一种融合多特征的双向循环神经网络细粒度意见挖掘方法与流程
本发明涉及一种自然语言处理与神经网络技术领域,尤其是一种融合多特征的双向循环神经网络细粒度意见挖掘方法。
背景技术:
目前,随着互联网上文本数据的不断增加,对于数据的挖掘和分析任务就显得非常重要,对于文本挖掘和意见分析领域来说,传统的方法有基于词典,基于人工特征模版,还有基于频繁模式挖掘的方法。这一类方法中主要完成了两个任务,一是属性抽取和实体识别,一是情感分析和基于属性词的极性分析,对于意见挖掘的相关研究主要集中在句子或篇章级别的情感分类,用户更期待细粒度级别的意见挖掘结果,现有意见挖掘的主流方法中,利用规则的抽取方法灵活性和扩展性有待提高,而基于隐马尔科夫模型或条件随机场(crf)的属性抽取方法则不能很好的处理长距离情感要素依赖的问题。
现在大部分的研究工作都是在特定条件下的意见分析和情感分类,如给定一个评论文本和一个目标词,分词目标词在当前句子中的情感极性,或者是基于给定评论文本中出现的不同属性和实体词,判断每个实体的情感极性,而能够完成这个任务的前提是要有大量标记数据,要对每一条数据标出目标词或者属性词,同时标注情感极性,一般属性词的抽取模型还要有人工选择特征和制定模版的过程,这些过程又需要有相关专业背景的人才能够完成,需要消耗大量的人力,而且人工标注语料效率低下,并且主要用神经网络和深度学习的方法都是基于词的表示学习作为特征输入,这样传统的语言学特征如词性,依存关系等就会丢失。
技术实现要素:
针对现有技术的不足,本发明提供一种融合多特征的双向循环神经网络细粒度意见挖掘方法。
本发明的技术方案为:一种融合多特征的双向循环神经网络细粒度意见挖掘方法,其特征在于,包括以下步骤:
s1)、抓取特定网站的评论数据作为训练样本集;
s2)、通过人工标注训练样本集中每条评论数据中所需要的属性或实体,根据人工标注结果使用实体标记方法(bio)标记每条评论数据的属性或实体后,并进行情感极性标注,即(b1,i1,o)表示评论数据的情感极性为正面,(b2,i2,o)表示评论数据的情感极性为负面,(b3,i3,o)表示评论数据的情感极性为中性,从而得到评论数据中每个词的7个情感极性标记分类结果,即
s3)、对训练样本集进行分词,词性标注和依存关系标注等预处理;
s4)、选取一个汉语的维基百科语料库,并对其进行分词,词性标注和依存关系标注等预处理,使用word2vec或glove模型算法,输入预处理后的训练样本集与预处理后的维基百科语料库,训练输出评论数据与维基百科语料库中每个词的词向量vec_model;
s5)、将预处理后的训练样本集中的每一条评论数据转化为序列x={x1,x2,…,xn},其中,xi表示该条评论数据的第i个词,并将序列x={x1,x2,…,xn}对应的词性标注(part-of-speech)序列记为p={p1,p2,…,pn},其中,pi表示xi的词性,以及对应的依存关系标注(dependencyrelation)序列记为d={d1,d2,…,dn},依存关系对记为r={r1,r2,…,rn},其中,ri表示任意2个词的依存关系,
对于每一条评论数据,在t时刻,任意词xt、词性标注dt、依存关系标注pt、依存关系对rt四个特征向量化后融合拼接得到向量
s6)、将向量
将前、后隐藏层
yt是一个纬度为7的概率分布向量,即
其中,n为词向量纬度,n1为依存关系种类个数,n2为词性标签种类个数,
s7)、将预测值yi与真实值
其中,i表示每条评论数据中每个词的索引,j表示每条评论数据的7类情感极性标记分类的索引;
并通过梯度下降算法更新网络中的权重矩阵
s8)、获取新的评论数据作为测试语料集,并对测试语料集按照步骤s2-s5进行相应的处理后输入步骤s7)中训练好的双向循环神经网络序列标注模型,对测试语料集进行情感极性分类。
