一种基于深度残差网络和LSTM的图像理解方法与流程
本发明涉及图像语义理解、深度学习领域,特别是一种基于深度残差网络和LSTM(Long Short-term Memory)的图像理解方法。
背景技术:
图像理解是指对图像语义的理解。它是以图像为对象,知识为核心,研究图像中何位置有何目标、目标之间的相互关系、图像是何场景的一门科学。
图像理解输入的是图像数据,输出的是知识,属于图像处理研究领域的高层内容。其重点是在图像目标识别的基础上进一步研究图像中各目标的性质及其相互关系,并得出对图像内容含义的理解以及对原来客观场景的解释,进而指导和规划行为。
目前常用的图像理解方法主要是基于底层特征与分类器相结合的方法,先使用小波变换、尺度不变特征变换(SIFT)、边缘提取等图像处理算法对图像进行特征提取,然后使用潜在狄利克雷分布(LDA)、隐马尔科夫模型(HMM)、支持向量机(SVM)等图像识别和推理算法对提取出的特征进行分类识别并建立语义模型。从算法实现上来看,目前常用的图像理解算法存在泛化性差、鲁棒性低、局部依赖性强、实现困难、识别率低等缺点。
技术实现要素:
本发明公布了一种基于深度残差网络和LSTM的图像理解方法,该方法利用了深度残差网络在图像特征提取和LSTM对时序序列建模方面的优势,深度残差网络和LSTM模型成了一个编码-解码框架,将图像内容信息转化成自然语言,达到提取图像的深层次信息的目的。
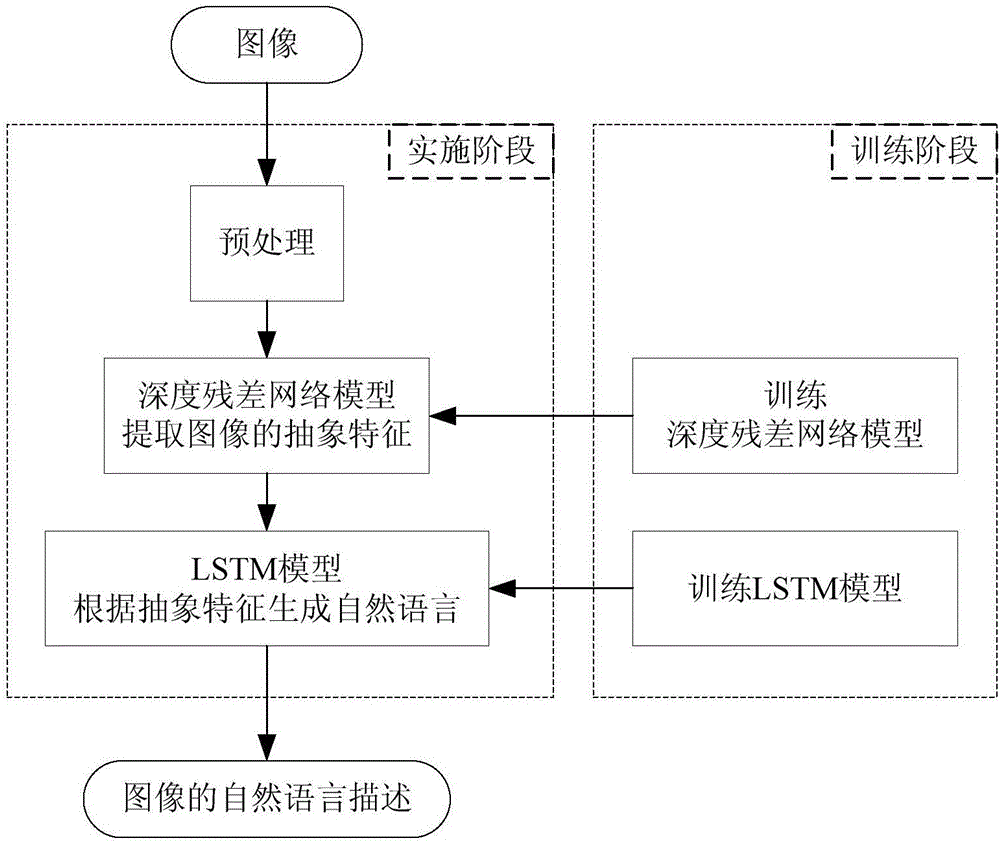
本发明的目的通过以下的技术方案实现:基于深度残差网络和LSTM的图像理解方法,其特征在于:应用于从输入图像中提取抽象特征的深度残差网络模型、根据抽象特征生成自然语言的LSTM模型;具体包括如下步骤:
S1:下载训练数据集;
S2:对步骤S1数据集中的数据进行预处理;
S3:训练深度残差网络模型;
S4:训练LSTM模型;
S5:用步骤S3中训练好的深度残差网络模型提取待识别图像的抽象特征;
S6:将步骤S5中提取的特征输入到步骤S4训练好的LSTM模型中,LSTM模型根据特征生成自然语言。
优选的,步骤S1中下载训练数据集:分别从http://www.image-net.org、http://mscoco.org这两个网站下载ImageNet、MS-COCO公共图像数据集;ImageNet数据集分为训练图像集和测试图像集,MS-COCO数据集分为训练图像集合测试图像集,对应的,每张图片有5个用于描述其内容信息的自然语言语句。
优选的,步骤S2预处理包括对ImageNet数据集和MS-COCO数据集两种情况:
对于ImageNet数据集:每一张图像,将图像缩放到256×256大小,然后从图像上中下左右5处截取5张大小为224×224的标准尺寸图像,并将标准尺寸图像与其相对应的类别成对保存,一个“标准尺寸图像-类别”对作为一个数据;
对于MS-COCO数据集,预处理的步骤如下:
S2.1、将每一个自然语言语句与其对应的图像成对保存,一个“图像-自然语句”对作为一个数据;
S2.2、将“图像-自然语句”对中的图像维持长宽比不变并缩放,剪成224×224的标准尺寸图像,并将标准尺寸图像与其相对应的类别成对保存,一个“标准尺寸图像-自然语句”对作为一个数据;
