高通量测序数据统计方法和统计装置与流程
本发明涉及生物和计算机领域,特别涉及通过大数据技术高通量测序数据统计方法和装置。
背景技术:
基于高通量测序数据寻找和致病基因、癌症治疗、个性化用药相关的染色体突变位点为临床应用提供了不可估量的前景。由于测序技术的不断进步,获取到的数据越来越多,如何快速地处理不断增加的高通量测序数据已成为亟待解决的问题。
在获取到高通量测序数据后,需要对原始数据进行统计。目前常用的软件工具是FastQC,但是FastQC只能在单台机器上运行,运行速度较慢、运行时间较长,如一个3.8G的50基因的高通量测序数据在FastQC上需要运行6分钟以上。随着数据量的增加,FastQC消耗的处理的时间也越来越长。因此急需缩短高通量测序数据在统计环节消耗的时间,使高质量的数据能够快速地进入后续分析流程。
技术实现要素:
有鉴于此,本发明基于分布式计算框架提供了一种对高通量测序数据速度更快的统计方法和统计装置。
本发明的实施例提供了一种对高通量测序数据的统计方法,所述方法包括:
根据高通量测序数据为并行计算做准备;
对准备好的高通量测序数据进行并行计算;
将并行计算结果汇总得出统计数据。
优选地,所述根据所述高通量测序数据为并行计算做准备包括:
根据所述高通量测序数据中的碱基质量值确定碱基质量值转换方式;
对已确定碱基质量值转换方式的高通量测序数据进行切分;
生成对切分后的数据块进行并行计算的执行实体。
优选地,所述对已确定碱基质量值转换方式的高通量测序数据进行切分包括:
将包含已确定碱基质量值转换方式的文件转换为RDD;
将RDD切分为partition。
优选地,所述生成对切分后的数据块进行并行计算的执行实体包括:生成对partition进行并行计算的执行实体task。
优选地,所述对准备好的高通量测序数据进行并行计算包括:通过执行实体并行地计算每个切分后的数据块中与序列行相关的统计信息以及碱基质量值。
优选地,所述将并行计算结果汇总得出统计数据包括:根据每个切分后的数据块中与序列行相关的统计信息和碱基质量值统计所述高通量测序数据中每一列的碱基质量值分布。
本发明的实施例还提供了一种对高通量测序数据的统计装置,所述装置包括:
并行准备模块,用于根据高通量测序数据为并行计算做准备;
并行计算模块,用于对准备好的高通量测序数据进行并行计算;
结果汇总模块,用于将并行计算结果汇总得出统计数据。
优选地,所述并行准备模块包括:
碱基质量值转换方式确定单元,用于根据所述高通量测序数据中的碱基质量值确定碱基质量值转换方式;
数据切分单元:用于对已确定碱基质量值转换方式的高通量测序数据进行切分;
执行实体生成单元:用于生成对切分后的数据块进行并行计算的执行实体。
优选地,所述数据切分单元具体用于:
将包含已确定碱基质量值转换方式的文件转换为RDD;
将RDD切分为partition。
优选地,所述执行实体生成单元具体用于:生成对partition进行并行计算的执行实体task。
优选地,所述并行计算模块具体用于:通过执行实体并行地计算每个切分后的数据块中与序列行相关的统计信息以及碱基质量值。
优选地,所述结果汇总模块具体用于:根据每个切分后的数据块中与序列行相关的统计信息和碱基质量值统计所述高通量测序数据中每一列的碱基质量值分布。
本发明提供的技术方案采用大数据处理技术Spark集群开发了用于对高通量测序数据进行统计的软件工具SfastQC,极大地提高了对高通量测序数据进行统计的速度:在采用12核CPU、128G内存的单机虚拟三个节点的条件下,SfastQC处理3.8G的50基因的测序数据所需时间缩短为42秒,比目前的FastQC快8倍以上。如果机器配置更高,数据量更大,那么加速效果会更加明显。
附图说明
图1为本发明实施例一提供的高通量测序数据统计方法的示意图;
