医疗同义词的确定方法和装置与流程
本发明实施例涉及计算机应用技术领域,尤其涉及一种医疗同义词的确定方法和装置。
背景技术:
病历是医务人员对患者疾病的发生、发展、转归,进行检查、诊断、治疗等医学活动过程所作的文字记录。病历既是临床实践工作的总结,又是探索疾病规律及处理医学纠纷的法律依据,是国家的宝贵财富。
在临床医学中,有效整理病历,从中挖掘医生临床经验,对医学进步具有重大意义。但是,由于医务人员录入病历的时候,经常混杂大量不规范的同义词表述、缩写用法,甚至还有错别字,而且使用的句型不仅多样化,还可能不规范,给病历整理工作带来极大不便。若单纯依靠人工整理的方式,工作量较大,且效率较低。因此,如何识别病历中的各项内容的准确表述显得尤为重要。
技术实现要素:
本发明提供了一种医疗同义词的确定方法和装置,以解决现有的病历中表述不规范而造成的病历中的内容识别困难的问题。
第一方面,本发明实施例提供了一种医疗同义词的确定方法,该方法包括:
获取病历样本中至少一个自然语句,并对所述自然语句进行分词;
在预先建立的医学知识库中,获取与分词后的词语所对应的医学标准化用语,作为所述词语的候选同义词;
根据同一病历样本中各词语的关联关系以及所述医学知识库中各所述医学标准化术语之间的拓扑关系,从所述候选同义词中确定出各所述词语的目标同义词。
第二方面,本发明实施例还提供了一种医疗同义词的确定装置,该装置包括:
病历分词模块,用于获取病历样本中至少一个自然语句,并对所述自然语句进行分词;
候选同义词获取模块,用于在预先建立的医学知识库中,获取与分词后的词语所对应的医学标准化用语,作为所述词语的候选同义词;
目标同义词确定模块,用于根据同一病历样本中各词语的关联关系以及所述医学知识库中各所述医学标准化术语之间的拓扑关系,从所述候选同义词中确定出各所述词语的目标同义词。
本发明实施例的技术方案,通过对病历样本中的自然语句进行分词,进而在医学知识库中获取分词后各词语对应的各医学标准化术语,确定出各词语可能的候选同义词,进而通过同一病历中与各词语相关的词语,以及医学知识库中与各医学标准化术语相关的各医学标准化术语,从而进一步从各候选的各医学标准化术语中,更加精确地确定出各词语对应的医学标准化用语,即从候选同义词中确定出目标同义词,不仅解决了现有的病历中表述不规范而造成的病历中的内容识别困难的问题,能够结合医学知识,更加准确、高效地确定出各词语的目标同义词。
附图说明
为了更加清楚地说明本发明示例性实施例的技术方案,下面对描述实施例中所需要用到的附图做一简单介绍。显然,所介绍的附图只是本发明所要描述的一部分实施例的附图,而不是全部的附图,对于本领域普通技术人员,在不付出创造性劳动的前提下,还可以根据这些附图得到其他的附图。
图1为本发明实施例一所提供的一种医疗同义词的确定方法的流程示意图;
图2a为本发明实施例二所提供的一种医疗同义词的确定方法的流程示意图;
图2b为本发明实施例二所提供的一种字向量生成方法的流程示意图;
图3为本发明实施例三所提供的一种医疗同义词的确定装置的结构示意图。
具体实施方式
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
在更加详细地讨论示例性实施例之前应当提到的是,一些示例性实施例被描述成作为流程图描绘的处理或方法。虽然流程图将各步骤描述成顺序的处理,但是其中的许多步骤可以被并行地、并发地或者同时实施。此外,各步骤的顺序可以被重新安排。当其操作完成时所述处理可以被终止,但是还可以具有未包括在附图中的附加步骤。所述处理可以对应于方法、函数、规程、子例程、子程序等等。
