基于多粒度语义块的实体属性和属性值提取方法与流程
本发明属于Web挖掘和信息抽取技术领域,涉及一种基于多粒度语义块的实体属性和属性值提取方法及系统。本发明在信息检索、主题检测、自动问答等领域具有广阔的应用前景。
背景技术:
实体属性和属性值知识提取是Web挖掘和信息抽取领域的重要研究课题。实体属性和属性值知识提取是指从文本中抽取实体、属性及其属性值三元组。
实体属性和属性值知识提取方法包括三类:基于规则的方法、基于统计的方法以及混合方法。基于规则的方法主要是根据网页的组织结构规则、页面内容的布局规则、自然语言的词汇句法规则来抽取知识。该方法的特点是不受领域限制,准确率较高,需要人工构建规则。卢汉等提出了一种基于属性元性质和正则表达式的数量型属性值提取方法(基于元性质的数量型属性值自动提取系统的实现.计算机研究与发展,2010)。Sanchez研制了一种基于模式和搜索引擎的方法来获取目标概念的属性和属性值(A Methodology to Learn Ontological Attributes from the Web,Data and Knowledge Engineering,2010)。
基于统计的方法主要是利用统计度量或分类方法来抽取知识,该方法的特点是召回率较高,需要人工标注训练样本。Poesio等采用了一种基于分类器的属性提取方法(Identifying Concept Attributes Using a Classifier.The ACL-SIGLEX Workshop on Deep Lexical Acquisition,2005)。张铭等采用支持向量机和隐马尔科夫模型混合的方法来抽取论文的元数据信息(SVM+BiHMM:基于统计方法的元数据抽取混合模型,软件学报,2008)。
混合方法是基于规则和基于统计的方法的融合。Wong等针对以列表型文本为主的半结构化网页,提出了一种基于贝叶斯学习的信息抽取方法(Learning to Adapt Web Information Extraction Knowledge and Discovering New Attributes via a Bayesian Approach.IEEE Transactions on Knowledge and Data Engineering,2010)。
上述现有的实体属性和属性值知识提取方法主要是从结构化网页和以列表型文本为主的半结构化网页中抽取属性知识,对从以自由文本或非结构化文本为主的网页中获取属性知识研究较少。目前属性知识提取方法以抽取实体给定属性的属性值为主,对抽取实体的未给定属性及其属性值的研究较少。
现有实体属性知识提取方法主要以词语为粒度表示实体属性和属性值,导致属性值表达语义不完整;难以满足对同一知识不同粒度表示的需求服务。因此,迫切需要一种从自由文本或非结构化文本为主的网页中获取实体的未给定属性及其属性值的方法,以提供高质量的知识服务。
技术实现要素:
本发明的目的是为解决现有实体属性和属性值知识提取方法的属性值语义不完整、难以提取未给定属性及其属性值、以及难以满足不同粒度知识需求服务等问题,提出一种基于多粒度语义块的实体属性和属性值提取方法。该方法从以非结构化文本为主的网页中提取实体的未给定属性及其属性值。
本发明的目的是通过以下技术方案实现的。
一种基于多粒度语义块的实体属性和属性值提取方法,包括如下步骤:
步骤1,构建实体的属性和属性值提取语料集;
采用网络爬虫爬取词条网页并对网页进行自由文本提取,而后保存到本地计算机,构建为实体的属性和属性值提取语料以供后续步骤使用。
