面向海量轨迹点数据的时空索引构建方法与流程
本发明涉及信息检索领域,特别涉及一种面向海量轨迹点数据的时空索引构建方法。
背景技术:
随着科学技术的发展,当今世界已进入大数据时代。数据规模的快速增长,使得大数据需要具备全局表达力,时空大数据因其能够体现时间、空间以及对象之间的关联关系,成为了重要的大数据之一。然而,时空大数据之间相对复杂的关系及其动态演化的特性,也带来了检索查询的困难。轨迹点数据就属于时空大数据,其具体是指,在时空环境下,通过对移动对象运动过程的采样所获得的数据信息。近年来,卫星、无线网络,以及定位设备高速发展,大量移动物体的轨迹点数据呈急速增长的趋势,对于轨迹点数据的索引构建及优化查询成为了近年来的热门研究。
hadoop是当下流行的一种分布式计算框架,适用于各类大规模数据的计算处理场景,具有广泛的应用基础,目前已有一些基于该框架及其生态软件提出的时空索引方法,如基于hbase的q树时空索引、基于hbase的网格r树混合时空索引等。现有的时空索引构建方法,大多将数据记录条作为索引单元,这种方式导致存储消耗大且索引构建效率较低,无法满足不同类型的时空大数据快速增长的需求。
技术实现要素:
本发明的目的是提供一种面向海量轨迹点数据的时空索引构建方法,该方法能够克服上述现有技术的缺陷,在分布式环境下并行构建轨迹点数据的时空索引,效率较高;并且以数据文件作为索引单元,使索引结构具有灵活的扩展性。
本发明采用的技术方案如下:一种面向海量轨迹点数据的时空索引构建方法,包括以下步骤:
步骤1)、将轨迹点数据存储在轨迹点数据文件中;
步骤2)、以所述步骤1)中的轨迹点数据文件为索引单元构建索引树。
优选的,所述步骤1)中的轨迹点数据至少包含时间信息和二维位置信息。
优选的,所述步骤2)进一步包括:
步骤21)、将所述轨迹点数据文件划分到至少一个计算单元中;
步骤22)、所述计算单元基于空间索引结构构建时空索引。
优选的,当所述计算单元为多个并行计算单元时,所述步骤21)中对轨迹点数据文件的划分为有序划分。
优选的,利用空间填充曲线实现所述步骤21)的有序划分。
优选的,所述空间填充曲线为希尔伯特曲线。
优选的,所述步骤21)进一步包括:
步骤211)计算用于表征所述轨迹点数据文件的二维空间信息的二维希尔伯特值;
步骤212)根据所述步骤211)中计算得出的二维希尔伯特值计算用于表征所述轨迹点数据文件的三维空间信息的三维希尔伯特值;
步骤213)根据所述步骤212)中计算得出的三维希尔伯特值对所述轨迹点数据文件进行划分。
优选的,所述步骤22)中的空间索引结构是r*树结构。
优选的,可基于mapreduce或spark编程框架实现对所述多级时空索引树的构建。
根据本发明的另一个方面,提供一种基于上述方法构建的索引树对轨迹点数据进行查询的方法,包括:
步骤a)、遍历所述索引树的根节点,取得根节点列表;
步骤b)、查询所述步骤a)取得的根节点列表,取得子节点列表;
步骤c)、并行遍历步骤b)中取得的子节点列表,取得轨迹点数据文件列表。
优选的,所述查询方法可基于mapreduce或spark编程框架实现。
有益效果:本发明的面向海量轨迹点数据的时空索引构建方法,采用了包含运动信息的数据文件作为索引单元,降低了索引的存储消耗,且可以根据需求调整数据文件的存储方式,使索引结构具有高度的可扩展性;同时使用了希尔伯特曲线对数据文件进行划分,相比其他的多维到一维映射的方式,如将经纬度映射为网格编号,希尔伯特曲线因其优秀的空间填充特性使得划分效果更良好,能够降低数据倾斜发生的概率。
