识别图像获取子模块,用于将所述清晰度信息叠加到所述面部正面图像上,获得参考识别图像;
参考识别图像比较子模块,用于将所述参考识别图像与待识别人的实际三维面部图像信息进行比较,确定实际三维面部图像信息中的面部区域;
匹配信息确定子模块,用于在所述实际三维面部图像信息中的面部区域中,确定所述实际三维面部图像信息与所述待识别人声称的面部正面图像之间的匹配信息,该匹配信息包括i个以面部的各部位的生理特征为基础的变形区域,其中i大于10;
第一变形区域确定子模块,用于当所述i个所述变形区域的变形系数分别为αi时,根据对以各个变形区域为中心、变形分析半径r为半径的多个邻域内的下式计算,确定计算得到的最小的值对应的、作为中心的变形区域amin,以及计算得到的最大的值对应的、作为中心的变形区域amax:
其中r为某个变形区域与在其周围的变形区域之间的距离,所述变形系数αi为以待识别人声称的面部正面图像的各部位的生理特征为基础的各个生理特征所在区域内,表示该生理特征的轮廓的像素在参考识别图像的相应位置出现的个数;
二次采集子模块,用于以t为周期,对所述变形区域amin中心所在处为图像中心的实际三维面部图像信息进行p次二次采集,从中提取二维面部图像,并在各周期内确定所述被提取的二维面部图像和所述待识别人声称的面部正面图像之间的清晰度信息
清晰度判别矩阵构建子模块,用于以各个二次采集期间得到的
方差计算子模块,用于计算所述清晰度判别矩阵的各列的方差dq,其中q为所述清晰度判别矩阵的列数;
清晰度判别矩阵处理子模块,用于去掉所述清晰度判别矩阵中方差dq最大的清晰度信息
第二变形区域确定子模块,用于对于所述经过处理的清晰度判别矩阵中的各行,依次进行下列二次处理:根据对以各个变形区域为中心、所述变形分析半径r为半径的多个邻域内的下式计算,确定计算得到的最小的值:
初始位置信息确定子模块,用于将该二次处理中得到的所述最小的值对应的作为中心的变形区域的几何中心作为初始位置,该几何中心的位置信息作为初始位置信息。
进一步地,所述降水等级按照气象学上一段时间内降水量为划分标准。
进一步地,所述系统还包括报警等级设置单元,用于根据所述待识别人声称的身份信息和待识别人的实际身份信息,确定门禁系统的安全防范等级。
本发明的有益效果是:
(1)能够提高雨中或雪中人脸识别的准确度;
(2)能够基于对雨或雪的多次分析,动态地确定而非静止地指定三维识别时的初始位置,相比现有技术中常用到的直接默认为“鼻尖”、“眉心”等位置具有更加广泛的适用性和可靠性,能够避免因为待识别人自身的生理缺陷造成识别失败。
附图说明
图1示出了根据本发明的基于三维扫描的门禁识别系统的组成框图。
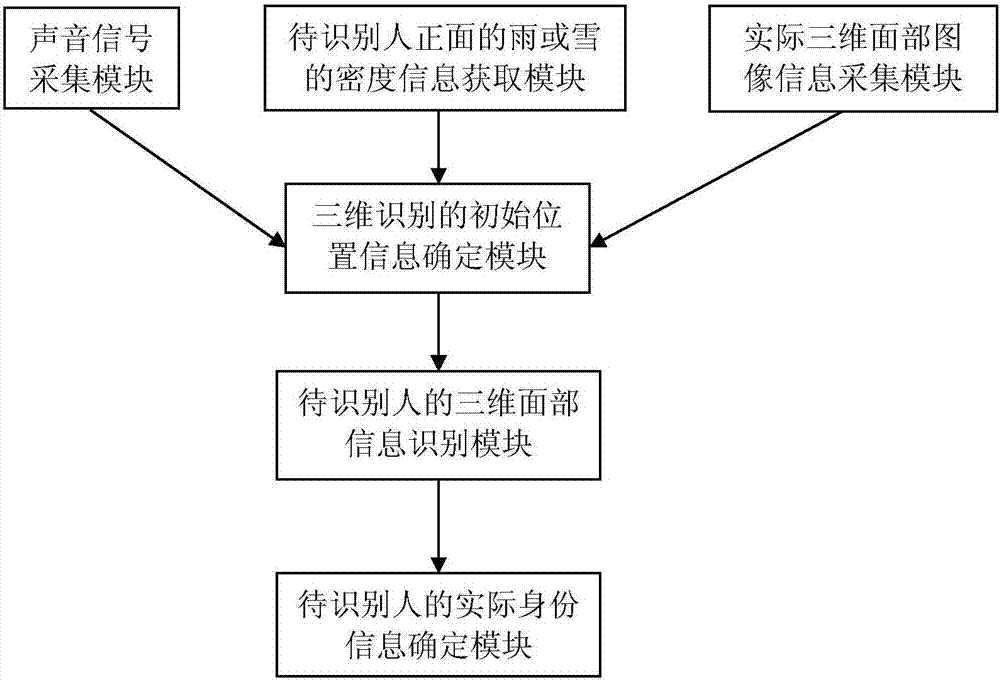
图2示出了根据本发明的基于多次扫描的三维人脸识别单元的组成框图。
图3示出了根据本发明的基于三维扫描的三维人脸识别单元相对应的识别方法的流程图。
具体实施方式
如图1所示,本发明提供了一种基于三维扫描的门禁识别系统,包括:基于多次扫描的三维人脸识别单元、数据库以及报警单元,所述基于多次扫描的三维人脸识别单元用于在待识别人处于雨或雪自然环境条件下时进行人脸识别,所述数据库存储能够通过所述三维人脸识别单元进行人脸识别的人员的声纹信息和面部正面图像,所述报警单元用于根据所述三维人脸识别单元进行报警。
