差分并行HCMAC神经网络双侧变流量地源热泵系统功耗预测方法与流程
本发明涉及一种差分并行hcmac神经网络双侧变流量地源热泵系统功耗预测方法。
背景技术:
利用浅层地热能的地源热泵技术在我们国家得到了快速的发展,目前地源热泵的项目规模在全球已处于领先地位。然而,设计部门在地源热泵系统设计时通常按照最大负荷设计,导致地源热泵系统大部分时间工作在部分负荷状态。
随着地源热泵机组工艺技术的提高,热泵机组一定范围内的变流量运行成为可能,蒸发器和冷凝器的流量可在设计流量的30%-130%变化。螺杆热泵机组通过自身的滑阀控制可实现冷热负荷10%~100%的无极调节。这些技术的发展使得地源热泵系统循环泵变频变流量控制成为可能。
目前,变频泵的控制方法主要包括定温差控制和定压差控制,但上述控制方法不能实现在当前负荷下循环泵的最优控制。通常,当循环泵频率降低时,循环泵的功耗会降低,但同时会导致热泵机组功耗的增大。要实现循环泵的优化控制,建立地源热泵系统的功耗预测模型是非常重要的。目前地源热泵系统建模方法主要采用物理机理建模方法,但在建模过程中有些参数很难确定,给建模及模型精度带来困难。
随着信息技术的发展,在地源热泵系统的运行过程中会产生大量的数据,如何根据采集的地源热泵系统有效数据建立地源热泵系统功耗模型未见报道。目前在地源热泵变频控制实际应用中,大部分采取负荷侧变频控制,而地源侧循环泵通常工作在定频模式。从大量的工程实测数据可以看到,地源侧的供回水温差基本在2-3℃之间,即地源侧工作在小温差大流量工况,对节能不利。若负荷侧循环泵和地源侧循环泵根据用户负荷的变化同时变频,即地源热泵系统工作在双侧变流量状态,地源热泵系统将有更大的节能空间。
技术实现要素:
本发明为了解决上述问题,提出了一种差分并行hcmac神经网络双侧变流量地源热泵系统功耗预测方法,本发明根据地源热泵系统功耗样本数据的特点提出的差分并行hcmac(dphcmac,differentialparallelhcmac)神经网络学习算法,能够提高地源热泵系统功耗的预测精度。
为了实现上述目的,本发明采用如下技术方案:
一种差分并行hcmac神经网络双侧变流量地源热泵系统功耗预测方法,包括以下步骤:
(1)确定地源热泵系统功耗预测模型的输入;
(2)根据样本数据的特点将样本数据空间划分为多个子空间,确定每个子空间输出的参考值,得到每个子空间输出的差分,确定每个hcmac子模型的量化级数及神经网络网格划分。
(3)根据样本学习数据学习dphcmac每个子模型神经网络权度系数。
(4)将待预测样本输入到构建的dphcmac神经网络,得到地源热泵系统功耗预测结果。
进一步的,所述步骤(1)中,地源热泵系统功耗与地源侧循环泵频率、负荷侧循环泵频率和用户当前负荷有关,最终确定地源热泵系统功耗预测模型的输入为地源侧循环泵频率、负荷侧循环泵频率和用户当前负荷。
所述步骤(2)中,子空间按照输入的用户负荷区间划分,每个子空间的地源侧循环泵频率区间和负荷侧循环泵频率区间保持一致。
所述步骤(2)中,dphcmac神经网络结构由8个子hcmac模型并联组成,将学习样本数据空间划分为8个子空间。
所述步骤(2)中,对每个输入子空间做归一化处理,根据每个子空间的输出空间,确定每个输出子空间的参考值,计算每个输出子空间的输出差分值,形成新的输出差分子空间。
所述步骤(2)中,每个子空间的神经网络网格划分相同,地源侧循环泵频率、负荷侧循环泵频率和用户当前负荷取相同的量化级数。
所述步骤(2)中,将神经网络网格的交点编码形成节点向量,各个神经网络子模型的节点向量相同,同时建立神经网络节点权度向量,初始情况下,神经网络每个节点的权度为0。
所述步骤(3)中,构建神经网络基函数,在超闭球上定义高斯基函数,若超闭球外的神经网络节点没被选中,基函数值为0;超闭球内的神经网络节点被选中,且距离超闭球的中心越近,基函数的值越大。
所述步骤(3)中,根据当前的输入计算每个神经网络节点的基函数值,得到基函数向量,每个子模型确定一个基函数子矩阵。每个子模型的神经网络网格划分、神经网络节点向量、超闭球半径和标准偏差均相同,通过每个子空间的学习样本得到不同子模型的神经网络权度向量。
所述步骤(3)中,子模型hcmac神经网络的输出为所有激活节点基函数和权度系数乘积的代数和。
所述步骤(3)中,采用c-l算法进行hcmac子模型神经网络学习。