实施例一
图1为本发明实施例一所提供的一种医疗同义词的确定方法的流程示意图。如图1所示,本实施例的方法可以由医疗同义词的确定装置来执行,该装置可通过硬件和/或软件的方式实现,并一般可独立的配置在服务器中或者由终端和服务器配合实现本实施例的方法。,
本实施例的方法具体包括:
s110、获取病历样本中至少一个自然语句,并对所述自然语句进行分词。
自然语句一般可以理解为采用自然语言撰写的句子。其中,至少一个自然语句可以是一个自然语句,也可以是两个及两个以上的自然语句。考虑到在病例样本中所记载的内容往往前后相关,可选是获取病历样本中包括两个及两个以上自然语句的段落,譬如,病历样本中所记录的现病史、病程记录以及检查报告等。可以理解的是,病历样本可以是文本病历,也可以是电子化的病历。
对自然语句进行分词,首先可以是对待处理的自然语句进行预处理,其中,预处理包括对去标点符号,去停用词等。在本实施例中,可基于字符串匹配的分词方法对自然语句进行分词,也可以基于理解的分词方法对自然语句进行分词,还可以基于统计的分词方法对自然语句进行分词。
对所述自然语句进行分词的方法有很多种,例如可以基于判别式机器学习技术来解决分词问题。判别式机器学习技术解决分词问题基于由字构词理念,将分词问题转化为分类问题,通过定义每个字的在词中的位置来确定字类别的序列预测。具体地,判别式机器学习技术主要代表有条件随机场,最大熵/隐马尔科夫最大熵、感知机,支撑向量机等。
以采用条件随机场算法进行分词为例,对自然语句进行分词具体可以是:采用条件随机场(conditionalrandomfields,crf)算法统计所述自然语句中字与字的连缀概率,并根据所述连缀概率对所述自然语句进行分词。
s120、在预先建立的医学知识库中,获取与分词后的词语所对应的医学标准化用语,作为所述词语的候选同义词。
示例性地,可以请医学专业人士预先人工整理出或者借助人工智能技术整理出各种医学标准化术语,以及各医学标准化术语的各种属性等医学知识,先录入数据库中,然后建立搜索索引,并且把相关知识条目连缀起来,生成医学知识库。即,医学知识库中存储有各医学标准化用语以及各医学标准化用语之间的拓扑关系的数据库,将各种医学术语及其拓扑关系,组成网状结构,方便存储和调用。为了便于查询,医学知识库还可以增加智能文字处理与检索功能。其中,医学知识一般有两个来源,医学文献和某一领域专家的临床经验。
医学知识库可以理解为一个)由点(vertex)和边(edge)组成的初级的医学知识图谱,其中,点用来描述医学知识库中的各医学标准化术语,譬如各种症状、各种器官和组织等;边用来描述各医学标准化术语之间的关系,,譬如“位于”、“包含”以及“数量”等等。点和边都是预先定义的有限集合。其中,各医学标准化用语之间的拓扑关系可以理解为医学知识库的边。用于描述各医学标准化用语之间的关联关系。例如,各个器官之间的位置关系以及各种症状的数量关系等。
可以理解的是,随着医学检验、医学影像、临床诊断以及康复治疗等医学技术的不断发展,医学知识也会不断的充实,为了充分发挥医学知识库的作用,可以不断地采集新生医学知识,更新医学知识库。