如图2所示,所述基于多次扫描的三维人脸识别单元包括:
声音信号采集模块,用于采集待识别人的声音信号,并基于此声音信号获得待识别人声称的身份信息;
待识别人正面的雨或雪的密度信息获取模块,用于采集待识别人所处的自然环境下的雨或雪的下落信息,以获得待识别人正面的雨或雪的密度信息;
实际三维面部图像信息采集模块,用于采集待识别人的实际三维面部图像信息;
三维识别的初始位置信息确定模块,用于根据雨或雪的下落信息、待识别人声称的身份信息和待识别人的实际三维面部图像信息,确定三维识别的初始位置信息;
待识别人的三维面部信息识别模块,用于根据初始位置信息,识别待识别人的三维面部信息;
待识别人的实际身份信息确定模块,用于根据待识别人的面部信息,确定待识别人的实际身份信息。
所述声音信号采集模块包括:
提示问题发出子模块,用于向待识别人给出提示问题的语音信息,获得待识别人在预定时间内的声音信息;
声纹获取子模块,用于获得待识别人的声音信息的声纹;
声纹信息比较子模块,用于将待识别人的声音信息的声纹与预设的声纹信息集合进行比较,根据比较结果确定待识别人声称的身份信息。
所述提示问题为随机给出的提示问题。
所述待识别人正面的雨或雪的密度信息获取模块包括:
声音信息来源确定子模块,用于确定待识别人的声音信息来源的空间位置;
第一降水等级采集子模块,被设置在待识别人脚下,用于采集雨或雪的降水等级;
栅格式遮挡子模块,用于当降水等级超过预设降水等级阈值时,在待识别人头顶上方进行栅格式遮挡,以便于将降落到待识别人头上的雨或雪的降水等级控制在预设降水等级阈值以下;
雨或雪的密度信息采集子模块,用于采集待识别人正面的雨或雪的密度信息。
所述雨或雪的密度信息采集子模块包括:
多张待识别人的正面图像获取子模块,用于在待识别人与正面扫描摄像头之间采集多张待识别人的正面图像;
待识别人声称的面部正面图像确定子模块,用于根据待识别人声称的身份信息,确定待识别人声称的面部正面图像;
第一清晰度信息获取子模块,用于在预设分析区域内,确定所述多张待识别人的正面图像和所述待识别人声称的面部正面图像之间的清晰度信息cj,所述预设分析区域为以预设采集点为中心、竖直方向的、半径为预设长度r的区域,所述预设采集点的空间z方向坐标为待识别人头顶预定距离处,且当进行栅格式遮挡时,该预设距离小于进行栅格式遮挡时距离待识别人头顶的距离,该采集点的空间x方向和y方向坐标为所述声音信息来源的空间位置处的x坐标和y坐标,所述清晰度信息cj与待识别人的面部的各部位的生理特征为基础,j为面部的各部位的数量且j≥5。
所述实际三维面部图像信息采集模块包括基于声音来源的图像采集子模块,用于采集待识别人在所述声音信息来源的空间位置处为图像中心的实际三维面部图像信息。
所述三维识别的初始位置信息确定模块包括:
待识别人声称的面部正面图像确定子模块,用于根据待识别人声称的身份信息,确定待识别人声称的面部正面图像;
参考识别图像获取子模块,用于将所述清晰度信息叠加到所述面部正面图像上,获得参考识别图像;
参考识别图像比较子模块,用于将所述参考识别图像与待识别人的实际三维面部图像信息进行比较,确定实际三维面部图像信息中的面部区域;
匹配信息确定子模块,用于在所述实际三维面部图像信息中的面部区域中,确定所述实际三维面部图像信息与所述待识别人声称的面部正面图像之间的匹配信息,该匹配信息包括i个以面部的各部位的生理特征为基础的变形区域,其中i大于10;