附图说明
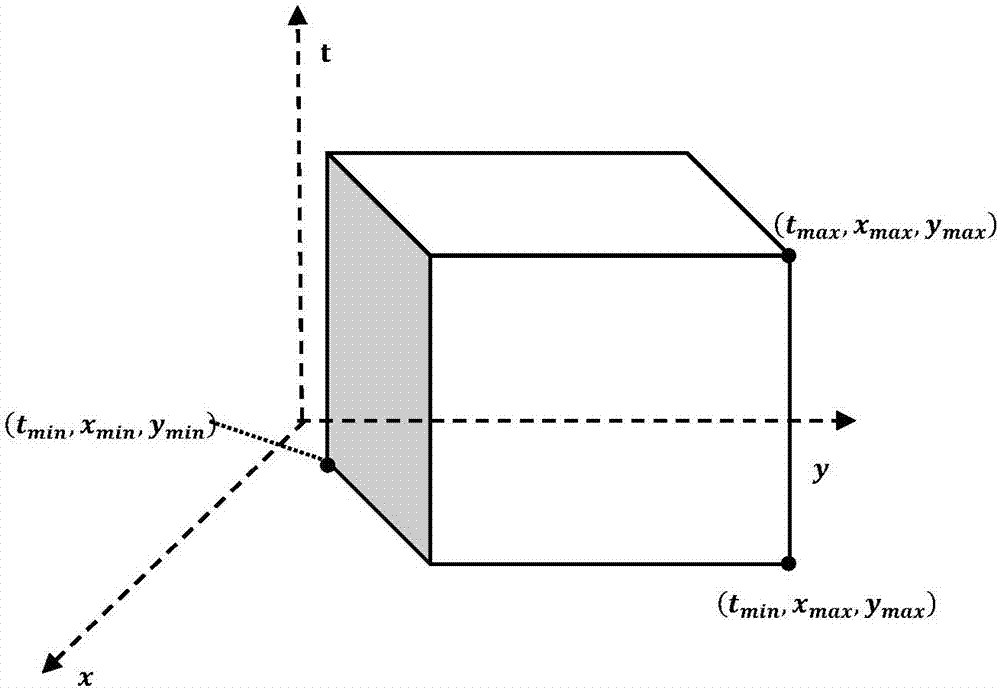
图1为本发明提供的轨迹点数据文件的时空立方体示意图
图2为本发明提供的面向海量轨迹点数据的索引树结构示意图
图3为采用mapreduce编程框架实现的基于r*树的多级时空索引树并行构建过程,
图4为采用mapreduce编程框架实现的基于图3构建的时空索引树的并行查询过程
具体实施方式
为了使本发明的目的、技术方案以及优点更加清楚明白,以下结合附图,对根据本发明的实施例中提供的面向海量轨迹点数据的时空索引构建方法进一步详细说明。
轨迹点数据是对移动对象的实时位置采样而获得的一系列数据记录,每条记录包括了采样时间戳,二维位置信息,速度、方向等其他运动信息以及采样时刻等其他相关信息。轨迹点数据是一种结构化数据,这种数据列数固定并且每列的含义、类型及值域也固定;同时,这种由采样收集到的轨迹点数据一经产生,一般就不会再被修改和删除,并且由在线采集转向离线分析的过程中,轨迹点数据会定期批量积累。
发明人经研究发现,根据轨迹点数据的上述特征,可以将轨迹点数据按行存储并组织为若干个的数据文件,并以这种存储有轨迹点数据记录的数据文件为单位对轨迹点数据进行时空索引。
在对轨迹点数据进行记录时,每条轨迹点数据记录可以抽象为n维向量,第i条记录可以描述为:
(ti,xi,yi,oi1,...,oin-3)
其中,ti为采样时刻时间戳,xi、yi为移动对象在ti时刻的二维位置信息(一般为经纬度),oi1,...,oin-3为其余n-3维的信息。
图1示出了本发明提供的面向海量轨迹点数据的时空索引构建方法的轨迹点数据文件的时空立方体示意图。如图1所示,将多条轨迹点数据存储为一个轨迹点数据文件,每个轨迹点数据文件包含的轨迹点数据具有时空三维的取值范围,表征该立方体范围的三个顶点分别为:
(tmin,xmin,ymin)、(tmin,xmax,ymax)、(tmax,xmax,ymax)
根据需求,轨迹点数据的存储方式可以有多种,例如,按时间升/降序存储,按空间区域网格存储,或单一空间区域网格内的轨迹点数据按时间升/降序排列存储等。下面将以按时间升序存储的轨迹点数据文件为例,对构建轨迹点数据时空索引的过程加以说明。
根据本发明的一个实施例,提供了一种面向海量轨迹点数据的时空索引构建方法。该方法包括轨迹点数据文件的划分和索引树的构建两个步骤,具体内容如下:
s10、将轨迹点数据文件划分到至少一个计算单元;
根据轨迹点数据文件数量的多少,在进行索引树构建时,可将轨迹点数据文件划分到单个计算单元执行,或分配给多个计算单元并行执行,以提高处理速度及效率。以划分为w个计算单元为例,通过将所有的轨迹点数据文件分配到w个计算单元上,由所述计算单元对每一个轨迹点数据文件,遍历所有轨迹点数据记录,统计获得该轨迹点数据文件包含记录的时间、空间取值范围:
(tmin,tmax)、(xmax,xmin)、(ymax,ymin)
取该轨迹点数据文件的时空立方体的中心点作为标识,则每个轨迹点数据文件的可以表征为一个三维坐标:
((tmin+tmax)/2,(xmin+xmax)/2,(ymin+ymax)/2)
