多个并发语音助理的利记博彩app
背景技术:
1、人类可以利用交互式软件应用参与人类与计算机对话,该交互式软件应用在本文中被称为“自动化助理”(也被称为“数字智能体”、“交互式个人助理”、“智能个人助理”、“助理应用”、“交谈智能体(agent)”等)。例如,人类(当他们与自动化助理交互时可以被称为“用户”)可以使用口头自然语言输入(即,话语)来向自动化助理提供命令和/或请求,该口头自然语言输入在一些情况下可以通过提供文本(例如,键入的)自然语言输入和/或通过触摸和/或无话语的物理运动(例如,手部手势、眼睛注视、面部运动等)而被转换成文本并且然后进行处理。自动化助理通过以下方式来对请求作出响应:提供响应式用户接口输出(例如,听觉和/或视觉用户接口输出),控制一个或多个智能装置和/或控制实现自动化助理的装置的一个或多个功能(例如,控制该装置的其他应用)。
2、如上文所提及,许多自动化助理被配置为经由口头话语来与其进行交互。为了维护用户隐私和/或节省资源,自动化助理避免基于音频数据中存在的所有口头话语来实行(perform)一个或多个自动化助理功能,该音频数据是经由(至少部分地)实现自动化助理的客户端装置的麦克风检测的。相反,基于口头话语的某些处理仅响应于确定某些条件存在而发生。
3、例如,许多包括自动化助理和/或与自动化助理接口的客户端装置都包括热词检测模型。当这种客户端装置的麦克风未停用时,客户端装置可以使用热词检测模型来连续处理经由麦克风检测的音频数据,以生成指示是否存在一个或多个热词(包括多词短语)的预测的输出,该一个或多个热词诸如“hey assistant (嘿,助理)”、“ok assistant (好的,助理)”和/或“assistant (助理)”。当预测的输出指示热词存在时,在阈值时间量内跟随(并且可选地被确定为包括语音活动)的任何音频数据都可以由诸如言语辨识组件、语音活动检测组件等的一个或多个装置上和/或远程自动化助理组件处理。进一步地,可以使用自然语言理解引擎来对(来自言语辨识组件的)辨识的文本进行处理,和/或可以基于自然语言理解引擎输出来实行动作。动作可以包括例如生成并提供响应和/或控制一个或多个应用和/或智能装置。然而,当预测的输出指示热词不存在时,对应音频数据将被丢弃而不进行任何进一步处理,从而节省资源并保护用户隐私。
4、不同的自动化助理可以使用不同的热词来调用并且可以支持不同的能力。例如,第一自动化助理可以由热词“hey assistant”调用,并且可以能够处置多种一般任务,包括消息传递任务、搜索任务、电话呼叫任务等。第二自动化助理可以由热词“computer (计算机)”调用,并且也可以能够处置多种一般任务,包括消息传递任务、搜索任务、电话呼叫任务等。第三自动化助理可以由热词“hello car (你好,汽车)”调用,并且可以能够处置多种车辆相关任务,诸如改变气候控制设置和改变娱乐系统设置。
5、实现两个或更多个不同的自动化助理(诸如上文示例中的三个自动化助理)的客户端装置可以提供允许选择特定自动化助理的配置选项。然而,用户可能无法利用除所选择的自动化助理之外的自动化助理。改变所选择的自动化助理可能需要用户定位并进入设置菜单,定位用以选择不同的自动化助理的选项,以及指定新的自动化助理,以便利用新的自动化助理。附加地,用户可能不知道哪个自动化助理是活动的,并且可能尝试实行活动的自动化助理不支持的任务,这可能导致负面的用户体验并且可能浪费网络和/或计算资源,因为自动化助理尝试处置不受支持的任务并且未能履行请求。
技术实现思路