S2.3、统计所有自然语句中出现过的单词,去重,排序,单词总个数记为K;将每个单词都用1×K的列向量来表示,列向量中下标为单词序号处置1,其他位置0,这样一个向量称为单词向量,所有的“单词-单词向量”对构成一个长度为K的字典DIC;
S2.4、将“图像-自然语句”对中的自然语句用基于字典DIC的单词向量表示,一个长度为C的自然语句y可以表示为:
优选的,步骤S3中训练深度残差网络模型:包含46个卷积块(用“conv+下标”表示)、2个池化层、1个全连接层和1个softmax分类器;在每个卷积块中,先用批归一化(BN)方法对数据归一化,然后使用修正线性单元(ReLu)对数据进行非线性变换,最后进行卷积操作。训练时使用随机梯度下降(SGD)和反向传播方法(BP),用预处理后的ImageNet数据集(“标准尺寸图像-类别”对)作为样本;对于每个样本,标准尺寸图像在网络中向前传播,经过softmax层后输出预测类别,再将预测类别与实际类别的差异反向传播到网络头部,反向传播过程中使用随机梯度下降算法调整网络参数。重复样本输入的过程,直到网络收敛。
优选的,步骤S4中训练LSTM模型:LSTM模型的基本结构由LSTM神经元构成。LSTM模型包含C层LSTM神经元(C为预先设定的自然语句的最大长度),能依次输出C个单词;这里使用的是预处理后的MS-COCO数据集(“标准尺寸图像-自然语句”对)作为样本;训练LSTM模型步骤如下:
S4.1、将标准尺寸图像输入到步骤S3的深度残差网络中,从conv5_3_c卷积块末端提取抽象特征矩阵,大小为7*7*2048=49*2048,用表示;
S4.2、对于每一时刻t,根据以下公式动态生成一个图像内容向量:
eti=fatt(ai,ht-1)
其中,ai是抽象矩阵a中的向量,ht-1是上一时刻的隐藏状态量,fatt是一个基于多层感知机的注意力模型,能够自动确定时刻t更注意的抽象特征,αti是与ai对应的权重,是动态生成的图像内容向量;
S4.3、对于每一时刻t,LSTM神经元的前向传导过程可以表示为:
ht=ottanh(ct)
其中,σ是sigmoid函数,σ(x)=(1+e-x)-1,it、ft、ct、ot、ht分别表示t时刻输入门、遗忘门、记忆单元、输出门、隐藏层所对应的状态变量;Wi、Ui、Zi、Wf、Uf、Zf、Wo、Uo、Zo、Wc、Uc、Zc为LSTM模型学习到的权重矩阵,bi、bf、bc、bo是LSTM模型学习到的偏置项,是一个随机初始化的嵌入矩阵,m是一个常数,yt-1是上一时刻LSTM模型输出的单词;t=0时的ct、ht按下面公式初始化:
其中,fiinit,c、fiinit,h是两个独立的多层感知机;
S4.4、对于每一时刻t,通过最大化下面式子来求得输出的单词yt:
其中,λ是一个常数,C是样本中自然语句的最大长度;
S4.5、根据交叉熵损失计算预测自然语句和样本中自然语句的差异,然后使用反向传播算法(BP)和基于RMSProp的随机梯度下降(SGD)算法训练,令交叉熵最小。
S4.6、对于MS-COCO数据集中的每一个样本,重复S4.1-S4.5步骤。
S4.7、重复S4.1-S4.6步骤20次。
优选的,步骤S5中提取待识别图像的特征的具体步骤为:
S7.1:使用步骤S2中对Imagenet数据集的图像进行预处理;