其中,获取与分词后的词语所对应的医学标准化用语具体可以是获取分词后的各词语的目标词向量,并计算各所述词语的所述目标词向量与预先建立的医学知识库中的医学标准化用语的词向量之间的余弦距离;根据所述余弦距离确定与所述词语所对应的医学标准化用语。需要说明的是,与分词后的词语所对应的医学标准化用语可以是一个、两个也可以是多个,即各词语的候选同义词可以是一个、两个也可以是多个。
s130、根据同一病历样本中各词语的关联关系以及所述医学知识库中各所述医学标准化术语之间的拓扑关系,从所述候选同义词中确定出各所述词语的目标同义词。
其中,同一病历样本中各词语的关联关系可以是根据各词语的语义向量进行确定,也可以是在在解析病历样本时统计医学词的共现关系。以同一病历样在解析病历样本时统计医学词的共现关系为例,假设在同一份病历中,既出现了症状词“食欲不振”,也出现了疾病词“胃炎”,与化验指标“白细胞计数超标”,与药品“三九胃泰”,则表示“食欲不振”与“胃炎”有共现关系,“食欲不振”与“白细胞计数超标”有共现关系,“食欲不振”与“三九胃泰”有共现关系,进而可以将该病历样本称为共现病历。
进一步地,如果“食欲不振”与“胃炎”的共现病历的数量很高,则可表示“食欲不振”与“胃炎”有很强的共现关系。我们把共现关系很强的关键词,称为邻居。在这个例子中,“食欲不振”的邻居是“胃炎”、“白细胞计数超标”、“三九胃泰”。其中,共线关系的强弱可以通过判断共现病历的数量是否达到或者超过预设的数量阈值来确定,若是,则确定共现关系很强。
各医学标准化术语之间的拓扑关系可以在解析完病历样本后,从医学知识库中进行查询。若发现症状词“纳差”与疾病“胃炎”,症状词“纳差”与化验指标“白细胞计数超标”,症状词“纳差”与药品“三九胃泰”,之间有直接或间接的连边,则可以确定为“纳差”与“胃炎”有拓扑关系,“纳差”与“白细胞计数超标”有拓扑关系,“纳差”与“三九胃泰”有拓扑关系。
我们把有拓扑关系的各个医学知识库里的点也称为邻居。在上述例子中,医学知识库中的“纳差”的邻居是“胃炎”、“白细胞计数超标”、“三九胃泰”。
由此判断,“纳差”与“食欲不振”的邻居很相似,所以,“纳差”与“食欲不振”具有较强的相互替换的可能性。
本实施例的技术方案,通过对病历样本中的自然语句进行分词,进而在医学知识库中获取分词后各词语对应的各医学标准化术语,确定出各词语可能的候选同义词,进而通过同一病历中与各词语相关的词语,以及医学知识库中与各医学标准化术语相关的各医学标准化术语,从而进一步从各候选的各医学标准化术语中,更加精确地确定出各词语对应的医学标准化用语,即从候选同义词中确定出目标同义词,不仅解决了现有的病历中表述不规范而造成的病历内容识别困难的问题,能够结合医学知识,更加准确、高效地确定出各词语的目标同义词。
实施例二
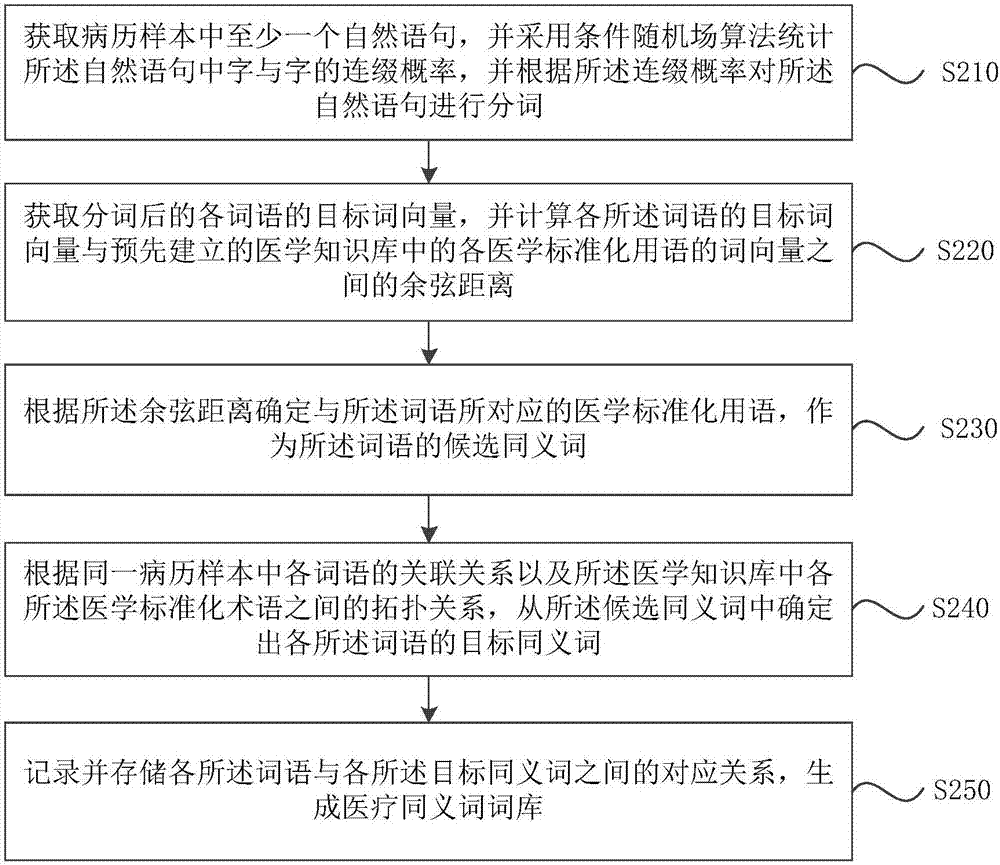
图2a为本发明实施例二所提供的一种医疗同义词的确定方法的流程示意图,如图2a所示,本实施例在上述实施例的基础上,可选是所述对所述自然语句进行分词包括:采用条件随机场算法统计所述自然语句中字与字的连缀概率,并根据所述连缀概率对所述自然语句进行分词。
在上述技术方案的基础上,进一步地,所述获取与分词后的词语所对应的医学标准化用语可包括:获取分词后的各词语的目标词向量,并计算各所述词语的所述目标词向量与预先建立的医学知识库中的医学标准化用语的词向量之间的余弦距离;根据所述余弦距离确定与所述词语所对应的医学标准化用语。
