一种基于深度Q学习策略的手写数字识别方法与流程
本发明属于人工智能和模式识别领域,涉及一种基于深度q学习策略的手写数字识别方法,是一种深度学习和强化学习相结合的创新性应用技术。
背景技术:
近年来,随着人工智能技术和模式识别技术的不断发展,手写数字识别被广泛的应用于邮政邮件分拣、医疗数据处理以及其他计算视觉等领域。由于带有大量不同的手写点和笔迹类别,手写数字识别是一项具有挑战性的工作。现阶段,有很多模式识别方法被应用于手写数字识别中,例如基于深度学习模型的分类方法、人工神经网络方法以及支持向量机分类器等。在这些现有的识别方法中,基于深度学习模型的深度信念网络具有相对较高的识别精度,因为深度学习模型具有像人脑分层处理信息一样的数据处理能力。
手写数字识别要求识别方法同时具有较强的特征提取能力和识别决策能力。尽管深度信念网络具有较强的分层特征提取能力,但是其识别精度仍然无法满足人们的要求,并且识别时间较长。为了获得决策能力较强的手写数字识别方法,人们开始研究机器人理论中的强化学习,并模仿具有较强决策能力的alphago。通过研究人们发现,alphago采用的学习方法主要是无监督的深层循环学习,即“自己跟自己学习”,其有监督学习部分相对较少,所以强化学习也无法独立完成手写数字高精度的识别任务。从宏观角度看,在高级人工智能领域里,特征提取能力和识别决策能力都是衡量一个人工智能体的重要指标。然而,直接通过学习高维输入(如海量的手写数字图像)去控制智能体,对强化学习来说是一个长期的挑战,alphago同样也面临此类问题。众所周知,强化学习在决策规划的理论和算法方面已经取得了显著的成果。但是,绝大部分成功的强化学习应用案例均依赖于人工选取数据特征,而学习的效果严重地取决于特征选取的质量和准确度。
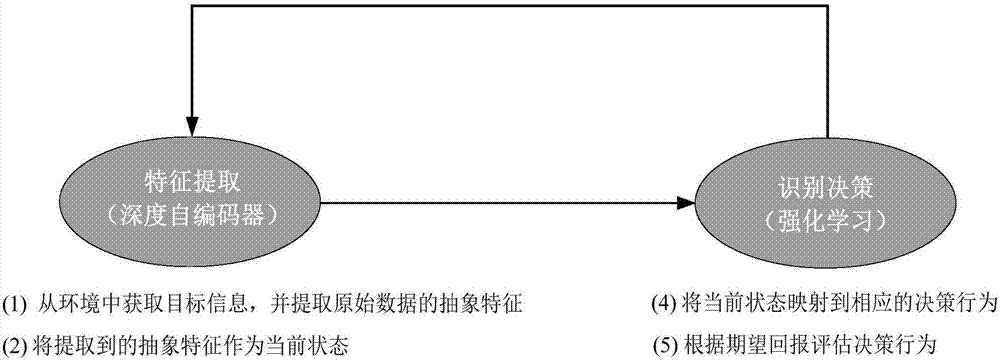
深度q学习策略是一种基于深度强化学习思想(如图1所示)建立起来的分类识别模型,其结合了深度学习强大的特征提取能力和强化学习强大的决策能力。基于现有手写数字识别方法存在的不足以及识别任务的特点得知,深度q学习策略能够充分地满足了手写数字识别对识别方法的要求,并且能够快速完成高精度的识别任务。因此,深度q学习策略是一种高效的手写数字识别技术。
技术实现要素:
1.本发明需要且能够解决的技术问题
针对现有模式识别方法难以满足目前人们对手写数字识别精度要求越来越高的问题,本发明结合深度强化学习理论,提出一种基于深度q学习策略的手写数字识别方法。该方法能够实现对手写数字的快速且高精度的识别。
2.本发明具体的技术方案
一种基于深度强化学习策略的手写数字识别方法,其特征在于包括以下步骤:
步骤a:根据深度学习模型分层特征学习的特点,顺序叠加若干个受限玻尔兹曼机(rbm)构造深度自编码器(dae),并利用dae对手写数字图像进行分层抽象与关键特征提取;其中,dae的特征学习是通过逐层训练每个rbm来完成的。
步骤b:计算dae的最后一个rbm隐含层状态与原始输入图像数据的重构误差re-error,并设置基于重构误差的特征提取衡量标准;然后所设置的特征提取衡量标准确定最终提取到的特征。
步骤c:将最终确定提取到的特征f=[f1,f2,…,fl]作为强化学习中q学习算法的初始状态,手写数字的10种识别结果作为q学习算法的输出状态,然后进行q算法寻优决策迭代。
步骤d:通过步骤d构造基于q学习算法的深度信念网络(q-dbn),q-dbn通过最大化q函数值来获取最优决策行为集
3.与现有技术相比,本发明具有以下优点:
1)本发明针对传统手写数字识别方法识别精度低且耗时长的问题,提出了一种基于深度q学习策略的手写数字识别方法,如图2和图3所示。通过利用深度自编码器和q学习算法相结合的方法,将深度学习的数据降维技术用于特征提取过程中,然后再利用q学习算法来处理所提取到的特征,进而做出识别和决策。这种基于深度q学习策略的识别方法能够充分的利用深度学习强大的特征提取能力和强化学习强大的决策能力,并较快地做出高精度的识别。满足了实际应用中对手写数字识别精度和速度的要求。
2)本发明第一次将深度强化理论和方法应用到手写数字识别中,属于人工智能在模式识别领域中的前沿探索性应用方法。该方法在手写数字识别中的成功应用,对于推动人工智能方法的发展及其在各个领域中的应用具有非常重要的意义。
附图说明
图1深度学习和强化学习结合框架
图2深度自编码器结构图
图3深度q学习策略原理图
图4深度自编码器与其他方法的降噪效果对比图
图5深度自编码器与其他方法的降噪重构误差对比图
图6深度自编码器与其他方法的降噪信噪比对比图
图7深度自编码器分层抽象特征提取过程
图8深度q学习策略奖励信号积累值
图9深度q学习策略对5000个手写数字图像的错误识别结果