第一变形区域确定子模块,用于当所述i个所述变形区域的变形系数分别为αi时,根据对以各个变形区域为中心、变形分析半径r为半径的多个邻域内的下式计算,确定计算得到的最小的值对应的、作为中心的变形区域amin,以及计算得到的最大的值对应的、作为中心的变形区域amax:
其中r为某个变形区域与在其周围的变形区域之间的距离,所述变形系数αi为以待识别人声称的面部正面图像的各部位的生理特征为基础的各个生理特征所在区域内,表示该生理特征的轮廓的像素在参考识别图像的相应位置出现的个数;
二次采集子模块,用于以t为周期,对所述变形区域amin中心所在处为图像中心的实际三维面部图像信息进行p次二次采集,从中提取二维面部图像,并在各周期内确定所述被提取的二维面部图像和所述待识别人声称的面部正面图像之间的清晰度信息
清晰度判别矩阵构建子模块,用于以各个二次采集期间得到的
方差计算子模块,用于计算所述清晰度判别矩阵的各列的方差dq,其中q为所述清晰度判别矩阵的列数;
清晰度判别矩阵处理子模块,用于去掉所述清晰度判别矩阵中方差dq最大的清晰度信息
第二变形区域确定子模块,用于对于所述经过处理的清晰度判别矩阵中的各行,依次进行下列二次处理:根据对以各个变形区域为中心、所述变形分析半径r为半径的多个邻域内的下式计算,确定计算得到的最小的值:
初始位置信息确定子模块,用于将该二次处理中得到的所述最小的值对应的作为中心的变形区域的几何中心作为初始位置,该几何中心的位置信息作为初始位置信息。
所述降水等级按照气象学上一段时间内降水量为划分标准。
所述系统还包括报警等级设置单元,用于根据所述待识别人声称的身份信息和待识别人的实际身份信息,确定门禁系统的安全防范等级。
如图3所示,本发明提供了一种基于三维扫描的门禁识别系统相对应的方法的工作流程图,包括:
(1)采集待识别人的声音信号,并基于此声音信号获得待识别人声称的身份信息;
(2)采集待识别人所处的自然环境下的雨或雪的下落信息,以获得待识别人正面的雨或雪的密度信息;
(3)采集待识别人的实际三维面部图像信息;
(4)根据雨或雪的下落信息、待识别人声称的身份信息和待识别人的实际三维面部图像信息,确定三维识别的初始位置信息;
(5)根据初始位置信息,识别待识别人的三维面部信息;
(6)根据待识别人的面部信息,确定待识别人的实际身份信息。
所述步骤(1)包括:
(11)向待识别人给出提示问题的语音信息,获得待识别人在预定时间内的声音信息;
(12)获得待识别人的声音信息的声纹;
(13)将待识别人的声音信息的声纹与预设的声纹信息集合进行比较,根据比较结果确定待识别人声称的身份信息。
所述提示问题为随机给出的提示问题。
步骤(2)包括:
(21)确定待识别人的声音信息来源的空间位置;
(22)在待识别人脚下采集雨或雪的降水等级;
(23)当降水等级超过预设降水等级阈值时,在待识别人头顶上方进行栅格式遮挡,以便于将降落到待识别人头上的雨或雪的降水等级控制在预设降水等级阈值以下;
(24)采集待识别人正面的雨或雪的密度信息。
所述步骤(24)包括:
(241)在待识别人与正面扫描摄像头之间采集多张待识别人的正面图像;
(242)根据待识别人声称的身份信息,确定待识别人声称的面部正面图像;
