一种基于超图的图像检索与标注方法与流程
本发明涉及超图上的top-k查询技术,特别涉及一种基于超图的图像检索与标注方法。
背景技术:
随着社交媒体和移动互联网的发展,社交图像网站提供了大量由不同用户进行文本标注的图像。社交图像往往附带多种信息,譬如视觉特征、标签和用户等,以及多种行为关系,譬如标注和评论等。对海量社交图像进行检索和标注应用非常广泛,成为数据库、数据挖掘和机器学习领域的研究热点。
图像检索是根据给定的信息,查找最相近的图像对象,根据给定的信息类型不同,又有相似图像检索和关键字图像检索等多种检索类型。图像标注是给指定图像附加语义文本信息,也即根据图像查找最相近的语义文本。超图是普通图模型的扩展,其中的超边可包含多个结点,故能够表示高维关系,更适合对复杂网络进行建模。图像检索和标注在搜索引擎和社交媒体等领域有重要的应用价值。
目前的图像检索和标注方法,一般仅对单一特征进行管理,或使用普通图对社交图像进行建模。然而,单一特征只能表示某方面的相关性,不能用来表示真实的语义关联,普通图不能够表示高维关系(比如标注和评论关系),造成了信息缺失。一些机器学习领域的方法使用超图模型,但使用了复杂的矩阵运算进行求解,时间和存储开销巨大且不具有扩展性。
技术实现要素:
针对上述不足,本发明提供一种基于超图的图像检索与标注方法,该方法使用超图对社交图像进行建模来表示高维关系,使用批量、并行和缓冲技术来加速超图模型构建,并使用个性化pagerank加速超图上的top-k查询,也使用并行和近似方法进一步加速了查询,本发明既提高了查询效率也保证了查询质量。
本发明解决其技术问题采用技术方案的步骤如下:一种基于超图的图像检索与标注方法,该方法的步骤如下:
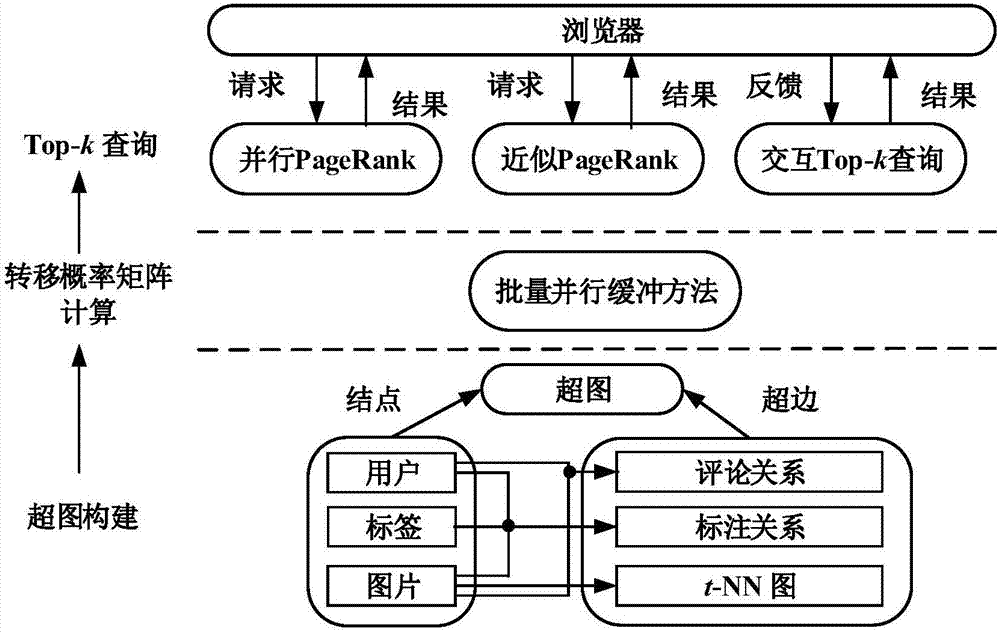
步骤(1):使用一个基于内容的图像检索引擎对图像数据集建立t-nn图,并将各图像与其视觉特征最相似的t张图像建立联系;
步骤(2):根据图像t-nn图和图像的社交关联信息,建立超图,计算其转移概率矩阵并存储到b+树中;
步骤(3):用户提交查询对象集合和k值;
步骤(4):根据用户提交的查询对象集合生成查询向量,而后在超图上进行并行的个性化pagerank查询,利用上、下界估计方法过滤超图的结点,逐步缩小pagerank查询过程中每轮迭代的候选点集合,直至得到k个结果;
步骤(5):用户对步骤(4)得到的k个结果进行评价,生成反馈信息,再根据反馈信息调整步骤(4)中的查询向量,形成新的查询向量,再重复步骤(4),最终获得新的查询结果并返回给用户。
进一步的,所述的步骤(1)中图像检索引擎基于度量空间spb树索引结构,根据mpeg-7标准提取图像的视觉特征,建立spb树,并对各图像进行t-nn查询,获得与其最相近的t个查询结果,进而建立t-nn图。
进一步的,所述的步骤(2)中超图的种类有三种:
1)以图像t-nn图中的各图像和其t-nn图像作为一种超边;
2)以用户对图像进行标注的三元组合作为一种超边;
3)以用户对图像进行评价的多元组合作为一种超边。