根据本发明的一个实施例,在采用多计算单元并行执行时,为了降低查询时的并行遍历开销,提高索引性能,还可以利用空间填充曲线计算中心点在三维空间中的相近程度,将相近时间和相近地理空间的轨迹点数据文件划分在一个计算单元内。
希尔伯特曲线是一种空间填充曲线,可将二维空间内的点映射为一维的值,即希尔伯特值,希尔伯特值相近的二维空间内的元组,常具有在二维空间中相近的性质。以下将采用希尔伯特曲线为例,进行详细描述,具体步骤如下:
s101、将前述轨迹点数据文件的时空立方体的中心点作为标识该轨迹数据文件的向量。设第i个轨迹点数据文件的标识向量为(t′i,x′i,y′i),首先计算(x′i,y′i)的二维希尔伯特值
s102、对于所有轨迹点数据文件,按采样率p进行采样。假设样本个数为m,预定的并行计算单元为w个,表征m个数据文件的希尔伯特值升序排列为
s103、遍历所有轨迹点数据文件,判断第i个数据文件的希尔伯特值
若
则将第i个文件划分至第1个计算单元;
若
则将第i个文件划分至第j个计算单元;
若
则将第i个文件划分至第w个单元。
希尔伯特曲线具有良好的空间填充特性,在对轨迹点数据文件进行划分时,可以降低数据倾斜发生的概率。尽管在上述实施例中,采用了希尔伯特曲线来对轨迹点数据文件进行划分,但本领域普通技术人员应理解在其他实施例中可以采用多种划分方式来对轨迹点数据文件进行有序划分,如按时间顺序或采用其它类型的空间填充曲线。
s20、基于r*树构建多级时空索引树;
r*树是空间索引结构r树的一种变体。r树是b树在多维空间扩展而成的高度平衡树。与r树相比,r*树在结构上没有太多变化,区别主要是在索引树的插入方面考虑了重叠,r*树对索引中有先插入的单元进行有选择的重新插入,从而优化索引树。
在步骤s10完成后,计算单元将以分配到的轨迹点数据文件作为索引单元,基于r*树并行构建该计算单元的多级时空索引树。
图2为本发明提供的索引树结构示意图,如图2所示,索引树的构建过程与基本的r*树构建过程相同。索引树以每个轨迹点数据文件的存储路径及其包含轨迹点数据的范围,即前述轨迹点数据文件的时空取值范围(tmin,tmuax)、(xmax,xmin)、(ymax,ymin),作为索引单元文件。具体步骤如下:
s201、叶子节点的构建:每个叶子节点包含了至少一个索引单元,以及可以框住上述所有索引单元的最小时空矩形;
此处的最小时空矩形是指其所包含的所有轨迹点数据文件的时空取值范围,以下均同。
s202、非叶子节点的构建:每个非叶子节点包含了其子节点的指针数组以及可以框住其所有子节点的最小时空矩形;
s203、索引子树根节点的构建:每个计算单元上的索引子树根节点,包含了其子节点的指针数组以及可以框住该根节点所有子节点的最小时空矩形,如果索引子树根节点为叶子节点,则包含了该计算单元上的所有轨迹点数据文件的时空取值范围;
s204、索引树根节点的构建:每个索引树根节点,包含了所有计算单元上轨迹点数据文件的记录路径以及可以框住该根节点所有子节点的最小时空矩形。
s205、总索引树文件的构建:由于轨迹点数据总量的大小或积累时间的不同,通常需要分批次执行索引树的构建,每次构建生成的索引树根节点可按其所包含的时间范围进行升序存储,即为最高层级的总索引树文件。
相比传统的将每条数据记录作为索引单元,本发明提供的以轨迹点数据文件为索引单元的方法,大幅度降低了索引树的构建复杂度,提高了运行速度,节省了系统开销,能够显著提升对轨迹点数据管理效率和查询效率,并且能够满足轨迹点数据不断积累的需求。