步骤2,对属性和属性值提取语料集中自由文本的句子进行分词、词性标注和短语识别;
利用分词和词性标注工具对句子进行分词和词性标注,另外,利用短语识别工具对句子进行短语识别。
步骤3,对属性和属性值提取语料集中自由文本的句子进行语义角色标注;
语义角色是指句子中以谓语动词为中心的担当一个意义完整的语义成分。采用语义角色标注工具对句子进行语义角色标注。
步骤4,对属性和属性值提取语料集中自由文本的句子进行依存句法分析;
依存句法分析是指通过分析词语之间的依存关系来描述句子的句法结构。采用依存句法分析工具进行依存句法分析。
步骤5,对属性和属性值提取抽取语料集中自由文本的句子进行语义依存分析;
语义依存分析是指分析词语之间的语义关联,目标是挖掘词语的语义信息。采用语义依存分析工具进行语义依存分析。
步骤6:根据句子的分词、词性标注和语义角色标注结果,提取以语义角色为粒度的候选实体、属性和属性值,获取候选实体、属性和属性值三元组。
作为优选,本步骤通过以下过程实现:对于句子中的动词x1,若字符串y1为动词x1的表示主体的语义角色,则将字符串y1识别为候选实体;然后通过以下过程识别属性和属性值:
第一,若字符串z1为动词x1的表示客体的语义角色,则将字符串z1识别为候选属性值,将动词x1识别为候选属性,即得到候选实体、属性和属性值三元组(y1,x1,z1);
第二,若字符串z1为动词x1的除了主体和客体以外的语义角色s,则将字符串z1识别为候选属性值,候选属性为动词x1和语义角色s的组合,即得到候选实体、属性和属性值三元组(y1,x1+s,z1);所述s可能为时间、地点、程度、频率、方式、原因、条件、方向、扩展、主题、谓语动词、受益人、持有者、被持有、并列参数或附加标记语义角色,x1+s表示动词x1和语义角色s的组合。
步骤7:根据句子的分词、词性标注、短语识别和依存句法分析结果,提取以短语为粒度的候选实体、属性和属性值,获取候选实体、属性和属性值三元组。
作为优选,本步骤通过以下过程实现:
首先,根据步骤2句子的短语识别结果,获取句子的非嵌套式短语识别结果。句子的非嵌套式短语识别结果是指不存在一短语内部包含另一短语的识别结果。句子的短语类型包括名词短语、动词短语、副词短语、形容词短语、限定词短语、量词短语、介词短语、方位词短语、修饰关系短语,以及所属关系短语。作为优选,获取句子的非嵌套式短语识别结果的过程如下:第一,对于名词短语、形容词短语、限定词短语、介词短语、量词短语、修饰关系短语、所属关系短语和方位词短语中任一短语嵌套另外短语的情形,则只保留最长字符串的短语标记,称为最长短语;第二,若一动词短语嵌套动词或另一动词短语,则去掉前一动词短语的标记;若一动词短语嵌套除了动词短语的其他短语,则保留动词短语的标记。
然后,对于句子依存句法分析结果中主谓关系SBV(y2,x2)和动宾关系VOB(y2,z2),将字符串x2所在的最长短语u识别为候选实体,将字符串y2识别为候选属性,将字符串z2所在的最长短语v识别为候选属性值。也就是,获取候选实体、属性和属性值三元组(u,y2,v)。
步骤8:根据句子的分词、词性标注和语义依存分析结果,提取以词语为粒度的候选实体、属性和属性值,获取候选实体、属性和属性值三元组。
作为优选,本步骤通过以下过程实现:首先,对于句子中的动词x3,若词语y3与动词x3具有施事关系、当事关系、感事关系、领事关系、属事关系、或比较关系,则将词语y3识别为候选实体,然后通过以下两种方式获取属性和属性值:
第一,若词语z3与该动词x3具有受事关系、客事关系、成事关系、源事关系、涉事关系、或类事关系,则将词语z3识别为候选属性值。进一步,将动词x3识别为候选属性。由此,获取候选实体、属性和属性值三元组(y3,x3,z3)。
第二,若词语z3与该动词x3具有依据、缘故、意图、结局、方式、工具、材料、时间、空间、历程、趋向、范围、数量、频率、顺序、描写、程度、或宿主等关系r,则将该词语z3识别为候选属性值。进一步,候选属性为动词x3和依存关系r的组合。也就是,获取候选实体、属性和属性值三元组(y3,x3+r,z3)。其中,x3+r表示动词x3和依存关系r的组合。
步骤9:利用经训练的分类器对候选实体、属性和属性值三元组进行正确和错误分类;
作为优选,本步骤通过以下过程实现:
首先,在利用经训练的分类器进行分类前通过下述过程使用训练语料集训练分类器:
所述训练语料集可以从上述语料集中选取;
步骤9.1:通过以下过程构建词语、短语和语义角色三种粒度的实体、属性和属性值的种子三元组:首先,根据语料集中句子的分词、词性标注和语义依存分析结果,人工构建基于词语粒度的实体、属性和属性值种子三元组;其次,根据语料集中句子的分词、词性标注、短语识别和依存句法分析结果,人工构建基于短语粒度的实体、属性和属性值种子三元组;最后,根据语料集中句子的分词、词性标注和语义角色识别结果,人工构建基于语义角色粒度实体、属性和属性值种子三元组。
步骤9.2:通过以下过程构建训练样本:
对于实体、属性和属性值的种子三元组(e,a,v),在语料集中搜索包含字符串e,a,v的句子,其中e表示实体,a表示属性,v表示属性值;若能够从句子中提取三元组(e,a,v),则将该句子标注为正例训练句子,否则标注为负例训练句子。
步骤9.3:从正例训练句子和负例训练句子中提取分类特征,构建训练句子的特征向量;
分类特征包括:候选属性a和候选属性值v的左相邻和右相邻的三个词语及其词性;候选属性a和候选属性值v的顺序关系;候选属性a和候选属性值v的依存句法关系;候选属性a和候选属性值v间隔的词语的数目。
训练句子的特征向量为句子的所有分类特征的特征值构成的向量;分类标签为1或0,当句子为正例训练句子时,设分类标签为1;否则为0。
本实施例使用的分类器为支持向量机分类器。
然后,利用上述训练好的分类器通过以下过程进行识别:
步骤9.4:对于通过步骤6~步骤8提取的候选实体、属性和属性值三元组所在的句子,从该句子中按步骤9.3所述内容提取分类特征,构建该句子的特征向量。
步骤9.5:利用支持向量机分类器对候选实体、属性和属性值三元组所在句子的特征向量进行分类,类别包括1和0,分别表示候选三元组正确和候选三元组错误。
至此,就完成了本方法的全部过程,类别标注为1的候选三元组即是我们需要的实体属性和属性值知识自动提取结果。
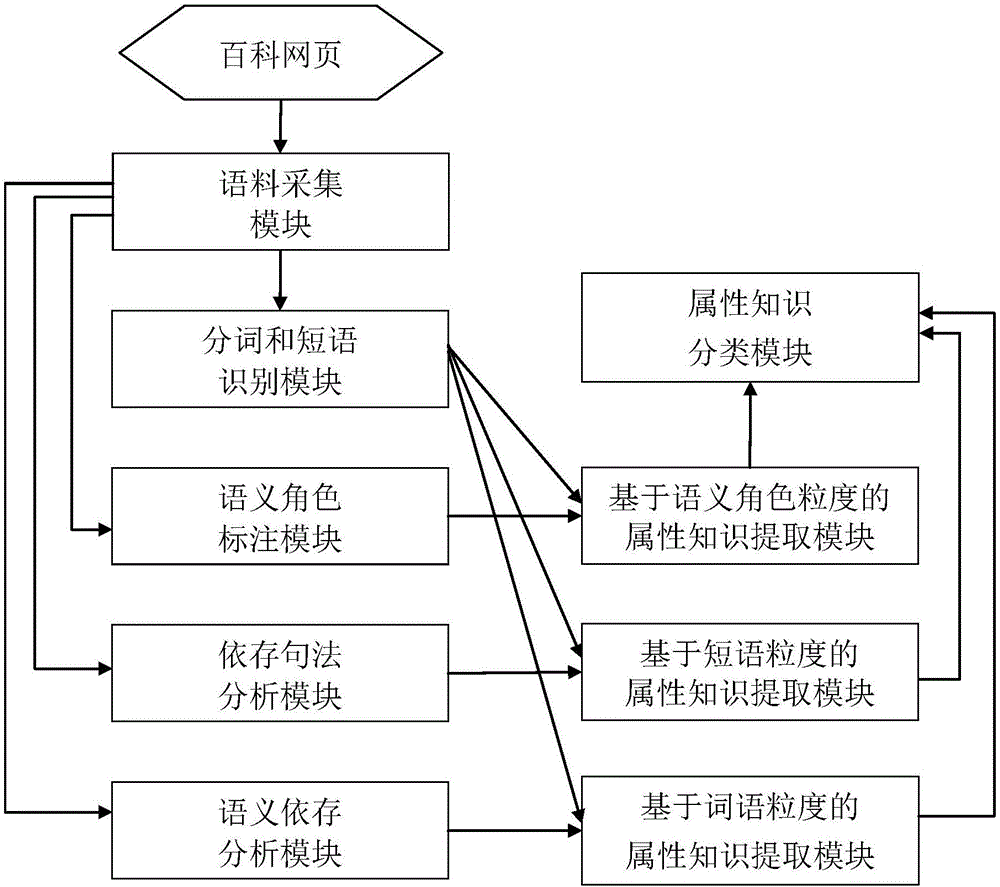
基于上述方法构建的一种基于多粒度语义块的实体属性和属性值提取系统,包括语料采集模块、分词和短语识别模块、语义角色标注模块、依存句法分析模块、语义依存分析模块、基于语义角色粒度的属性知识提取模块、基于短语粒度的属性知识提取模块、基于词语粒度的属性知识提取模块,以及属性知识分类模块;语料采集模块分别与分词和短语识别模块、语义角色标注模块、依存句法分析模块、语义依存分析模块相连;分词和短语识别模块、语义角色标注模块分别与基于语义角色粒度的属性知识提取模块相连;分词和短语识别模块、依存句法分析模块分别与基于短语粒度的属性知识提取模块相连;分词和短语识别模块、语义依存分析模块分别与基于词语粒度的属性知识提取模块相连;基于语义角色粒度的属性知识提取模块、基于短语粒度的属性知识提取模块、基于词语粒度的属性知识提取模块分别与属性知识分类模块相连。