所述步骤(4)中,根据输入数据中用户负荷的值确定输入子空间xk,同时确定神经网络子模型hcmack。
所述步骤(4)中,对输入数据归一化处理,按照建立的dhcmac神经网络子模型hcmack计算子模型的输出。
所述步骤(4)中,根据子模型hcmac神经网络输出进行差分逆变换得到dphcmac神经网络输出。
进一步的,具体步骤包括:根据子空间学习样本个数确定第一层循环次数,根据神经网络节点向量长度确定第二层循环次数,计算输入和每个神经网络节点的欧式距离,确定包含在超闭球内的神经网络节点,形成每个输入的基函数向量,计算子空间每个输入的基函数向量,最终形成基函数矩阵,确定神经网络循环学习次数,并计算神经网络输出;根据实际值和神经网络输出值之间的偏差学习神经网络子模型hcmack的权度系数向量,直到学习次数到,学习结束。
与现有技术相比,本发明的有益效果为:
本发明提出的dphcmac神经网络,按照双侧变流量地源热泵系统功耗学习数据的特点,将学习空间划分为多个子空间,确定每个子空间输出的参考值,得到每个子空间输出的差分。将对hcmac神经网络输出的学习改为差分学习,使得学习数据输出的论域区间和数值大大降低,与常规hcmac模型比较,显著提高了模型的学习精度和测试精度,可以实现双侧变流量地源热泵系统功耗pz的精确预测。
附图说明
构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。
图1是本发明的地源热泵系统功耗结构图;
图2是本发明的样本学习数据曲线图;
图3是本发明的负荷150kwpz变化曲线图;
图4是本发明的pzdphcmac预测模型结构图;
图5(a)是本发明的pzhcmac学习预测曲线与实际曲线图;
图5(b)是本发明的pz并行hcmac学习预测曲线与实际曲线图;
图5(c)是本发明的pzdphcmac学习预测曲线与实际曲线图;
图5(d)是本发明的hcmac和dphcmac学习误差比较示意图;
图6(a)是本发明的pzdphcmac测试预测曲线与实际曲线图;
图6(b)是本发明的pzdphcmac测试预测误差曲线图。
具体实施方式:
下面结合附图与实施例对本发明作进一步说明。
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
正如背景技术所介绍的,现有技术中存在的在建模过程中有些参数很难确定,给建模及模型精度带来困难的不足,为了解决如上的技术问题,本申请提出了一种差分并行hcmac神经网络双侧变流量地源热泵系统功耗预测方法。
本申请的一种典型的实施方式中,地源热泵系统主要包括地源热泵机组、负荷侧循环泵、地源侧循环泵、空调末端和地埋管换热器等。在此不考虑空调末端功耗,地源热泵系统的功耗包括地源热泵机组功耗、负荷侧循环泵功耗和地源侧循环泵功耗。在相似工况条件下,循环泵的功耗与频率的变化呈三次方关系。数学表达式为:
式中,p0—循环泵工频下功率,kw;
p—当前频率下循环泵功率,kw;
f—当前循环泵频率,hz。
循环泵流量的变化与循环泵频率的变化呈线性关系,即:
式中,m0—循环泵工频下流量,m3/h;
m—当前频率下循环泵流量,m3/h。
随着地源侧循环泵和负荷侧循环泵频率的增加,热泵机组蒸发器和冷凝器的流量线性增加,但是热泵机组的运行功率逐渐降低。蒸发器和冷凝器的流量可降低到设计流量的30%。一般情况下,循环泵的频率最小值可设置为20hz,按照式(2)可知,循环泵的流量为设计流量的40%,满足热泵机组安全运行条件。在蒸发器出口温度和冷凝器回水温度不变的情况下,热泵机组功耗与当前用户负荷、蒸发器流量和冷凝器流量有关。具体结构框图如图1所示。
地源热泵系统总的功耗可表示为:
pz=pj(fl,fg,q)+pl(fl)+pg(fg)(3)
式中,fl—负荷侧循环泵频率,hz;
fg—地源侧循环泵频率,hz;
q—当前用户负荷,kw;
pl—负荷侧循环泵功耗,kw;
pg—地源侧循环泵功耗,kw;
pj—地源热泵机组功耗,kw;
pz—地源热泵系统总功耗;kw。
用户当前的负荷为:
q=cρm(tg-th)(4)
式中,m—蒸发器流量,m3/h;
tg—蒸发器出水温度,℃;
th—蒸发器回水温度,℃;
ρ—流体密度,m3/kg;
c—流体比热容,kj/(kg℃)。
从上述分析可以看出,地源热泵系统功耗与地源侧循环泵频率、负荷侧循环泵频率和用户当前负荷有关,最终确定地源热泵系统功耗预测模型的输入为fl、fg和q。.