具体实施方式
在本发明提供了一种基于深度q学习策略的手写数字识别方法,具体实施方法包括:
1.手写数字图像降噪
本发明提供的一个实施例中,手写数字图像来自mnist手写数据库,该数据库拥有60000个训练图像和10000个测试图像,每个数字都用很多不同的手写方式来显示,每个图像为28×28的像素,像素取值为0~1。从mnist数据库中随机选取1000个手写数字图像作为训练样本,100个带有10%背景噪音的手写数字图像作为测试样本。1000个训练样本本分成10批,每批包含100个图像,重构误差re-error和信噪比作为评价降噪效果的指标。
1)根据rbm的极大团构造原理,rbm的能量函数定义为
其中,v是可视层状态向量,h是隐含层状态向量,θ={w,a,b},w是可视层和隐含层之间的
连接权值矩阵,a和b分别是可视层和隐含层节点的偏置向量;vi和hj分别是可视层第i个神
经元和隐含层第j个神经元的状态值,wij表示可视层第i个神经元与隐含层第j个神经元之
间的连接权值,ai和bj分别是可视层第i个神经元和隐含层第j个神经元的偏置,m和n分别
是可视层神经元和隐含层神经元个数;相应的条件概率为
式中,σ(·)是一个sigmoid函数,p(hj=1/v;θ)表示在θ和v已知的条件下hj=1的概率,p(vi=1/h;θ)表示在θ和h已知的条件下vi=1的概率;利用能量函数得到rbm的联合分布为
p(v,h)∝e-ε(v,h/θ)(4)
权值更新公式为
其中,τ是rbm的迭代步数,θ(τ)和θ(τ+1)分别是第τ次和第τ+1次迭代后的参数值,r是学习率,其取值范围是0<r<1。
本实施例中此步骤涉及rbm的固有参数设置情况为:隐含层神经元个数l=100,学习率r=0.5,训练迭代次数τ=50,吉布斯采样次数λ=2。
2)定义重构误差公式为
其中,ns和np分别表示训练样本个数和手写数字图像的像素点个数,vij和v′ij分别表示图片像素点原始值和重构值;
根据步骤1)中对rbm的训练方法,顺序训练ade中叠加的若干个rbm,即上一个rbm的输出作为下一个rbm的输入。然后根据如公式(7)所示的基于重构误差的特征提取标准所设置的特征提取标准来确定最终提取到的特征。
re-error≤re-error0(7)
即如果重构误差小于或等于所设置的重构误差阈值re-error0,那么将提取dae的最后一个rbm隐含层状态作为最终特征f=[f1,f2,…,fl],其中,f1,f2,…,fl分别表示最后一个rbm隐含层中各个神经元的状态值,l是隐含层神经元个数;否则,增加rbm的无监督迭代次数并继续提取特征,其中,重构误差阈值的取值范围为:0.01<re-error0<0.05。
本实施例中此步骤涉及ade的固有参数设置情况为:rbm个数l=3,重构误差阈值re-error0=0.02。
图4给出了深度自编码器和其他两种方法的降噪效果对比图,图5深度自编码器与其他方法的降噪重构误差对比图,图6深度自编码器与其他方法的降噪信噪比对比图。由此得知,深度自编码器在特征感知和提取方面效果较好。
2.手写数字识别
从mnist数据库中随机选取10000个带有标签的手写数字图像作为训练样本,5000个手写数字图像作为特使样本。10000个训练样本本分成100批,每批包含100个图像。
将最终确定提取到的特征f=[f1,f2,…,fl]和手写数字的10种识别结果s=[s1=0,s2=1,…,s10=9]分别作为q学习算法的初始状态和输出状态,从初始状态到输出状态的决策行集合为
a=[a1:f=0,a2:f=1,…,a10:f=9](8)
基于奖励信号的q函数为
公式(9)表示在一次识别过程中的累积q函数值;式中,d是手写数字识别的结果个数,d是对d的随机选取,
q函数的迭代更新过程为
qt+1(f,a)=(1-ηt(f,a))qt(f,a)+ηt(f,a)(g(f,a,sd)+γmaxqt(sd,a′))(11)
式中,ηt(f,a)是状态-行为对(f,a)在第t次迭代时的学习步长。
本实施例中此步骤涉及q学习算法的固有参数设置情况为:折扣因子γ=0.5,状态-行为对(f,a)在第t次q函数值迭代时的学习步长ηt(f,a)=0.6。
图7给出了深度自编码器分层抽象特征提取过程和特征图像,图8给出了深度q学习策略奖励信号积累值,由此得知,深度q学习策略在处理抽象特征的过程中能够实现算法的收敛。图9给出了深度q学习策略对5000个手写数字图像的错误识别结果,结果显示,5000个测试样本中只有41个识别错误。基于深度q学习策略的手写数字识别效果与其他现有方法识别效果的对比结果如表1所示。
表1基于深度q学习策略的手写数字识别结果与其他方法的结果对比
- 还没有人留言评论。精彩留言会获得点赞!