所述语料采集模块用于采集网络上的词条网页,并进行自由文本提取,构建为后续模块从中提取实体的属性和属性值的语料;
所述分词和短语识别模块用于对所述语料采集模块提取的自由文本的句子进行分词、词性标注和短语识别;
所述语义角色标注模块用于对所述语料采集模块提取的自由文本的句子进行语义角色标注;
所述依存句法分析模块用于对所述语料采集模块提取的自由文本的句子进行依存句法分析;
所述语义依存分析模块用于对所述语料采集模块提取的自由文本的句子进行语义依存分析;
所述基于语义角色粒度的属性知识提取模块用于对所述分词和短语识别模块和语义角色标注模块标注的自由文本的句子进行基于语义角色粒度的实体的属性和属性值提取;
所述基于短语粒度的属性知识提取模块用于对所述分词和短语识别模块和依存句法分析模块识别的句子进行基于短语粒度的实体的属性和属性值提取;
所述基于词语粒度的属性知识提取模块用于对所述分词和短语识别模块和语义依存分析模块识别的句子进行基于词语粒度的实体的属性和属性值提取;
所述属性知识分类模块用于使用经训练的分类器对所述语义角色粒度的属性知识提取模块、短语粒度的属性知识提取模块、词语粒度的属性知识提取模块提取的候选实体、属性和属性值进行分类判别。
有益效果
本发明的方法,针对现有实体属性和属性值提取方法从自由文本或非结构化文本中获取属性知识研究较少;现有实体属性和属性值知识提取方法的属性值语义不完整;难以提取未给定属性及其属性值;以及难以满足不同粒度知识需求服务等问题,提供一种基于多粒度语义块的实体属性和属性值提取方法,能够提高实体属性知识获取的正确性和效率,在主题检测、信息检索、自动文摘、问答系统等领域具有广阔的应用前景。与现有技术相比,该方法具有如下特点:
(1)选取维基百科、百度百科和互动百科网页自由文本作为实体属性知识获取的来源,具有实时性、全面性和海量性的特点。
(2)将自由文本句子中词语搭配、词性链接、句法依存和语义依存特点与分类器有机地结合,融合了基于规则和基于统计方法的特点。
(3)针对现有实体属性知识提取方法主要以词语为属性和属性值表示粒度的现状,本发明采用基于短语粒度和语义角色粒度的实体属性和属性值提取方法,解决了由于词语表达意义不完整而导致的提取准确率下降的问题。
(4)针对句子表达实体属性知识的复杂性、歧义性和灵活性,本发明提取基于词语粒度、短语粒度、语义角色粒度的实体属性和属性值,提供了实体属性和属性值知识的多粒度的描述,一方面提高了实体属性知识获取的准确率和效率,另一方面用户可以根据需求选择不同粒度的实体属性知识服务。
本发明中,将实体属性知识获取问题转化为多粒度的实体属性和属性值三元组的分类问题,对处理其他来源文本具有较强的鲁棒性,能够有效地提取实体候选属性和属性值的判别特征;通过提取三种粒度的实体属性和属性值知识,提高了实体属性知识服务的效率,满足了实体属性知识多层次的服务需求。
附图说明
图1为本发明实施例一种基于多粒度语义块的实体属性和属性值提取方法的流程示意图。
图2为本发明实施例一种基于多粒度语义块的实体属性和属性值提取系统的组成结构示意图。
具体实施方式
根据上述技术方案,下面结合附图与实施例对本发明的优选实施方式进行详细说明。
实施例1
步骤1:构建实体的属性和属性值提取语料集。