学习和测试样本数据来自于搭建的双侧变流量trnsys仿真平台,热泵机组单元选用exlsr250.1,额定容量为225.7kw,额定cop为5,蒸发器额定流量为38.8m3/h,冷凝器额定流量为46.5m3/h,冷凝器额定回水温度为26.667℃,蒸发器额定出水温度为7℃。
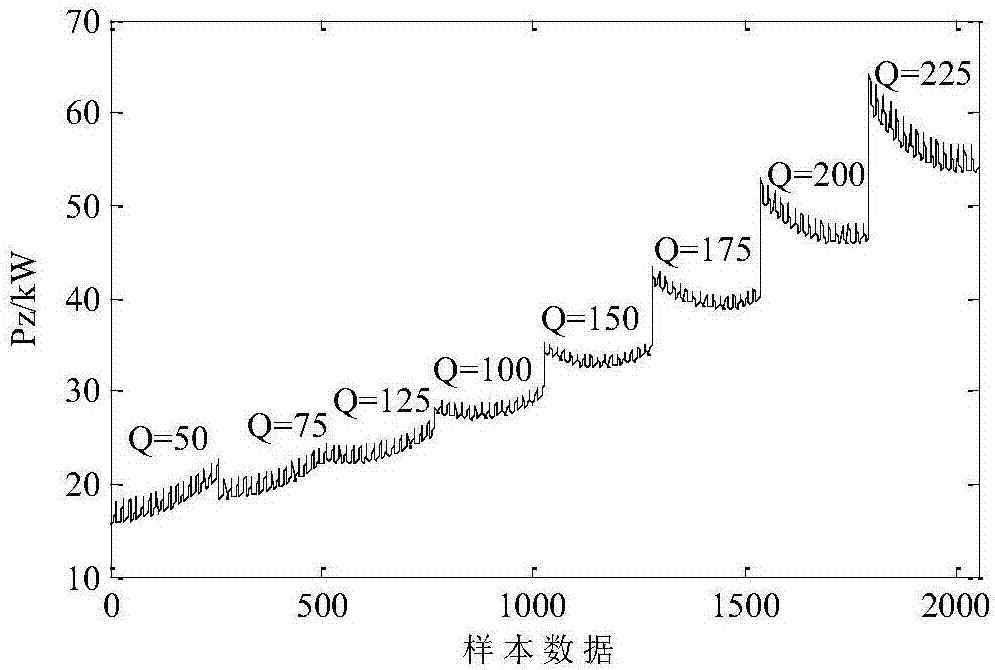
从仿真平台样本数据的全局可以看出,地源热泵系统的功耗pz随着用户负荷的增大而增大,但在相同的负荷下,地源侧和负荷侧不同的循环泵频率,对应不同的地源热泵系统的功耗pz,但其功耗只在小范围内变化。如图2所示,当用户负荷从50kw变化到225kw时,全局样本的功耗变化范围是15.57kw~64.04kw。在用户负荷为150kw时,地源热泵系统功耗的变化范围是32.45kw~35.22kw。图3为用户负荷为150kw时,负荷侧循环泵频率fl和地源侧循环泵频率fg分别从20hz-50hz变化对应的pz变化三维图。
为了提高预测模型的学习精度,根据样本数据的特点提出了一种dphcmac神经网络结构,如图4所示。
图中,pz01,…,pz08为子空间1~8的输出参考值,hcmac1,hcmac2,…,hcmac8为hcmac子模型。δpz为输出差分值,
dphcmac神经网络初始化
(1)输入空间x为3维,x=fl创fgq。由于循环泵的工频为50hz,地源热泵机组的额定容量为225.7kw,每一维的输入区间定义为,fl=[0,50],hz;fg=[0,50],hz;q=[0,225.7],kw。按照用户的负荷区间,将输入空间x划分为s个子空间,子空间定义为,xk=flk创fgkqk,k=1,2,…,s。子空间每一维的区间:flk=fl=[0,50],fgk=fg=[0,50],所有子空间中保持一致。q1=[0,50],q2=[50,75],q3=[75,100],q4=[100,125],q5=[125,150],q6=[150,175],q7=[175,200],q8=[200,225.7]。从而将整个输入空间划分为8个子空间。
(2)对每个输入子空间做归一化处理
式中,qkmin和qkmax分别是第k个子空间用户负荷的下限和上限。则任意输入子空间xk的任意输入xki=[flki,fgki,qki]归一化为
(3)根据每个子空间的输出空间pzk,确定每个输出子空间的参考值pz0k。满足:
pz0k<=pzkmin(6)
式中,pzkmin为子空间pzk的最小值。一般pz0k取整数。
(3)计算每个输出子空间pzk的输出差分值,形成新的输出差分子空间。
δpzk=pzk-pz0k(7)
(4)由于对每个子空间进行了归一化处理,所以每个子空间的神经网络网格划分相同,在此flk、fgk和qk取相同的量化级数,每一维的量化级数ql=[0,0.2,0.4,0.6,0.8,1.0]。将神经网络网格的交点编码形成节点向量pk,每个hcmac神经网络子模型的神经网络节点数均为63=216,pk=[pk1,pk2,…,pkl],l=216为节点数,8个神经网络子模型的节点向量相同。同时建立神经网络节点权度向量qk,初始情况下,神经网络每个节点的权度为0,q0k=[0,0,…,0]l。
神经网络学习算法
(1)神经网络基函数bki(·)