进一步的,所述的步骤(2)中计算超图转移概率矩阵的具体步骤如下:
用g(v,e,w)表示一个超图,其中v是结点集合,e是超边集合,w是一个权重函数;一个超图可以用一个|v|×|e|的矩阵h表示,其中矩阵元素h(v,e)为:
其中,v为结点,e为超边;
结点v的度d(v)可以表示为:
d(v)=∑e∈e|v∈ew(e)=∑e∈ew(e)h(v,e)
其中,w(e)表示超边e的权重;
超边e的度δ(e)可以表示为:
δ(e)=|e|=∑v∈vh(v,e)
超图的转移概率矩阵,用p来表示,则p中的元素p[u,v]表示从结点u到结点v的转移概率,其可以使用如下公式进行计算:
进一步的,所述的步骤(2)中转移概率矩阵采用批量插入方法、并行技术和缓冲技术存储到b+树中;在将转移概率矩阵存储到b+树中时,把超图的出度结点和入度结点的组合作为键,转移概率作为值。
进一步的,所述的步骤(3)中k是用户指定的查询返回结点个数。
进一步的,所述的步骤(4)中的个性化pagerank以查询向量和k值作为输入,在每轮迭代中,根据转移概率矩阵,结点从该结点的入度结点获得排名得分,该排名得分值为上一轮该入度结点的排名得分和转移概率的乘积。
进一步的,所述的步骤(4)中上、下界估计具体如下:
1)对于下界估计,第i轮的下界估计si[u]使用如下公式计算:
其中,c为阻尼系数,i为当前迭代轮次,si-1[u]为第i-1轮的下界估计;λi[u]为第i轮迭代中从查询节点到节点u的随机游走概率值,具体公式如下:
其中,q表示查询向量,q[u]表示结点u的权重,且∑u∈vq[u]=1;另外用c[u]来表示结点u的入度结点集合,λi-1[v]为第i-1轮迭代中从查询节点到节点v的随机游走概率值;
2)对于上界估计,第i轮上界估计
其中,pmax[u]=max{p[v,u]|v∈v}为当前结点u的所有入度转移概率的最大值;
进一步的,所述的步骤(4)中利用上、下界估计方法过滤超图的结点,具体过滤步骤如下:
(4.1)当候选点集合大小大于k时,若候选点集合中的某结点的上界估计大于当前第k大的结点下界估计,则该结点为候选点,可能出现在最终的k个结果中,否则不可能成为结果点,则抛弃;若候选点集合大小为k时,则候选点集合中所有结点为最终返回结果,候选点集合中的结点排序通过步骤(4.2)或步骤(4.3)确定;
(4.2)当候选结点集合大小为k时,若候选结点集合中某结点的下界估计均大于集合内其他结点的上界估计,或者某结点的上界估计均小于集合内其他结点的下界估计时,则该结点的排序确定,将该结点加入结果结点集合;候选结点排序全部确定时停止迭代;
(4.3)当候选结点集合大小为k时,检测当前所有候选结点的上下界估计差值,若所有结点的上下界估计差值小于设定阈值时,停止迭代,结点的排序根据下界估计降序确定。
进一步的,所述的步骤(5)中用户对步骤(4)得到的k个结果进行评价,选出其中符合其查询意愿的结果图像作为反馈节点,根据反馈节点调整步骤(4)中查询向量,将反馈结点插入原查询向量中,构成新的查询向量,对新的查询向量中的原查询结点和新插入查询结点重新进行权重分配,再次进行步骤(4)中个性化pagerank查询,并使用上、下界估计方法进行过滤,最终获得新的查询结果并返回给用户。