上述技术方案中,步骤s5)中,在t时刻,词性标注dt、依存关系标注pt向量化采用one-hot模型,若依存关系对rt=(xt,xj),取xt的词向量
本发明的有益效果为:通过一个模型的训练同时抽取细粒度意见挖掘中属性词以及情感极性判断,不同于传统的需要两阶段分开训练,先训练一个属性词抽取模型,抽取出属性词后在去训练一个基于属性词的情感分类模型,从而进一步节约的大量的模型训练时间,提高训练效率,而且,无需专业技术人员对属性词进行人工抽取,从而节约了大量的人工成本以及大量的工作量,本发明简化了特征提取和模型构建的任务,进一步提高了意见挖掘和情感分析任务的效率,并通过加入评论数据的词性、依存关系等语言学信息,相比单一的词向量,可以更好的学习评论数据文本中上下文的语义信息;另外,可以通过用多种数据源训练模型,从而可以完成跨领域的细粒度意见分析,从而解决长距离情感要素依赖的问题。
附图说明
图1为本发明的流程示意图;
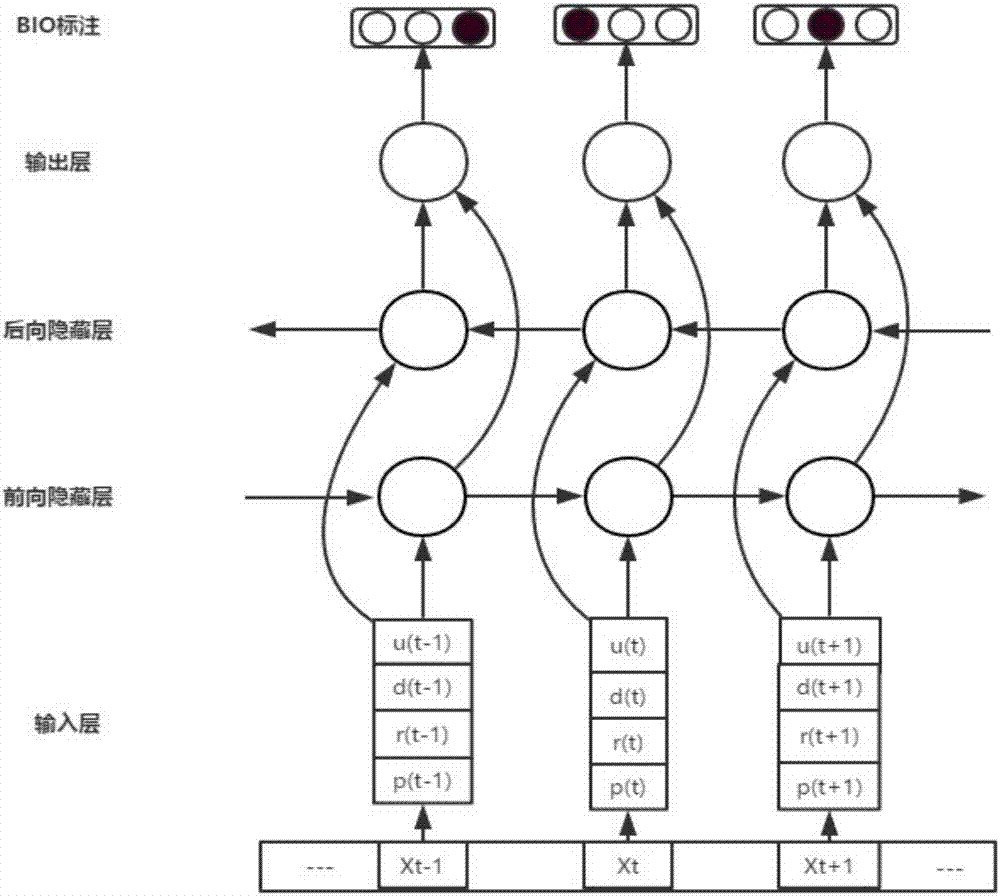
图2为本发明双向循环神经网络序列标注的模型图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明:
如图1和图2所示,一种融合多特征的双向循环神经网络细粒度意见挖掘方法,其特征在于,包括以下步骤:
s1)、抓取特定网站的评论数据作为训练样本集;
s2)、通过人工标注训练样本集的每条评论数据中所需要的属性或实体,根据人工标注结果使用实体标记方法(bio)标记每条评论数据的属性或实体后,并进行情感极性标注,即(b1,i1,o)表示评论数据的情感极性为正面,(b2,i2,o)表示评论数据的情感极性为负面,(b3,i3,o)表示评论数据的情感极性为中性,从而得到评论数据中每个词的7个情感极性标记分类结果,即
s3)、对训练样本集进行分词,词性标注和依存关系标注等预处理;
s4)、选取一个汉语的维基百科语料库,并对其进行分词,词性标注和依存关系标注等预处理,使用word2vec或glove模型算法,输入预处理后的训练样本集与预处理后的维基百科语料库,训练输出评论数据与维基百科语料库中每个词的词向量vec_model;
s5)、将预处理后的训练样本集中的每一条评论数据转化为序列x={x1,x2,…,xn},其中,xi表示该条评论数据的第i个词,并将序列x={x1,x2,…,xn}对应的词性标注(part-of-speech)序列记为p={p1,p2,…,pn},其中,pi表示xi的词性,以及对应的依存关系标注(dependencyrelation)序列记为d={d1,d2,…,dn},依存关系对记为r={r1,r2,…,rn},其中,ri表示任意2个词的依存关系,
对于每一条评论数据,在t时刻,任意词xt、词性标注pt、依存关系标注dt、依存关系对rt四个特征向量化后融合拼接得到向量
s6)、将向量
将前、后隐藏层
其中,n为词向量纬度,n1为依存关系种类个数,n2为词性标签种类个数,
s7)、将预测值yi与真实值
其中,i表示每条评论数据中每个词的索引,j表示每条评论数据的7类情感极性标记分类的索引;
并通过梯度下降算法更新网络中的权重矩阵
s8)、获取新的评论数据作为测试语料集,并对测试语料集按照步骤s2-s5进行相应的处理后输入步骤s7)中训练好的双向循环神经网络序列标注模型,对测试语料集进行情感极性分类。
上述技术方案中,步骤s5)中,在t时刻,词性标注dt、依存关系标注pt向量化采用one-hot模型,若依存关系对rt=(xt,xj),取xt的词向量
上述实施例和说明书中描述的只是说明本发明的原理和最佳实施例,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
- 还没有人留言评论。精彩留言会获得点赞!