式中,j=1,2,…,l。
在ci上定义高斯基函数bki(·).
式中,σ为标准偏差。超闭球外的神经网络节点没被选中,基函数值为0;超闭球内的神经网络节点被选中,且距离超闭球的中心
由于对所有输入子空间作归一化处理,每个hcmac子模型一致,神经网络网格划分、神经网络节点向量、超闭球半径rb和标准偏差σ均相同。不同的是通过学习得到的神经网络权度向量不同。
(2)计算子模型hcmack神经网络的输出
子模型hcmack神经网络的输出为所有激活节点基函数和权度系数乘积的代数和。
(3)hcmac神经网络学习算法
hcmac神经网络学习算法采用c-l算法。
qk,m=qk,m-1+δqk,m-1(14)
式中,m为当前学习次数,em-1为上一循环实际值和hcmac预测值之差,α和β为常量,0<α<2,β>0。
(4)差分逆变换
按照上述方法完成对每个神经网络子模型的学习。
神经网络学习步骤
首先按照上述方法对dphcmac神经网络初始化。下面为第k个子空间神经网络学习过程,其他子空间学习过程相同。
step1:根据子空间学习样本个数确定第一层循环次数nsk。
step2:根据神经网络节点向量pk长度确定第二层循环次数l。
step3:计算输入xki和每个神经网络节点pkj的欧式距离,确定包含在超闭球内的神经网络节点,形成每个输入xki的基函数向量bki。
step4:计算子空间每个输入xki的基函数向量bki,最终形成基函数矩阵bk(nsk,l)。
step5:确定神经网络循环学习次数m。
step6:按照式(11)计算神经网络输出;
step6:根据实际值和神经网络输出值之间的偏差ek,按照式(12)(13)(14)学习神经网络子模型hcmack的权度系数向量qk。
step7:学习次数到,学习结束。
神经网络测试步骤
step1:stest为样本测试数据空间,
step2:按照输入子空间xk的论域区间,根据式(5)对xi进行归一化处理,得到
step3:以
step4:计算神经网络输出
step5:计算pzi
按照上述方法完成stest的测试。
样本数据来自于搭建的双侧变流量trnsys仿真平台,分别采用常规的hcmac神经网络、并行hcmac神经网络和本说明书提出的dphcmac神经网络进行仿真实验,其中hcmac神经网络每一维的量化级数为6,神经网络节点数为63=216。并行hcmac神经网络和dphcmac神经网络均包括8个并行hcmac子模型,每个模型的量化级数和hcmac神经网络相同,均为63=216,则并行hcmac神经网络和dphcmac神经网络节点总数为216×8=1728。并行hcmac神经网络和dphcmac神经网络的区别是dphcmac神经网络对每个子空间输出的差分进行学习,并行hcmac神经网络和hcmac神经网络相同,是对输出进行学习。rb和σ值的确定需要考虑模型的学习精度和泛化能力。根据经验,取rb=0.3,σ=0.15。以rmse作为评价指标,
式中,ei是pz实际值和预测值之差。
模型学习