图2为本发明实施例二提供的高通量测序数据统计方法的示意图;
图3为本发明实施例三提供的高通量测序数据统计方法的示意图;
图4为本发明实施例三提供的高通量测序数据统计方法绘制的箱线图;
图5为本发明实施例四提供的高通量测序数据统计装置的示意图;
图6为本发明实施例五、六提供的高通量测序数据统计方法的示意图;
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,以下将参照本发明实施例中的附图,通过实施方式清楚、完整地描述本发明的技术方案,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
在本发明的实施例中,相关名词解释如下:
高通量测序数据:用高通量测序方法获得的数据;
高通量测序:能够一次并行对几十万到几百万条DNA片段进行序列测定的测序方法;
第一阈值:在本发明的实施例中为58,在实际应用中可以根据具体情况取适当的值;
第二阈值:在本发明的实施例中为76,在实际应用中可以根据具体情况取适当的值;
第一碱基质量值转换方式:将质量行中每一位置上的ASCII码字符的ASCII码值减去第一阈值,得到对应碱基的质量值;
第二碱基质量值转换方式:将质量行中每一位置上的ASCII码字符的ASCII码值减去第二阈值,得到对应碱基的质量值。
实施例一
请参阅图1,在本发明的第一个实施例中,在根据获得的高通量测序数据为并行计算做好准备后,对数据进行并行计算,根据计算结果绘制统计图。
S101、根据高通量测序数据为并行计算做准备。
在包含高通量测序数据的FastQ文件中,每一条记录包括四行,分别为:
以“@”开头后面附加测序介绍信息的标识行;
由A、T、G、C四种碱基组成的序列行(测序仪无法识别的碱基用N表示);
“+”行(或者“+”后面附带标识行中@后面的内容,但该内容一般被省略);
由ASCII码字符组成的质量行(质量行和序列行长度相等且质量行中的ASCII码字符与序列行中的碱基一一对应,质量行中每一位置的ASCII码字符代表与其对应的序列行中对应位置的碱基质量值)。
将包含原始高通量测序数据的FastQ文件切分为多个数据块,为并行计算做准备。
S102、对准备好的高通量测序数据进行并行计算。
根据实际需求对多个数据块进行并行计算,例如:计算每个碱基的质量值、高通量测序数据的序列行长度等等。
S103、将并行计算结果汇总得出统计数据。
将多个数据块并行计算得出的多个中间结果汇总,得到最终统计数据,并根据这些统计数据绘制相应的高通量测序数据统计图。
实施例二
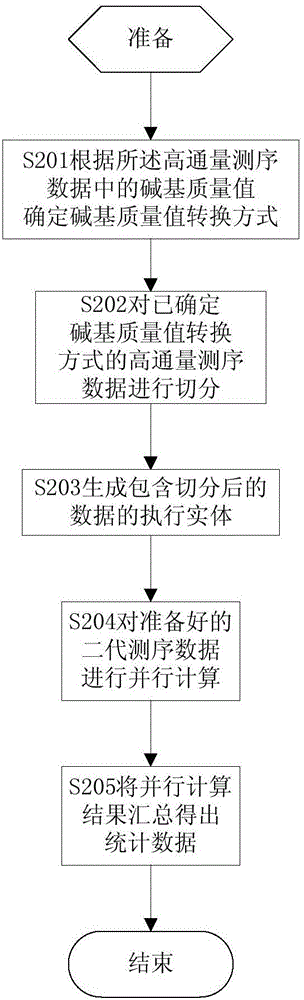
请参阅图2,在本发明的第二个实施例中,使用Hadoop并行计算框架对高通量测序数据进行并行计算,将多台计算机上并行计算的结果进行合并,得到最终统计数据并绘制统计图。
在本实施例中,相关名词解释如下:
Hadoop:由Apache基金会所开发的分布式并行计算框架。
HDFS(Hadoop Distributed File System):由Hadoop实现的一个分布式文件系统。
S201、根据所述高通量测序数据中的碱基质量值确定碱基质量值转换方式。
输入包含原始高通量测序数据的FastQ文件,在FastQ文件中,每一条记录包括四行,其中序列行由A、T、G、C四种碱基组成(测序仪无法识别的碱基用N表示);质量行由ASCII码字符组成,质量行和序列行长度相等,质量行中每一位置上的ASCII码字符代表与其对应的序列行中的碱基的质量。
根据读入的FastQ文件质量行中的碱基质量值确定本文件对应的碱基质量值转换方式:
如果读取到大于第一阈值且小于等于第二阈值的碱基质量值,则忽略此值,继续读入下一位置的碱基质量值;