1、本文所公开的一些实现方式涉及支持多个并发语音助理。如本文更详细地描述的,两个或更多个自动化助理可以监听多个热词。用户可以能够通过说出与特定自动化助理相关联的热词来选择特定自动化助理以处置特定请求。例如,第一自动化助理可以监听第一个热词,并且第二自动化助理可以监听第二个热词。在自动化助理中的一个自动化助理发起会话时,可以向发起会话的自动化助理提供对麦克风和扬声器的控制,并且可以阻止其他自动化助理访问发起会话的自动化助理的麦克风、扬声器和输出音频数据。
2、在一个示例中,车载计算机可以支持第一自动化助理,该第一自动化助理可以由热词“hey assistant”调用,并且可以能够处置多种一般任务,包括消息传递任务、搜索任务、电话呼叫任务等。车载计算机还可以支持第二自动化助理,该第二自动化助理可以由热词“computer”调用,并且也可以能够处置多种一般任务,包括消息传递任务、搜索任务、电话呼叫任务等。车载计算机还可以支持第三自动化助理,该第三自动化助理可以由热词“hello car”调用,并且可以能够处置多种车辆相关任务,诸如改变气候控制设置和改变娱乐系统设置。
3、在此示例中,在不改变任何配置设置的情况下,用户可以能够通过说出“heyassistant, tell sarah i will arrive in ten minutes (嘿,助理,告诉莎拉我十分钟后到)”来调用与车载计算机上的第一自动化助理的第一会话以发送文本消息,并且然后在第一会话结束之后,通过说出“hello car, lower cabin temperature (你好,汽车,降低车舱温度)”来调用与车载计算机上的第三自动化助理的第二会话以改变气候控制设置。在一些实现方式中,可以提供可视化,该可视化指示哪个自动化助理是活动的(例如,由热词触发)和/或从麦克风接收音频数据。通过允许用户在不改变配置设置的情况下利用任何受支持的自动化助理,可以避免在用户尝试利用除所选择的自动化助理之外的自动化助理时的失败,从而导致改善的用户体验和对网络和/或计算资源的更有效利用。
4、在该示例中,在与第一自动化助理的第一会话期间,第三自动化助理可以生成通知“vehicle maintenance due in 500 miles (500英里后需进行车辆维护)”。然而,由于与车辆维护通知相关联的较低优先级,车载计算机可以阻止第三自动化助理中断第一会话以在车载计算机的显示器上呈现该通知。此通知可以被暂时抑制,直到第一会话结束。一旦第一会话已经结束,就可以呈现车辆维护通知。
5、继续该示例,在与第三自动化助理的第二会话期间,第一自动化助理可以生成导航通知“turn right in 200 feet (200英尺后右转)”。由于与导航通知相关联的较高优先级,第二会话可以被中断以呈现导航通知。
6、在一些实现方式中,当可访问性服务是活动的,两个或更多个自动化助理可以并发地监听多个热词。在自动化助理中的一个自动化助理发起会话时,可以向发起会话的自动化助理提供对麦克风和扬声器的控制,并且可以阻止其他自动化助理访问发起会话的自动化助理的麦克风、扬声器和输出音频数据。可访问性服务可以在自动化助理会话期间保持活动,并且自动化助理可以支持与可访问性相关的任务。
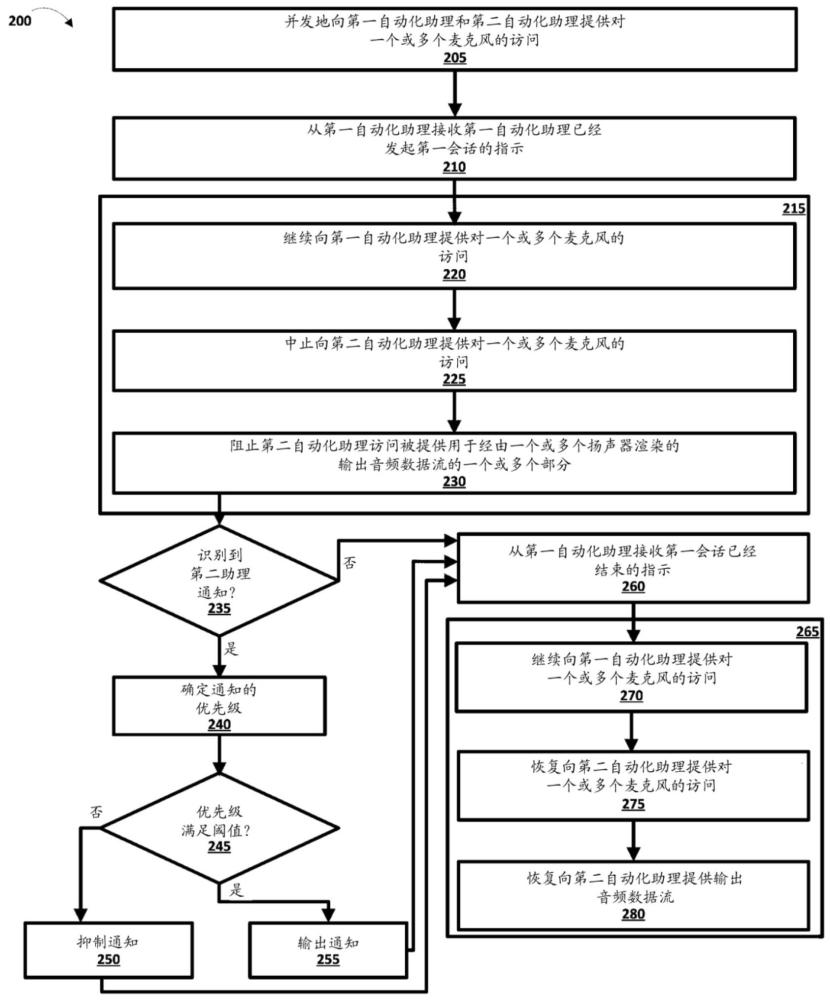