为了便于查询各词语对应的目标同义词,可选地,,在所述从所述候选同义词中确定出目标同义词之后,还包括:记录并存储各所述词语与各所述目标同义词之间的对应关系,生成医疗同义词词库。
具体地,本实施例的方法包括:
s210、获取病历样本中至少一个自然语句,并采用条件随机场算法统计所述自然语句中字与字的连缀概率,并根据所述连缀概率对所述自然语句进行分词。
条件随机场(conditionalrandomfields)由johnlafferty主要用于序列标注问题,如分词、实体识别、词性标注、浅层句法分析等问题。本实施例中,采用条件随机场算法对自然语句进行分词,具体的可以是先采用条件随机场算法统计所述自然语句中字与字的连缀概率,然后基于统计出的连缀概率对所述自然语句进行分词。
其中,统计字与字的连缀概率,具体可以是先确定当前已经出现的字之后出现的下一个字的连缀概率,由于包括相同字的词语有多个,因此可以理解的是,当前已经出现的字之后出现的下一个字有多种可能;然后,根据连缀概率确定当前已经出现的字和出现的下一个字所组成的词语是否为相同的词的概率。譬如,可以采用条件随机场先统计出“咳”字后面出现“嗽”和“痰”的连缀概率,进而可根据连缀概率判断“咳嗽”和“咳痰”是两个词的概率。
由于存在多个字即可以连缀成一个词也可以分开成为多个词的情况,此时可选是选择多个字即可以连缀成一个词的情况,即选择多个字能够连缀成的最长词。譬如,“痰中带血”四个字可以组成一个词,也可以采用“痰|中|带血”的划分方法分成“痰”、“中”、“带血”三个词,这时可选择多个字能够连缀成的最长词,即“痰中带血”。
考虑到字数越多的词,连缀概率越低,所以可不以连缀概率来分词,将连缀概率结合奖励函数,共同作为分词标准。其中,奖励函数可以根据实际需求进行选择,例如可以是,字数越多奖励函数的分值越高。
s220、获取分词后的各词语的目标词向量,并计算各所述词语的目标词向量与预先建立的医学知识库中的各医学标准化用语的词向量之间的余弦距离。
示例性地,可以采用现有的词向量获取方法直接获取分词后的各词语的目标词向量,例如可以采用word2vec、cbow(continuousbag-of-words,连续词袋模型)等语言模型获取分词后的各词语的目标词向量。
具体地,获取分词后的各词语的目标词向量可包括:采用语言模型获取分词后的词语中每个字的字向量以及该词语的词向量;将词语中每个字的字向量以及该词语的词向量进行拼接,生成所述词语的目标词向量。具体地,可以预先给病历样本中出现的每一个字,设置一个字向量,其中,字向量的初始值可以根据实际需求进行设定,也可随机取值;然后使用语言模型languagemodel根据先前出现的预设数量的字的字向量,预测下一个最有可能出现哪一个字的字向量;反复调整每一个字的字向量的取值,使得预测的准确性最高,从而得到所有字的字向量。其中,预设数量可以由根据实际情况进行设定或调整,具体数值在此并不做限定。
其中,预测可以理解为估算词库中所有词语,哪一个词语在下一个出现的概率最大。若当前预测的词语与下一个出现的词语相同,即预测很准,则语言模型中的诸多参数就不需要调整。若预测不准确,则可以通过调整相应的参数,提高后续预测的精准度。