采用基于Python、Selenium和PhantomJS技术的网络爬虫采集维基百科、百度百科和互动百科中的词条网页,将其保存到本地计算机,构建为实体的属性和属性值提取语料。进一步,对网页进行自由文本提取,也就是,抽取网页的标题、自由文本,去除网页中的导航和图片等信息。例如,对于实体故宫,采集该实体在维基百科、百度百科和互动百科中的词条网页,并保存在本地计算机。
步骤2,对属性和属性值提取语料集中自由文本的句子进行分词、词性标注和短语识别。
利用哈尔滨工业大学语言技术平台LTP的分词和词性标注工具或其它工具或方法对自由文本进行分词和词性标注。另外,利用斯坦福大学Stanford Parser或其它工具或方法对自由文本进行短语识别。
例如,对于句子“北京故宫于明成祖永乐四年开始建设”,使用哈尔滨工业大学语言技术平台LTP的分词和词性标注工具,分词和词性标注后的结果为:“北京(ns)故宫(ns)于(p)明(nt)成祖(v)永乐四年(nt)开始(v)建设(v)”,其中,ns表示地理名称,p表示介词,nt表示时间名词,v表示动词。使用斯坦福大学Stanford Parser对该句子进行短语识别的结果为“北京故宫(NP),于明成祖永乐四年开始建设(VP),于明成祖永乐四年(PP),明成祖永乐四年(QP),明成祖永乐(NP),四年(QP),开始建设(VP)”,其中NP表示名词短语,PP表示介词短语,QP表示量词短语,VP表示动词短语。
步骤3:对属性和属性值提取语料集中自由文本的句子进行语义角色标注。
语义角色是指以谓语动词为中心的担当一个意义完整的语义成分。采用哈尔滨工业大学语言技术平台中语义角色标注工具或其它工具或方法进行语义角色标注。
例如,对于句子“北京故宫于明成祖永乐四年开始建设”,使用哈尔滨工业大学语言技术平台LTP的语义角色标注工具,语义角色标注结果为:“北京故宫(A0),于明成祖永乐四年(TMP),建设(v)”和“开始(v),建设(A1)”,其中,A0表示动作的施事,A1表示动作的影响,TMP表示时间。
步骤4:对属性和属性值提取语料集中自由文本的句子进行依存句法分析。
依存句法分析是指通过分析词语之间的依存关系来描述句子的句法结构。采用哈尔滨工业大学语言技术平台中依存句法分析工具或其它工具或方法进行依存句法分析。
例如,对于句子“北京故宫于明成祖永乐四年开始建设”,使用哈尔滨工业大学语言技术平台LTP的依存句法分析工具,依存句法分析结果为:“ATT(故宫,北京),POB(于,明),POB(于,永乐四年),ATT(永乐四年,成祖),ADV(开始,于),SBV(开始,故宫),VOB(开始,建设),WP(开始,。)”,其中,ATT表示定中关系,POB表示介宾关系,ADV表示状中结构,SBV表示主谓关系,VOB表示动宾关系,WP表示标点。
步骤5:对属性和属性值提取语料集中自由文本的句子进行语义依存分析。
语义依存分析是指分析词语之间的语义关联,目标是挖掘词语的语义信息。采用哈尔滨工业大学语言技术平台中语义依存分析工具或其它工具或方法进行语义依存分析。
例如,对于句子“故宫位于北京中轴线的中心”,使用哈尔滨工业大学语言技术平台LTP的语义依存分析工具,语义依存分析结果为:Exp(位于,故宫),Loc(位于,中心),Sco(中轴线,北京),mAux(中轴线,的),Poss(中心,中轴线),mPunc(位于,。),其中,Exp表示当事关系,Loc表示空间角色,Sco表示范围角色,mAux表示的字标记,Poss表示领事关系,mPunc表示标点标记。
步骤6:根据句子的分词、词性标注和语义角色标注结果,提取以语义角色为粒度的候选实体、属性和属性值,获取候选实体、属性和属性值三元组。