7、在各种实现方式中,一种由一个或多个处理器实现的方法可以包括:并发地向第一自动化助理和第二自动化助理提供对一个或多个麦克风的访问;从第一自动化助理接收第一自动化助理已经发起第一会话的指示;响应于从第一自动化助理接收到第一自动化助理已经发起第一会话的指示:继续向第一自动化助理提供对一个或多个麦克风的访问;中止向第二自动化助理提供对一个或多个麦克风的访问;以及阻止第二自动化助理访问被提供用于经由一个或多个扬声器渲染的输出音频数据流的一个或多个部分,该一个或多个部分包括第一自动化助理的输出音频数据;从第一自动化助理接收第一会话已经结束的指示;以及响应于从第一自动化助理接收到第一会话已经结束的指示:继续向第一自动化助理提供对一个或多个麦克风的访问;恢复向第二自动化助理提供对一个或多个麦克风的访问;以及恢复向第二自动化助理提供输出音频数据流。第二自动化助理可以在噪声消除中使用输出音频数据流。
8、在一些实现方式中,阻止第二自动化助理访问输出音频数据流的一个或多个部分包括:当第一自动化助理在第一会话期间提供听觉输出时,阻止第二自动化助理访问输出音频数据流。
9、在一些实现方式中,方法可以进一步包括:确定已经发起电话呼叫;响应于确定已经发起电话呼叫,中止向第一自动化助理和第二自动化助理提供对一个或多个麦克风的访问;确定电话呼叫已经结束;以及响应于确定电话呼叫已经结束,恢复向第一自动化助理和第二自动化助理提供对一个或多个麦克风的访问。
10、在一些实现方式中,方法可以进一步包括:在从第一自动化助理接收到第一自动化助理已经发起第一会话的指示之后,并且在从第一自动化助理接收到第一会话已经结束的指示之前:识别来自第二自动化助理的要输出的通知;确定通知的优先级;以及响应于通知的优先级满足阈值,在从第一自动化助理接收到第一会话已经结束的指示之前,输出通知。
11、在一些实现方式中,方法可以进一步包括:在缓冲器中缓冲输出音频数据流的包括第一自动化助理的输出音频数据的一个或多个部分;在输出来自第二自动化助理的通知的同时暂停输出音频数据流的包括第一自动化助理的输出音频数据的一个或多个部分的呈现;以及在输出来自第二自动化助理的通知之后,从缓冲器恢复输出音频数据流的包括第一自动化助理的输出音频数据的一个或多个部分的呈现。
12、在一些实现方式中,方法可以进一步包括:在从第一自动化助理接收到第一自动化助理已经发起第一会话的指示之后,并且在从第一自动化助理接收到第一会话已经结束的指示之前:识别来自第二自动化助理的要输出的通知;确定通知的优先级;以及响应于通知的优先级不满足阈值,抑制通知,直到从第一自动化助理接收到第一会话已经结束的指示。
13、在一些实现方式中,方法可以进一步包括:在缓冲器中缓冲通知;以及响应于从第一自动化助理接收到第一会话已经结束的指示,从缓冲器输出通知。
14、在一些实现方式中,方法可以进一步包括:经由图形用户接口接收用户接口输入,该用户接口输入是在第二自动化助理上发起第二会话的请求;响应于接收到用户接口输入:致使第二自动化助理发起第二会话;继续向第二自动化助理提供对一个或多个麦克风的访问;中止向第一自动化助理提供对一个或多个麦克风的访问;以及阻止第一自动化助理访问第二自动化助理的输出音频数据。
15、在一些实现方式中,方法可以进一步包括:在从第一自动化助理接收到第一自动化助理已经发起第一会话的指示之后,并且在从第一自动化助理接收到第一会话已经结束的指示之前:在图形用户接口上显示正在向第一自动化助理提供对一个或多个麦克风的访问的视觉指示。
16、在一些实现方式中,方法可以进一步包括:在从第一自动化助理接收到第一自动化助理已经发起第一会话的指示之后:提供正在向第一自动化助理提供对一个或多个麦克风的访问的听觉指示。
17、在一些实现方式中,方法可以进一步包括:响应于从第一自动化助理接收到第一自动化助理已经发起第一会话的指示:重新指派物理按钮,该物理按钮在激活时被配置为发起第二自动化助理的会话,以代替发起第一自动化助理的会话。