其中,轨迹点数据文件内储存轨迹点数据的条数,即轨迹点数据文件的大小,会影响构建索引树的深度,轨迹点数据文件越大,索引树深度越小,运行速度越快;相对的,轨迹点数据文件越小,索引树深度越大,查询精确度越高。
在本发明的另一个实施例中,上述索引树的构建可以基于mapreduce编程模型实现,以并行计算单元为例,图3示出了基于mapreduce编程框架实现的索引树构建流程图,如图3所示,具体流程如下:
步骤101:将轨迹点数据文件均匀分配到并行计算单元上,每个并行计算单元每次以轨迹点数据文件的存储路径pi作为map端输入,遍历轨迹点数据文件中的所有记录,统计该数据点文件中包含的轨迹点数据的时空取值范围(timin,timax)、(ximax,ximin)、(yimax,yimin);
步骤102:统计完成后,并行计算单元将轨迹点数据文件的存储路径以及步骤101中所述的轨迹点数据文件的时空取值范围构成元组(pi,(timin,timax,ximax,ximin,yimax,yimin))作为map端输出;
步骤103:并行计算单元将所有轨迹点数据文件的在步骤102中所述的元组作为reduce端的输入及map端输出并存储为轨迹点数据文件索引记录文件,即为索引树构建时的索引单元。
步骤201:并行计算单元遍历所有轨迹点数据文件,以步骤102中所述的元组作为map端的输入;对每个轨迹点数据文件i的时空立方体的中心点((timin+timax)/2,(ximin+xmax)/2,(yimin+yimax)/2)作为该轨迹点数据文件的标识,设为(tf,xf,yf);根据前述中心点计算该数据文件的希尔伯特值hts:设h(x,y)为原始的希尔伯特函数,round(x)为四舍五入的函数,数据文件的希尔伯特值计算函数hts定义为:
hts=hts(t,x,y)=
h(round(at),round(bh(round(x),round(y))))
其中a,b为根据需求计算所得的调节参数,用于优化计算希尔伯特值。在计算过程中,同时生成一个[0,1]之间的随机数r,若r≤0.1,则(hts,1)作为map端的输出,否则不产生输出,从而实现采样。将获得的hts值按升序排列,根据需求取特定的hts值作为划分点(与步骤s102同);
步骤202:并行计算单元遍历所有轨迹点数据文件,将每个步骤102中所述的元组作为map端的输入,计算该轨迹点数据文件的希尔伯特值
步骤203:并行计算单元对步骤202中的map端输出即reduce端输入,根据划分的并行计算单元编号,分别存储为轨迹点数据文件的索引记录文件,每行记录为(pi,timin,timax,ximax,ximin,yimax,yimin);
步骤301:每个并行计算单元分别构建索引子树(与步骤s201-s203同);
步骤401:将各索引子树追加到存储索引子树根节点的索引子树文件中,索引树根节点记录为
步骤501:将该批次的索引树根节点记录追加到存储已有的索引树根节点的索引树文件中,之后将所有索引树根节点按时间范围的最大值升序排列(与步骤s205同)。
经发明人研究,以1tb大小的轨迹点数据集为例,将这些轨迹点数据分别储存成与hdfs块的默认值相同大小的若干轨迹点数据文件中,即128mb。采用本发明提供的方法针对上述轨迹点数据文件构建时空索引树,共计可生成约9000条索引记录。这不仅使参与时空索引构建的数据规模大幅度减小,同时也能提高构建速度。