具体过程为:对于句子中的动词x1,若字符串y1为动词x1的表示主体的语义角色,则将字符串y1识别为候选实体。例如,y1可以为施事角色。然后通过以下过程识别属性和属性值:
第一,若字符串z1为动词x1的表示客体的语义角色,则将字符串z1识别为候选属性值;将动词x1识别为候选属性。例如,z1可以为客事角色。也就是,获取候选实体、属性和属性值三元组(y1,x1,z1)。第二,若字符串z1为动词x1的除了主体和客体以外的语义角色s,则将字符串z1识别为候选属性值,候选属性为动词x1和语义角色s的组合。也就是,获取候选实体、属性和属性值三元组(y1,x1+s,z1)。这里,s可能为时间、地点、程度、频率、方式、原因、条件、方向、扩展、主题、谓语动词、受益人、持有者、被持有、并列参数、或附加标记语义角色,x1+s表示动词x1和语义角色s的组合。
例如,对于句子“北京故宫于明成祖永乐四年开始建设”,根据与动词“建设”相关的语义角色标注结果“北京故宫(A0),于明成祖永乐四年(TMP)”,由于“北京故宫”的语义角色为施事(A0表示施事),即是为表示主体的语义角色,因此,构建“北京故宫”为候选实体。进一步,因为“于明成祖永乐四年”的语义角色为时间(TMP表示时间),因此,构建“于明成祖永乐四年”为候选属性值,候选属性为动词“建设”和语义角色“时间”的组合“建设时间”。由此,构建候选实体、属性和属性值三元组(北京故宫,建设时间,于明成祖永乐四年)。
步骤7:根据句子的分词、词性标注、短语识别和依存句法分析结果,提取以短语为粒度的候选实体、属性和属性值,获取候选实体、属性和属性值三元组。
首先,根据步骤2句子的短语识别结果,获取句子的非嵌套式短语识别结果。句子的非嵌套式短语识别结果是指不存在一短语内部包含另一短语的识别结果。句子的短语类型包括名词短语、动词短语、副词短语、形容词短语、限定词短语、量词短语、介词短语、方位词短语、修饰关系短语,以及所属关系短语。
获取句子的非嵌套式短语识别结果的过程如下:第一,对于名词短语、形容词短语、限定词短语、介词短语、量词短语、修饰关系短语、所属关系短语和方位词短语中任一短语嵌套另外短语的情形,则只保留最长字符串的短语标记,称为最长短语;第二,若一动词短语嵌套动词或另一动词短语,则去掉前一动词短语的标记;若一动词短语嵌套除了动词短语的其他短语,则保留动词短语的标记。
例如:对于句子“故宫位于北京中轴线的中心”,短语识别结果如下:
也就是,句子包含名词短语NP“故宫”、动词短语VP“位于北京中轴线的中心”。该动词短语包含动词VV“位于”和名词短语NP“北京中轴线的中心”。该名词短语包括所属关系短语DNP“北京中轴线的”和名词短语NP“中心”。所属关系短语DNP“北京中轴线的”包含名词短语NP“北京”和名词短语NP“中轴线”。
该句子的非嵌套式短语识别结果的获取过程如下:由于动词短语“位于北京中轴线的中心”包含动词“位于”和名词短语“北京中轴线的中心”,因此,去掉“位于北京中轴线的中心”的动词短语标记。由于名词短语NP“北京中轴线的中心”嵌套一个所属关系短语DNP和多个名词短语NP,因此,只保留最长字符串“北京中轴线的中心”的短语标记。由此,句子的非嵌套式短语识别结果为:“故宫(NP),位于,北京中轴线的中心(NP)”。
然后,对于句子依存句法分析结果中主谓关系SBV(y2,x2)和动宾关系VOB(y2,z2),将字符串x2所在的最长短语u识别为候选实体,将字符串y2识别为候选属性,将字符串z2所在的最长短语v识别为候选属性值。也就是,获取候选实体、属性和属性值三元组(u,y2,v)。