本发明具有的有益效果是:本发明采用超图理论,使得社交图像的评论关系、标注关系和视觉相似关系等多维关系可以得到有效的组织;采用空间数据库中度量索引技术,充分利用了批量构建技术、并行技术和缓冲技术,使得超图转移概率矩阵的计算效率得到显著的提高;采用上下界估计技术,带来了查询效率提高的技术效果,使得迭代次数极大减少,i/o开销和cpu时间显著降低;采用用户反馈的优化方式,使得查询效率得到显著提高。
附图说明
图1是本发明的实施步骤流程图;
图2为基于超图的图像检索和标注系统的工作原理示意图。
具体实施方式
现结合附图和具体实施对本发明的技术方案作进一步说明:
如图1,图2所示,本发明具体实施过程和工作原理如下:
步骤(1):使用一个基于内容的图像检索引擎对图像数据集建立t-nn图,并将各图像与其视觉特征最相似的t张图像建立联系;
步骤(2):根据图像t-nn图和图像的社交关联信息,建立超图,计算其转移概率矩阵并存储到b+树中;
步骤(3):用户提交查询对象集合和k值;
步骤(4):根据用户提交的查询对象集合生成查询向量,而后在超图上进行并行的个性化pagerank查询,利用上、下界估计方法过滤超图的结点,逐步缩小pagerank查询过程中每轮迭代的候选点集合,直至得到k个结果;
步骤(5):用户对步骤(4)得到的k个结果进行评价,生成反馈信息,再根据反馈信息调整步骤(4)中的查询向量,形成新的查询向量,再重复步骤(4),最终获得新的查询结果并返回给用户。
步骤(1)中图像检索引擎基于度量空间spb树索引结构,根据mpeg-7标准提取图像的视觉特征,其中包含可度量色彩、色彩分布、色彩结构、边缘直方图和纹理五类特征,建立spb树,并对各图像进行t-nn查询,获得与其最相近的t个查询结果,进而建立t-nn图。
步骤(2)中根据图像t-nn图和图像的社交关联信息建立超图模型,其中超图种类有三种:
1)以图像t-nn图中的各图像和其t-nn图像作为一种超边;
2)以用户对图像进行标注的三元组合作为一种超边;
3)以用户对图像进行评价的多元组合作为一种超边。
步骤(2)中计算超图转移概率矩阵的具体步骤如下:
用g(v,e,w)表示一个超图,其中v是结点集合,e是超边集合,w是一个权重函数;一个超图可以用一个|v|×|e|的矩阵h表示,其中矩阵元素h(v,e)为:
其中,v为结点,e为超边;
结点v的度d(v)可以表示为:
d(v)=∑e∈e|v∈ew(e)=∑e∈ew(e)h(v,e)
其中,w(e)表示超边e的权重;
超边e的度δ(e)可以表示为:
δ(e)=|e|=∑v∈vh(v,e)
超图的转移概率矩阵,用p来表示,则p中的元素p[u,v]表示从结点u到结点v的转移概率,其可以使用如下公式进行计算:
步骤(2)中转移概率矩阵采用批量插入方法、并行技术和缓冲技术存储到b+树中;在将转移概率矩阵并存储到b+树中时,把超图的出度结点和入度结点的组合作为键,转移概率作为值;其中:
1)使用批量插入方法将元素插入到b+树中,减少了逐个插入在查找插入位置上的重复遍历,按序插入又提升了局部性和b+树结点空间利用率,提升b+树结点插入的时间和空间效率;
2)由公式可知结点的入度边权重仅和其自身以及入度结点有关,先使用一次遍历统计结点和超边的度,然后使用并行技术计算超图转移概率提升时间效率;
3)计算超图转移概率矩阵和b+树元素插入可以并行,其间的数据流动使用一个双缓冲,两个缓冲区分别写入超图转移概率矩阵元素和读出待插入b+树的元素,若写缓冲满或读缓冲空时,交换两个缓冲区;
b+树存储于磁盘上,具有可扩展性。
步骤(3)中k是用户指定的查询返回结点个数。查询向量包含若干查询结点,各查询结点权重可由用户指定,以对查询结点有所侧重,所有查询结点的权重之和标准化为1。
步骤(4)中的个性化pagerank以查询向量和k值作为输入,在每轮迭代中,根据转移概率矩阵,结点从该结点的入度结点获得排名得分,该排名得分值为上一轮该入度结点的排名得分和转移概率的乘积。
步骤(4)中上、下界估计具体如下:
1)对于下界估计,第i轮的下界估计si[u]使用如下公式计算:
其中,c为阻尼系数(一般取0.8);,i为当前迭代轮次,si-1[u]为第i-1轮的下界估计;λi[u]为第i轮迭代中从查询节点到节点u的随机游走概率值,具体公式如下:
其中,q表示查询向量,q[u]表示结点u的权重,且∑u∈vq[u]=1;另外用c[u]来表示结点u的入度结点集合,λi-1[v]为第i-1轮迭代中从查询节点到节点v的随机游走概率值;
2)对于上界估计,第i轮上界估计
其中,pmax[u]=max{p[v,u]|v∈v}为当前结点u的所有入度转移概率的最大值;
步骤(4)中利用上、下界估计方法过滤超图的结点,具体过滤步骤如下:
(4.1)当候选点集合大小大于k时,若候选点集合中的某结点的上界估计大于当前第k大的结点下界估计,则该结点为候选点,可能出现在最终的k个结果中,否则不可能成为结果点,则抛弃;若候选点集合大小为k时,则候选点集合中所有结点为最终返回结果,候选点集合中的结点排序通过步骤(4.2)或步骤(4.3)确定;
(4.2)当候选结点集合大小为k时,若候选结点集合中某结点的下界估计均大于集合内其他结点的上界估计,或者某结点的上界估计均小于集合内其他结点的下界估计时,则该结点的排序确定,将该结点加入结果结点集合;候选结点排序全部确定时停止迭代;
(4.3)当候选结点集合大小为k时,检测当前所有候选结点的上下界估计差值,若所有结点的上下界估计差值小于设定阈值时,停止迭代,结点的排序根据下界估计降序确定。
步骤(5)中用户对步骤(4)得到的k个结果进行评价,选出其中符合其查询意愿的结果图像作为反馈节点,根据反馈节点调整步骤(4)中查询向量,将反馈结点插入原查询向量中,构成新的查询向量,对新的查询向量中的原查询结点和新插入查询结点重新进行权重分配,原查询结点总权重为0.5,新插入查询结点总权重为0.5,新插入结点平分此0.5的权重;再次进行步骤(4)中个性化pagerank查询,并使用上、下界估计方法进行过滤,最终获得新的查询结果并返回给用户。
- 还没有人留言评论。精彩留言会获得点赞!