在本发明的另一个实施例中,还提供了一种基于上述构建的索引树对大量轨迹点数据进行并行查询的方法。例如,需要查询的大量轨迹点数据的时空取值范围是:
{t∈[tmin,tmax]∩x∈[xmin,xmax]∩y∈[ymin,ymax]}
其中t为时间取值条件,x,y为二维地理空间取值条件。具体的查询步骤如下:
s30、遍历前述所有索引树的根节点,将时间范围与[tmin,tmax]存在交集的索引树根节点加入带查询的根节点列表中;
s40、依据tmain/2二分查找步骤a中取得的根节点列表,将时空取值范围存在交集的索引树根节点的索引子树根节点加入待并行遍历子节点列表中;
s50、并行遍历步骤b中取得的子节点列表中的索引子树根节点的各子节点,若该节点为非叶子节点,则遍历该节点的所有子节点,将时空取值范围存在交集的子节点加入待并行遍历子节点列表中;若该节点为叶子节点,则遍历该节点的所有记录,将时空取值范围与查询条件的时空取值范围存在交集的数据文件路径加入待查询文件列表中;
s60、当待遍历子节点列表变为空后,在待查询文件列表中,即包含所有待查询的轨迹点数据文件集合中,进一步查询需求的轨迹点数据。
在本发明的另一个实施例中,上述查询方法可以基于mapreduce编程模型实现,图4示出了基于mapreduce编程框架实现的上述查询方法的流程图,如图4所示,具体流程如下:
步骤101′:读取索引树文件,第i行记录为
步骤102′:读取索引子树文件,获得步骤101中所有待遍历根节点队列q0中的根节点的索引子树根节点,对索引子树根节点与查询条件进行重叠判断,符合重叠条件的索引子树根节点放入待遍历节点队列qnode中。
上述重叠判断是指根据步骤101获得的索引子树根节点e的时空取值范围
且
且
步骤201′:以qnode中的索引子树根节点作为map输入,对每个索引子树根节点e,如果e为非叶子节点,e的子节点为
步骤202′:对于reduce端输入key值为0的记录,即非叶子节点的记录,设一条记录为
步骤301′:步骤201′和202′为并行mapreduce过程,执行完毕后将reduce端的输出作为map端的输入,重新进入步骤201′,直至步骤202′结束后reduce端的输出为空。
步骤401′:返回查询临时表中的内容,获得最终的轨迹点数据文件查询结果。
经发明人研究,本发明提出的时空索引构建及查询方法,在对索引树的节点进行遍历时仅包括投影、聚集类运算,不涉及对单个轨迹点数据文件中的轨迹点数据排序等复杂运算过程,降低了系统开销,提高了构建及查询速度,同时采用以轨迹点数据文件为单位的方式也具有更高的灵活性及扩展性。
在本发明的另一个实施例中,上述索引树的构建及查询还可以基于spark编程框架实现。spark提供的rdd抽象数据结构编程模型主要基于内存运算实现,除了能够提供交互式查询外,它还可以优化迭代工作负载。
尽管在上述实施例中,采用了基于r*树的结构来对海量的轨迹点数据文件进行索引树构建,但本领域普通技术人员应理解在其他实施例中可以采用多种空间索引结构实现本发明提供的以轨迹点数据文件为索引单元进行索引构建的方法。
虽然本发明已经通过优选实施例进行了描述,然而本发明并非局限于这里所描述的实施例,在不脱离本发明范围的情况下还包括所作出的各种改变以及变化。
- 还没有人留言评论。精彩留言会获得点赞!