如果读取到小于等于第一阈值的碱基质量值,则确定本文件对应第一碱基质量值转换方式,选择碱基质量值转换方式的过程结束;
如果读取到大于第二阈值的碱基质量值,则确定本文件对应第二碱基质量值转换方式,选择碱基质量值转换方式的过程结束。
S202、对已确定碱基质量值转换方式的高通量测序数据进行切分。
HDFS将输入的FastQ文件根据一定的规则切分成小数据块并保存。切分规则如下:例如输入文件为3G,在Hadoop中将一个数据块的大小设置为128M,那么输入文件总共将被切分为3*1024/128=24块。
S203、生成包含切分后的数据的执行实体map task。
在Hadoop集群中,参与并行计算的多台计算机并行地读取HDFS中的小数据块,并启动一个job,job为每一个小数据块生成一个map task。Map task是并行计算的执行实体。
S204、对准备好的高通量测序数据进行并行计算。
Hadoop在参与并行计算的多台计算机上并行地运行map task。Map task以小数据块为单位进行统计(如统计每个小数据块中的碱基总数,或碱基的GC含量等),并根据实际需要对每个小数据块进行计算(如计算碱基质量值等),然后把对每个小数据块的统计和计算结果写到HDFS中。
S205、将并行计算结果汇总得出统计数据。
Hadoop根据用户指定的数量生成多个reduce task。Reduce task从HDFS中读取map task对每个小数据块的统计和计算结果,并将其进行合并,得出最终统计数据,然后根据最终统计数据绘制相应的高通量测序数据统计图。
实施例三
请参阅图3,在本发明的第三个实施例中,使用spark并行计算框架对高通量测序数据进行并行计算,将多台计算机上并行计算的结果进行合并,得到最终统计数据并绘制统计图。
S301、根据所述高通量测序数据中的碱基质量值确定碱基质量值转换方式。
输入包含原始高通量测序数据的FastQ文件,在FastQ文件中,每一条记录包括四行,其中序列行由A、T、G、C四种碱基组成(测序仪无法识别的碱基用N表示);质量行由ASCII码字符组成,质量行和序列行长度相等,质量行中每一位置上的ASCII码字符代表与其对应的序列行中对应位置的碱基质量值。
根据读入的FastQ文件质量行中的碱基质量值确定本文件对应的碱基质量值转换方式:
如果读取到大于第一阈值且小于等于第二阈值的碱基质量值,则忽略此值,继续读入下一位置的碱基质量值;
如果读取到小于等于第一阈值的碱基质量值,则确定本文件对应第一碱基质量值转换方式,选择碱基质量值转换方式的过程结束;
如果读取到大于第二阈值的碱基质量值,则确定本文件对应第二碱基质量值转换方式,选择碱基质量值转换方式的过程结束。
S302、将包含已确定碱基质量值转换方式的文件转换为RDD;将RDD切分为partition。
在读取FastQ文件时,spark先将其转换为RDD,在生成RDD时用户可以根据实际需要指定将RDD切分为partition的数量。例如输入文件为3G,设置将RDD切分为24个partition,那么每一个partition所占存储空间为3*1024/24=128M。实际生成的partition的数量最少为(该文件所占存储空间/128M),如果指定的partition数量少于(该文件所占存储空间/128M),则实际将生成(该文件所占存储空间/128M)个partition。Spark根据用户指定的partition数量将RDD切分成若干partition。
在本实施例中:
Spark:是UC Berkeley AMPLab开发的一种计算框架。
RDD是指弹性分布式数据集(Resilient Distributed Datasets),它是可容错的并行数据结构,使用户能够显式地在内存中保存中间的运算结果,通过控制RDD的分区来优化数据的布局,并使用丰富的转换算子进行操作。