例如:对于上述示例句子,该句子的依存句法分析结果为“SBV(位于,故宫),VOB(位于,中轴线),RAD(位于,的),ATT(中轴线,北京),ATT(中心,位于)”,其中RAD表示右附加关系。对于主谓关系“SBV(位于,故宫)”和动宾关系“VOB(位于,中轴线)”,将“故宫”所在的名词短语“故宫”识别为候选实体,将“位于”识别为候选属性,将“中轴线”所在的名词短语“北京中轴线的中心”识别为候选属性值。由此,构建候选实体、属性和属性值三元组(故宫,位于,北京中轴线的中心)。
步骤8:根据句子的分词、词性标注和语义依存分析结果,提取以词语为粒度的候选实体、属性和属性值,获取候选实体、属性和属性值三元组。
具体过程如下:首先,对于句子中的动词x3,若词语y3与动词x3具有施事关系、当事关系、感事关系、领事关系、属事关系、或比较关系,则将词语y3识别为候选实体,然后通过以下两种方式获取属性和属性值:
第一,若词语z3与该动词x3具有受事关系、客事关系、成事关系、源事关系、涉事关系、或类事关系,则将词语z3识别为候选属性值。进一步,将动词x3识别为候选属性。由此,获取候选实体、属性和属性值三元组(y3,x3,z3)。
第二,若词语z3与该动词x3具有依据、缘故、意图、结局、方式、工具、材料、时间、空间、历程、趋向、范围、数量、频率、顺序、描写、程度、或宿主等关系r,则将该词语z3识别为候选属性值。进一步,候选属性为动词x3和依存关系r的组合。也就是,获取候选实体、属性和属性值三元组(y3,x3+r,z3)。其中,x3+r表示动词x3和依存关系r的组合。本实施例中句子的依存关系类型来自哈尔滨工业大学语言技术平台。
步骤9:利用分类器对候选实体、属性和属性值三元组进行正确和错误分类,具体过程如下:
首先,在利用分类器进行分类前通过下述过程使用训练语料集训练分类器:
所述训练语料集可以从上述语料集中选取;
步骤9.1:通过以下过程构建词语、短语和语义角色三种粒度的实体、属性和属性值的种子三元组:首先,根据语料集中句子的分词、词性标注和语义依存分析结果,人工构建基于词语粒度的实体、属性和属性值种子三元组;其次,根据语料集中句子的分词、词性标注、短语识别和依存句法分析结果,人工构建基于短语粒度的实体、属性和属性值种子三元组;最后,根据语料集中句子的分词、词性标注和语义角色识别结果,人工构建基于语义角色粒度实体、属性和属性值种子三元组。
步骤9.2:通过以下过程构建训练样本:
对于实体、属性和属性值的种子三元组(e,a,v),在语料集中搜索包含字符串e,a,v的句子,其中e表示实体,a表示属性,v表示属性值;若能够从句子中提取三元组(e,a,v),则将该句子标注为正例训练句子,否则标注为负例训练句子。
步骤9.3:从正例训练句子和负例训练句子中提取分类特征,构建训练句子的特征向量;
分类特征包括:候选属性a和候选属性值v的左相邻和右相邻的三个词语及其词性;候选属性a和候选属性值v的顺序关系;候选属性a和候选属性值v的依存句法关系;候选属性a和候选属性值v间隔的词语的数目。
训练句子的特征向量为句子的所有分类特征的特征值构成的向量。
本实施例使用的分类器为支持向量机分类器。
然后,利用上述训练好的分类器通过以下过程进行识别:
步骤9.4:对于通过步骤6~步骤8提取的候选实体、属性和属性值三元组所在的句子,从该句子中按步骤9.3所述内容提取分类特征,构建该句子的特征向量。
步骤9.5:利用支持向量机分类器对候选实体、属性和属性值三元组所在句子的特征向量进行分类,类别包括1和0,分别表示候选三元组正确和候选三元组错误。