首先采用hcmac神经网络对样本数据进行学习,得到hcmac模型的学习误差rmse_learning1=0.9816kw。显然pz的实际值和预测值的差值较大,预测精度不高,很难满足地源热泵双侧变流量循环泵供电频率的优化。然后采用并行hcmac预测模型学习,得到模型的学习误差rmse_learning2=0.6723kw。其学习精度有所提高,但神经网络的节点数增大。最后采用dphcmac预测模型学习,得到模型的学习误差rmse_learning3=0.1513kw,其神经网络节点数和并行hcmac神经网络相同,但预测精度显著提高。
为了图示清晰,在图5中只绘出负荷q=125kw时对应的256个学习数据,和其他负荷的学习效果一致。图5(a)为pzhcmac模型学习预测曲线与实际曲线,图5(b)为pz并行hcmac模型学习预测曲线与实际曲线,图5(c)为pzdphcmac模型学习预测曲线与实际曲线,图5(d)为hcmac模型与dphcmac模型学习误差曲线。
模型测试
根据测试样本数据对建立的dphcmac神经网络预测模型进行测试,经过测试得到本说明书提出的dphcmac神经网络模型的测试误差rmse_test=0.2247kw。为了图示清晰,在图6中只绘出负荷q=112.5kw时对应的256个测试数据,和其他负荷的测试效果一致。
从图6中可看出提出的dphcmac神经网络有较好的泛化能力,测试精度较高,可满足地源热泵系统功耗预测精度要求。
双侧变流量地源热泵系统功耗和负荷侧循环泵频率fl、地源侧循环泵频率fg以及空调的当前负荷q有关,地源热泵系统功耗的整体趋势变化是随着用户负荷的增大功耗逐渐增大;但是在相同的负荷下,循环泵频率不同,地源热泵系统功耗在一定范围内波动。采用常规的hcmac神经网络建模发现,其预测精度不能满足要求,为了提高预测精度,根据样本数据的特点,提出了一种dphcmac神经网络模型用于预测双侧变流量地源热泵系统功耗,其主要创新点在于根据样本数据的特点将样本数据空间划分为多个子空间,确定每个子空间输出的参考值,得到每个子空间输出的差分。hcmac子模型学习输出的差分值,由于输出差分的论域区间远远小于实际输出的论域区间,使得模型的学习精度显著提高。以rmse作为误差评价指标,hcmac神经网络的学习误差为rmse_learning1=0.9816kw。提出的dphcmac神经网络的学习误差为rmse_learning3=0.1513kw,dphcmac神经网络的测试误差为rmse_test=0.2247kw。显然,提出的dphcmac神经网络具有较好的学习精度和测试精度,可以实现双侧变流量地源热泵系统功耗pz的精确预测。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!
- 基于BP神经网络的防眩玻璃化学侵蚀工艺参数优化方法与流程
- 一种治疗神经分裂症的组合物的利记博彩app与工艺
- 基于剪裁的霍普菲尔德神经网络的多元密码学的利记博彩app与工艺
- 一种基于Ga2O3神经仿生层的神经仿生器件及其制备方法与流程
- 一种结合BP神经网络的企业领域供应商推荐方法与流程
- 基于粗糙集与BP神经网络的泵的故障诊断方法与流程
- 具有神经存储器的神经网络单元以及集体将接收自神经存储器的数据列进行移位的神经处理单元阵列的利记博彩app与工艺
- 一种基于权重压缩的神经网络处理器、设计方法、芯片与流程
- 基于BP神经网络的动力电池外部短路故障诊断及温升预测方法和系统与流程
- 一种基于神经网络的跨界易物平台实现方法及平台与流程