Partition是指spark在计算过程中,生成的数据在计算空间内的最小单元。
S303、生成对partition进行并行计算的执行实体task。
在本实施例中:
Job是指包在spark中含由多个stage组成的并行计算,对RDD执行action操作后会生成job;
Stage是指在spark中,一个job会根据处理过程的需要而分成不同的阶段即stage,stage由多个task组成;
Task是指被送到为某个应用启动的executor进程的工作单元。
在spark中对RDD进行action操作时生成DAG Scheduler(有向无环图调度器),从而启动一个job。对一个job内的操作,根据处理过程是否需要shuffle分成不同的stage,并在每一个stage内产生一系列的task。通常一个RDD内的task数量与partition的数量相同。后续多个执行实体task将在多台计算机上对不同的partition执行并行计算过程。
S304、通过执行实体task并行地计算每个partition中与序列行相关的统计信息以及碱基质量值。
在多台计算机上通过多个执行实体task并行地对每个partition进行以下计算:
对高通量测序数据中每个记录的序列行计数得到该记录的序列总数、计算每个记录的序列行中的碱基总数和碱基中的GC含量;
计算碱基质量值:
如果本次并行计算数据对应的是第一碱基质量值转换方式,则将质量行中每一位置上的ASCII码字符的ASCII码值减去第一阈值即为对应的碱基质量值;
如果本次并行计算数据对应的是第二碱基质量值转换方式,则将质量行中每一位置上的ASCII码字符的ASCII码值减去第二阈值,即为对应的碱基质量值。
S305、根据每个partition中与序列行相关的统计信息和碱基质量值统计所述高通量测序数据中每一列的碱基质量值分布。
将所有partition中的序列数累加得出序列总数;统计所有partition中的序列长度得出序列长度范围;将所有partition中的碱基数累加得出碱基总数;将所有partition中的碱基质量值累加并除以碱基总数得出每一列碱基质量平均值;将所有partition中的碱基G和C的数量累加并除以碱基总数得到碱基GC含量。
根据每个partition中的计算结果统计高通量测序数据中每一列的碱基质量值分布:10%点、上四分位数(25%点)、中位数(50%点)、下四分位数(75%点)和90%点。
根据上述统计数据生成结果文件,此结果文件包括原始高通量测序数据文件的名称、序列总数、序列长度范围、碱基总数、平均碱基质量值、GC碱基含量和每一列的碱基质量值分布;根据每一列的碱基质量值分布即每一列碱基质量值的10%点、上四分位数(25%点)、中位数(50%)、下四分位数(75%点)、90%点和平均值绘制箱线图(箱线图是利用数据中的上述五个统计量来描述数据的一种方法,根据箱线图可以大致看出数据是否具有有对称性,分布的分散程度等信息,特别可以用于对几个样本的比较)。如图4所示例,在本实施例的箱线图中,纵坐标为碱基质量值,分布在0到42之间;横坐标为碱基位置坐标,即高通量测序数据中的序列长度。
实施例四
如图5所示,本发明的第四个实施例提供了一种高通量测序数据的统计装置,所述装置包括:
并行准备模块510,用于根据高通量测序数据为并行计算做准备;
并行计算模块520,用于对准备好的高通量测序数据进行并行计算;
结果汇总模块530,用于将并行计算结果汇总得出统计数据。
在本实施例中,并行准备模块510将包含原始高通量测序数据的FastQ文件切分为多个数据块,为并行计算做准备。并行计算模块520根据实际需求对多个数据块进行并行计算。将多个数据块并行计算得出的多个中间结果汇总,得到最终统计数据,结果汇总模块530并根据这些统计数据绘制相应的高通量测序数据统计图。