至此,就完成了从自由文中自动提取实体、属性和属性值三元组知识的全过程。
实施例2
基于上述方法构建的一种基于多粒度语义块的实体属性和属性值提取系统,如图2所示,包括语料采集模块、分词和短语识别模块、语义角色标注模块、依存句法分析模块、语义依存分析模块、基于语义角色粒度的属性知识提取模块、基于短语粒度的属性知识提取模块、基于词语粒度的属性知识提取模块,以及属性知识分类模块;语料采集模块分别与分词和短语识别模块、语义角色标注模块、依存句法分析模块、语义依存分析模块相连;分词和短语识别模块、语义角色标注模块分别与基于语义角色粒度的属性知识提取模块相连;分词和短语识别模块、依存句法分析模块分别与基于短语粒度的属性知识提取模块相连;分词和短语识别模块、语义依存分析模块分别与基于词语粒度的属性知识提取模块相连;基于语义角色粒度的属性知识提取模块、基于短语粒度的属性知识提取模块、基于词语粒度的属性知识提取模块分别与属性知识分类模块相连。
所述语料采集模块用于采集网络上的词条网页,并进行自由文本提取,构建为后续模块从中提取实体的属性和属性值的语料;
所述分词和短语识别模块用于对所述语料采集模块提取的自由文本的句子进行分词、词性标注和短语识别;
所述语义角色标注模块用于对所述语料采集模块提取的自由文本的句子进行语义角色标注;
所述依存句法分析模块用于对所述语料采集模块提取的自由文本的句子进行依存句法分析;
所述语义依存分析模块用于对所述语料采集模块提取的自由文本的句子进行语义依存分析;
所述基于语义角色粒度的属性知识提取模块用于对所述分词和短语识别模块和语义角色标注模块标注的自由文本的句子进行基于语义角色粒度的实体的属性和属性值提取;
所述基于短语粒度的属性知识提取模块用于对所述分词和短语识别模块和依存句法分析模块识别的句子进行基于短语粒度的实体的属性和属性值提取;
所述基于词语粒度的属性知识提取模块用于对所述分词和短语识别模块和语义依存分析模块识别的句子进行基于词语粒度的实体的属性和属性值提取;
所述属性知识分类模块用于使用经训练的分类器对所述语义角色粒度的属性知识提取模块、短语粒度的属性知识提取模块、词语粒度的属性知识提取模块提取的候选实体、属性和属性值进行分类判别。
为说明本发明的实体属性和属性值提取效果,以句子“北京故宫于明成祖永乐四年开始建设”和“故宫位于北京中轴线的中心”为例,本发明的基于多粒度语义块的实体属性和属性值提取方法分别提取实体、属性和属性值三元组(北京故宫,建设时间,于明成祖永乐四年)和三元组(故宫,位于,北京中轴线的中心)。基于词语或短语的实体属性和属性值提取方法分别提取实体、属性和属性值三元组(北京故宫,开始,建设)和(故宫,位于空间,中心)。从自然语言语句表达实体属性知识的角度讲,描述实体的属性和属性值知识的语义单元可能为词语、短语或语义角色。本发明不仅提取了现有方法的以词语为粒度的实体属性知识,而且提取了以短语和语义角色为粒度的实体属性知识,克服了以词语为语义单元表示实体属性值带来的表达语义不完整问题。上述表明,本发明的实体属性和属性值提取方法比现有方法更加准确,提高了用户获取实体属性和属性值知识的效率。
为了说明本发明的内容及实施方式,本说明书给出了具体实施例。在实施例中引入细节的目的不是限制权利要求书的范围,而是帮助理解本发明所述方法。本领域的技术人员应理解:在不脱离本发明及其所附权利要求的精神和范围内,对最佳实施例步骤的各种修改、变化或替换都是可能的。因此,本发明不应局限于最佳实施例及附图所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!