18、在一些附加或替代实现方式中,一种计算机程序产品可以包括一个或多个计算机可读存储介质,该一个或多个计算机可读存储介质具有共同存储在一个或多个计算机可读存储介质上的程序指令。程序指令可以可执行以:经由一个或多个麦克风接收捕获用户的第一口头话语的第一音频数据;并发地向第一自动化助理的第一热词检测器和第二自动化助理的第二热词检测器提供第一音频数据;接收第一置信度分数和第二置信度分数,该第一置信度分数基于由第一自动化助理的第一热词检测器确定的在第一音频数据中存在第一热词的概率,该第二置信度分数基于由第二自动化助理的第二热词检测器确定的在第一音频数据中存在第二热词的概率;基于第一置信度分数和第二置信度分数:向第一自动化助理提供经由一个或多个麦克风接收的第二音频数据,该第二音频数据捕获跟随用户的第一口头话语的用户的第二口头话语;提供正在向第一自动化助理提供来自一个或多个麦克风的音频的指示;以及阻止第二自动化助理获得第二音频数据。
19、在一些实现方式中,第一热词检测器使用第一热词检测器的一个或多个机器学习模型来处理第一音频数据以生成第一预测的输出,该第一预测的输出指示在第一音频数据中存在第一热词的概率;并且第二热词检测器使用第二热词检测器的一个或多个机器学习模型来处理第一音频数据以生成第二预测的输出,该第二预测的输出指示在第一音频数据中存在第二热词的概率。
20、在一些实现方式中,第一置信度分数高于第二置信度分数;并且第一置信度分数满足阈值。在一些实现方式中,正在向第一自动化助理提供来自一个或多个麦克风的音频的指示是在图形用户接口上显示的视觉指示、或听觉指示。
21、在一些附加或替代实现方式中,一种系统可以包括处理器、计算机可读存储器、一个或多个计算机可读存储介质,以及共同存储在一个或多个计算机可读存储介质上的程序指令。程序指令可以可执行以:并发地向第一自动化助理和第二自动化助理提供对一个或多个麦克风的访问;从第一自动化助理接收第一自动化助理已经发起第一会话的指示;响应于从第一自动化助理接收到第一自动化助理已经发起第一会话的指示:继续向第一自动化助理提供对一个或多个麦克风的访问;中止向第二自动化助理提供对一个或多个麦克风的访问;以及阻止第二自动化助理访问被提供用于经由一个或多个扬声器渲染的输出音频数据流的一个或多个部分,该一个或多个部分包括第一自动化助理的输出音频数据;从第一自动化助理接收第一会话已经结束的指示;以及响应于从第一自动化助理接收到第一会话已经结束的指示:继续向第一自动化助理提供对一个或多个麦克风的访问;恢复向第二自动化助理提供对一个或多个麦克风的访问;以及恢复向第二自动化助理提供输出音频数据流,其中第二自动化助理在噪声消除中使用输出音频数据流。
22、提供以上描述作为对本公开的一些实现方式的概述。下文更详细地描述那些实现方式以及其他实现方式的进一步描述。
23、各种实现方式可以包括存储指令的非暂时性计算机可读存储介质,该指令可由一个或多个处理器(例如,中央处理单元(cpu)、图形处理单元(gpu)、数字信号处理器(dsp)和/或张量处理单元(tpu))执行以实行诸如本文所述的方法中的一种或多种的方法。其他实现方式可以包括自动化助理客户端装置(例如,至少包括用于与基于云的自动化助理组件接口的自动化助理接口的客户端装置),该自动化助理客户端装置包括可操作以执行所存储的指令以实行诸如本文所述的方法中的一种或多种的方法的处理器。又其他实现方式可以包括一个或多个服务器的系统,该一个或多个服务器包括一个或多个处理器,该一个或多个处理器可操作以执行所存储的指令以实行诸如本文所述的方法中的一种或多种的方法。
- 还没有人留言评论。精彩留言会获得点赞!