实施例五
如图6所示,本发明的第五个实施例提供了一种高通量测序数据的统计装置,所述装置包括:
并行准备模块610,用于根据高通量测序数据为并行计算做准备;
并行计算模块620,具体用于通过执行实体并行地计算每个切分后的数据块中与序列行相关的统计信息以及碱基质量值。
结果汇总模块630,具体用于根据每个切分后的数据块中与序列行相关的统计信息和碱基质量值统计所述高通量测序数据中每一列的碱基质量值分布。
所述并行准备模块610包括:
碱基质量值转换方式确定单元6101,用于根据所述高通量测序数据中的碱基质量值确定碱基质量值转换方式;
数据切分单元6102:用于对已确定碱基质量值转换方式的高通量测序数据进行切分;
执行实体生成单元6103:用于生成对切分后的数据块进行并行计算的执行实体。
在本实施例中,并行准备模块610中的碱基质量值转换方式确定单元6101根据输入的高通量测序数据中的碱基质量值确定碱基质量值转换方式。并行准备模块610的数据切分单元6102对已确定碱基质量值转换方式的高通量测序数据进行切分。并行准备模块610中的执行实体生成单元6103生成包含切分后的数据的执行实体map task。并行计算模块620通过map task以小数据块为单位并行地进行统计和计算。结果汇总模块630通过reduce task将多个计算机上对每个小数据块的统计和计算结果进行合并,得到最终统计数据,并根据最终统计数据绘制相应的高通量测序数据统计图。
实施例六
如图6所示,本发明的第六个实施例提供了一种高通量测序数据的统计装置,所述装置包括:
并行准备模块610,用于根据高通量测序数据为并行计算做准备;
并行计算模块620,用于对准备好的高通量测序数据进行并行计算;
结果汇总模块630,用于将并行计算结果汇总得出统计数据。
所述并行准备模块610包括:
碱基质量值转换方式确定单元6101,用于根据所述高通量测序数据中的碱基质量值确定碱基质量值转换方式;
数据切分单元6102,具体用于将包含已确定碱基质量值转换方式的文件转换为RDD;将RDD切分为partition。
执行实体生成单元6103,用于生成对partition进行并行计算的执行实体。
所述并行计算模块620,具体用于通过执行实体task并行地计算每个partition中与序列行相关的统计信息以及碱基质量值。
所述结果汇总模块630,具体用于根据每个partition中与序列行相关的统计信息和碱基质量值统计所述高通量测序数据中每一列的碱基质量值分布。
在本发明的第六个实施例中,并行准备模块610中的碱基质量值转换方式确定单元6101根据输入的高通量测序数据中的碱基质量值确定碱基质量值转换方式。并行准备模块610的数据切分单元6102将包含已确定碱基质量值转换方式的文件转换为RDD;将RDD切分为partition。并行准备模块610中的执行实体生成单元6103生成对partition进行并行计算的执行实体task。并行计算模块620通过执行实体task并行地计算每个partition中与序列行相关的统计信息以及碱基质量值。结果汇总模块630根据每个partition中与序列行相关的统计信息和碱基质量值统计所述高通量测序数据中每一列的碱基质量值分布,并绘制箱线图。
本领域普通技术人员可以理解,实现上述本发明实施例中的高通量测序数据统计方法和统计装置可以通过程序指令相关的硬件来完成,所述的程序可以存储于可读取存储介质中,该程序在执行时执行上述方法中的对应步骤。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原来的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!