如图2b所示,采用语言模型获取分词后的词语中每个字的字向量具体可以是,首先采用一位有效编码方法随机设置病例样本中每个字的初级字向量;然后,根据将各个字的初级字向量输入卷积神经网络,经过预先设置好的隐藏层的处理,生成并输出中级字向量;进而,以卷积神经网络输出的中级字向量作为输入量,输入lstm模型,经过lstm模型隐藏层的处理,输出各个字的高级字向量,作为分词后的词语中每个字的字向量。
类似地,可以预先给海量病历中出现的每一个词语,设置一个词向量;然后采用语言模型languagemodel反复调整每一个词的词向量的取值,从而获得所有词的词向量。采用语言模型将词语对应到词向量的好处在于,词向量是数字向量,能够较为方便地通过计算数字向量之间的余弦距离,确定出各词语中的同义词。
把每一个词语中所有字的字向量整合起来,再与该词语的词向量拼接在一起,生成能够反映用字特点的目标词向量。采用本技术方案获取的目标词向量,与没有拼接字向量而直接获取的词向量相比,不仅能够反映该词语的语义,也能反映该词语的用字特点。
考虑到病例样本的自然语句中,可能会出现大量的相同的词语表述,为了避免重复计算同一词语的词向量,具体地,可预先建立的医学词向量词库,在医学词向量词库中,查询获取自然语句中每一个词语的词向量。具体地,预先建立的医学词向量词库可包括:采集历史病历样本,计算所述历史病历样本中的每个字的字向量;基于分词器将所述历史病历样本中的每个历史语句进行分词,并根据所述字向量计算分词后各历史词语的词向量;根据各所述历史词语的词向量建立所述医学词向量词库。
类似地,可以获取预先建立的医学知识库中的各医学标准化用语,计算出各医学标准化用语的词向量,进而根据各历史词语的词向量建立医学术语词向量词库。当然,可以将各历史词语的词向量以及各医学标准化用语的词向量存储于同一词向量词库中。
s230、根据所述余弦距离确定与所述词语所对应的医学标准化用语,作为所述词语的候选同义词。
余弦距离也可称为余弦相似度,是用向量空间中两个向量夹角的余弦值衡量两个个体间差异的大小,通过余弦定理计算两个向量的夹角,确定两个向量方向是否一致。如果夹角越接近零,那么这两个向量就越相近。可以理解为,各词语的目标词向量与各医学标准化用语的词向量之间的余弦距离越接近于零,则表示该词语与该医学标准化用语之间互为近义词的可能性越大。本实施例中,根据各词语的目标词向量与各医学标准化用语的词向量之间的余弦距离,计算词与词之间的相似性,把相似的词聚类在一起,作为候选的同义词。
s240、根据同一病历样本中各词语的关联关系以及所述医学知识库中各所述医学标准化术语之间的拓扑关系,从所述候选同义词中确定出各所述词语的目标同义词。
s250、记录并存储各所述词语与各所述目标同义词之间的对应关系,生成医疗同义词词库。
由于在不同的病例样本中,自然语句表达方式可能存在差异,用词也不一定统一,因此,可以理解的是,各词语与各目标同义词之间的对应关系可以是一一对应的关系,也可以是多对一、一对多或者多对多的关系。可以根据预设的规则记录并存储各词语与各目标同义词之间的对应关系,进一步地,还可以结合预设搜索方法以及搜索结果推荐方法,方便用户进行查询使用。
类似地,随着医学检验、医学影像、临床诊断以及康复治疗等医学技术的不断发展,医学知识也会不断的充实,同时病例样本也在不断地增加,为了充分发挥医疗同义词词库的作用,可以不断地更新医疗同义词词库。
在本发明实施例的技术方案的基础上,可以进一步地,对获取到的各词语以及各词语对应的目标同义词进行校对。既可以采用人工校对的方式,也可以采用人工智能技术进行校正,还可将人工智能技术与人工校对有效结合,以保证准确率的同时,大幅度降低人工校对的工作量。