(243)在预设分析区域内,确定所述多张待识别人的正面图像和所述待识别人声称的面部正面图像之间的清晰度信息cj,所述预设分析区域为以预设采集点为中心、竖直方向的、半径为预设长度r的区域,所述预设采集点的空间z方向坐标为待识别人头顶预定距离处,且当进行栅格式遮挡时,该预设距离小于进行栅格式遮挡时距离待识别人头顶的距离,该采集点的空间x方向和y方向坐标为所述声音信息来源的空间位置处的x坐标和y坐标,所述清晰度信息cj与待识别人的面部的各部位的生理特征为基础,j为面部的各部位的数量且j≥5。
所述步骤(3)包括采集待识别人在所述声音信息来源的空间位置处为图像中心的实际三维面部图像信息。
所述步骤(4)包括:
(411)根据待识别人声称的身份信息,确定待识别人声称的面部正面图像;
(412)将所述清晰度信息叠加到所述面部正面图像上,获得参考识别图像;
(413)将所述参考识别图像与待识别人的实际三维面部图像信息进行比较,确定实际三维面部图像信息中的面部区域;
(414)在所述实际三维面部图像信息中的面部区域中,确定所述实际三维面部图像信息与所述待识别人声称的面部正面图像之间的匹配信息,该匹配信息包括i个以面部的各部位的生理特征为基础的变形区域,其中i大于10;
(415)设所述i个所述变形区域的变形系数分别为αi,根据对以各个变形区域为中心、变形分析半径r为半径的多个邻域内的下式计算,确定计算得到的最小的值对应的、作为中心的变形区域amin,以及计算得到的最大的值对应的、作为中心的变形区域amax:
其中r为某个变形区域与在其周围的变形区域之间的距离,所述变形系数αi为以待识别人声称的面部正面图像的各部位的生理特征为基础的各个生理特征所在区域内,表示该生理特征的轮廓的像素在参考识别图像的相应位置出现的个数;
(416)以t为周期,对所述变形区域amin中心所在处为图像中心的实际三维面部图像信息进行p次二次采集,从中提取二维面部图像,并在各周期内确定所述被提取的二维面部图像和所述待识别人声称的面部正面图像之间的清晰度信息
(417)以各个二次采集期间得到的
(418)计算所述清晰度判别矩阵的各列的方差dq,其中q为所述清晰度判别矩阵的列数;
(419)去掉所述清晰度判别矩阵中方差dq最大的清晰度信息
(420)对于所述经过处理的清晰度判别矩阵中的各行,依次进行下列二次处理:根据对以各个变形区域为中心、所述变形分析半径r为半径的多个邻域内的下式计算,确定计算得到的最小的值:
(421)将该二次处理中得到的所述最小的值对应的作为中心的变形区域的几何中心作为初始位置,该几何中心的位置信息作为初始位置信息。
所述降水等级按照气象学上一段时间内降水量为划分标准。
所述方法还包括根据所述待识别人声称的身份信息和待识别人的实际身份信息,确定门禁系统的安全防范等级。
本申请中未提及的三维人脸识别具体步骤是在确定了上述初始位置信息以后,可以利用现有技术中的各种模型和算法进行的,并非本申请的主要技术方案,且不影响本申请的实施,在此不再赘述。
以上对于本发明的较佳实施例所作的叙述是为阐明的目的,而无意限定本发明精确地为所揭露的形式,基于以上的教导或从本发明的实施例学习而作修改或变化是可能的,实施例是为解说本发明的原理以及让所属领域的技术人员以各种实施例利用本发明在实际应用上而选择及叙述,本发明的技术思想企图由权利要求及其均等来决定。
- 还没有人留言评论。精彩留言会获得点赞!