S7.2:将预处理后的图像输入到步骤S3训练好的深度残差网络中,从最底层卷积块末端提取抽象特征矩阵,大小为7*7*2048=49*2048。
优选的,步骤S6中LSTM模型根据图像特征生成自然语句,对于每一时刻t,其中0≤t<C,使用步骤S4.1-S4.4生成一个单词,所有单词依次连接构成自然语句。
本发明与现有技术相比,具有如下优点和有益效果:
1、本方法采用深度学习理论,使用大量图像样本训练深度残差网络模型和LSTM模型,能自动学习到图像中的普遍模式,鲁棒性强,适用范围广。
2、本发明方法采用的深度残差网络具有50层的极深结构,能够充分提取图像中的抽象特征;同时,本发明方法采用了LSTM模型,能够恰当地对自然语言等时序序列建模,将特征向量转化成自然语言。深度残差网络与LSTM网络结合,显著提升了图像理解的准确度。
3、本发明引入了一种动态注意机制,能够根据深度残差网络提取到的特征矩阵动态的生成合适特征向量,使得LSTM具有动态聚焦到图像的不同位置的优点。
附图说明
图1为本发明实施例的一种基于深度残差网络和LSTM的图像理解方法的具体流程图;
图2为本发明实施例的一种基于深度残差网络和LSTM的图像理解方法中步骤(3)的深度残差网络模型结构;
图3为本发明实施例的一种基于深度残差网络和LSTM的图像理解方法中步骤(3)的深度残差网络模型中卷积块的具体结构;
图4为本发明实施例的一种基于深度残差网络和LSTM的图像理解方法中步骤(4)的LSTM模型中LSTM神经元的结构。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1所示为本发明的方法流程图,包括如下步骤:
(1)、下载训练数据集:分别从http://www.image-net.org、http://mscoco.org这两个网站下载ImageNet、MS-COCO公共图像数据集。ImageNet数据集分为训练图像集和测试图像集,训练图像集含有1000个类别的图片,每个类别1300张,测试图像集含50000张图片;MS-COCO数据集分为训练图像集合测试图像集,训练图像集包含82783张图片,测试图像集包含40504张图片,对应的,每张图片有5个用于描述其内容信息的自然语言语句。
(2)、预处理:
对于ImageNet数据集:每一张图像,将图像缩放到256×256大小,然后从图像上中下左右5处截取5张大小为224×224的标准尺寸图像,并将标准尺寸图像与其相对应的类别成对保存,一个“标准尺寸图像-类别”对作为一个数据;
对于MS-COCO数据集,预处理的步骤如下:
2.1、将每一个自然语言语句与其对应的图像成对保存,一个“图像-自然语句”对作为一个数据;
2.2、将“图像-自然语句”对中的图像维持长宽比不变并缩放,剪成224×224的标准尺寸图像,并将标准尺寸图像与其相对应的类别成对保存,一个“标准尺寸图像-自然语句”对作为一个数据;
2.3、统计所有自然语句中出现过的单词,去重,排序,单词总个数记为K;将每个单词都用1×K的列向量来表示,列向量中下标为单词序号处置1,其他位置0,这样一个向量称为单词向量,所有的“单词-单词向量”对构成一个长度为K的字典DIC;
2.4、将“图像-自然语句”对中的自然语句用基于字典DIC的单词向量表示,一个长度为C的自然语句y可以表示为:
(3)、训练深度残差网络模型:深度残差网络结构如图2所示,包含46个卷积块(用“conv+下标”表示)、2个池化层、1个全连接层和一个softmax分类器。在每个卷积块中,先用批归一化(BN)方法对数据归一化,然后使用修正线性单元(ReLu)对数据进行非线性变换,最用进行卷积操作。训练时使用随机梯度下降(SGD)和反向传播方法(BP),用预处理后的ImageNet数据集(“标准尺寸图像-类别”对)作为样本。具体参数已在图2中标明,例如,“conv2_1_a,1*1,64,1”表示该卷积块名称为conv2_1_a,卷积核大小为1×1,步长为1,输出64个特征图。
(4)、训练LSTM模型:图4所示的是LSTM模型的基本结构由LSTM神经元组成。LSTM模型包含C层LSTM神经元(C为预先设定的自然语句的最大长度),能依次输出C个单词。这里使用的是预处理后的MS-COCO数据集(“标准尺寸图像-自然语句”对)作为样本。训练LSTM模型步骤如下:
4.1、将标准尺寸图像输入到步骤(3)的深度残差网络中,从conv5_3_c卷积块末端提取抽象特征矩阵,大小为7*7*2048=49*2048,用表示;
4.2、对于每一时刻t,根据以下公式动态生成一个图像内容向量:
eti=fatt(ai,ht-1)
其中,ai是抽象矩阵a中的向量,ht-1是上一时刻的隐藏状态量,fatt是一个基于多层感知机的注意力模型,能够自动确定时刻t更注意的抽象特征,αti是与ai对应的权重,是动态生成的图像内容向量;
4.3、对于每一时刻t,LSTM神经元的前向传导过程可以表示为:
ht=ottanh(ct)
其中,σ是sigmoid函数,σ(x)=(1+e-x)-1,it、ft、ct、ot、ht分别表示t时刻输入门、遗忘门、记忆单元、输出门、隐藏层所对应的状态变量。Wi、Ui、Zi、Wf、Uf、Zf、Wo、Uo、Zo、Wc、Uc、Zc为LSTM、模型学习到的权重矩阵,bi、bf、bc、bo是LSTM模型学习到的偏置项,是一个随机初始化的嵌入矩阵,m是一个常数,yt-1是上一时刻LSTM模型输出的单词;t=0时的ct、ht按下面公式初始化:
其中,finit,c、finit,h是两个独立的多层感知机;
4.4、对于每一时刻t,通过最大化下面式子来求得输出的单词yt:
其中,λ是一个常数,C是样本中自然语句的最大长度;
4.5、根据交叉熵损失计算预测自然语句和样本中自然语句的差异,然后使用反向传播算法(BP)和基于RMSProp的随机梯度下降(SGD)算法训练,令交叉熵最小。
4.6、对于MS-COCO数据集中的每一个样本,重复4.1-4.5步骤。
4.7、重复4.1-4.6步骤20次。
(5)、用步骤(3)中训练好的深度残差网络模型提取待识别图像的抽象特征。首先使用步骤(2)中对Imagenet数据集的图像进行预处理,然后将预处理后的图像输入到步骤(3)训练好的深度残差网络中,从最底层卷积块末端提取抽象特征矩阵,大小为7*7*2048=49*2048。
(6)、将步骤(5)中提取的抽象特征输入到步骤(4)训练好的LSTM模型中,对于每一时刻t,其中0≤t<C,使用步骤S4.1-S4.4生成一个单词,所有单词依次连接构成自然语句。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!