本实施例的技术方案,不仅能够达到上述各技术方案的有益效果,而且通过自然语句中字与字的连缀概率对所述自然语句进行分词,能够充分结合用字习惯对自然语句的分词,进而基于各词语的目标词向量与各医学标准化术语的词向量之间的余弦距离,然后各词语对应的医学标准化术语作为候选同义词,能够快速便捷地确定出候选同义词,进而再从候选同义词中选出目标同义词,最后,基于各词语与各目标同义词之间的对应关系生成医疗同义词词库,以便进行同义词查询或者额各词语对应的医学标准化用语查询,有利于病历记载地标准化、规范化发展。
实施例三
图3为本发明实施例三所提供的一种医疗同义词的确定装置的结构示意图。该装置可通过硬件和/或软件的方式实现,并一般可独立的配置在服务器中或者由终端和服务器配合实现本实施例的方法。如图3所示,本实施例的医疗同义词的确定装置包括:病历分词模块310、候选同义词获取模块320和目标同义词确定模块330。
其中,病历分词模块310,用于获取病历样本中至少一个自然语句,并对所述自然语句进行分词;候选同义词获取模块320,用于在预先建立的医学知识库中,获取与分词后的词语所对应的医学标准化用语,作为所述词语的候选同义词;目标同义词确定模块330,用于根据同一病历样本中各词语的关联关系以及所述医学知识库中各所述医学标准化术语之间的拓扑关系,从所述候选同义词中确定出各所述词语的目标同义词。
本实施例的技术方案,通过对病历样本中的自然语句进行分词,进而在医学知识库中获取分词后各词语对应的各医学标准化术语,确定出各词语可能的候选同义词,进而通过同一病历中与各词语相关的词语,以及医学知识库中与各医学标准化术语相关的各医学标准化术语,从而进一步从各候选的各医学标准化术语中,更加精确地确定出各词语对应的医学标准化用语,即从候选同义词中确定出目标同义词,不仅解决了现有的病历中表述不规范而造成的病历内容识别困难的问题,能够结合医学知识,更加准确、高效地确定出各词语的目标同义词。
在上述各技术方案的基础上,所述病历分词模块具体可用于:
采用条件随机场算法统计所述自然语句中字与字的连缀概率,并根据所述连缀概率对所述自然语句进行分词在上述各技术方案的基础上所述候选同义词获取模块具体可用于:
余弦距离计算单元,用于获取分词后的各词语的目标词向量,并计算各所述词语的所述目标词向量与预先建立的医学知识库中的医学标准化用语的词向量之间的余弦距离;
医学标准化用语确定单元,用于根据所述余弦距离确定与所述词语所对应的医学标准化用语。
在上述各技术方案的基础上,所述余弦距离计算单元具体可用于:
采用语言模型获取分词后的词语中每个字的字向量以及该词语的词向量;
将词语中每个字的字向量以及该词语的词向量进行拼接,生成所述词语的目标词向量。
在上述各技术方案的基础上,所述医疗同义词的确定装置还可以包括:
医疗同义词词库生成模块340,用于在从所述候选同义词中确定出目标同义词之后,记录并存储各所述词语与各所述目标同义词之间的对应关系,生成医疗同义词词库。
上述装置可执行本发明实施例一和实施例二所提供的方法,具备执行上述方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本发明实施例一和实施例二所提供的方法。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!