一种鲁棒的车牌、车标识别方法与流程
本发明涉及智能交通领域,具体地,涉及一种鲁棒的车牌、车标识别方法。
背景技术:
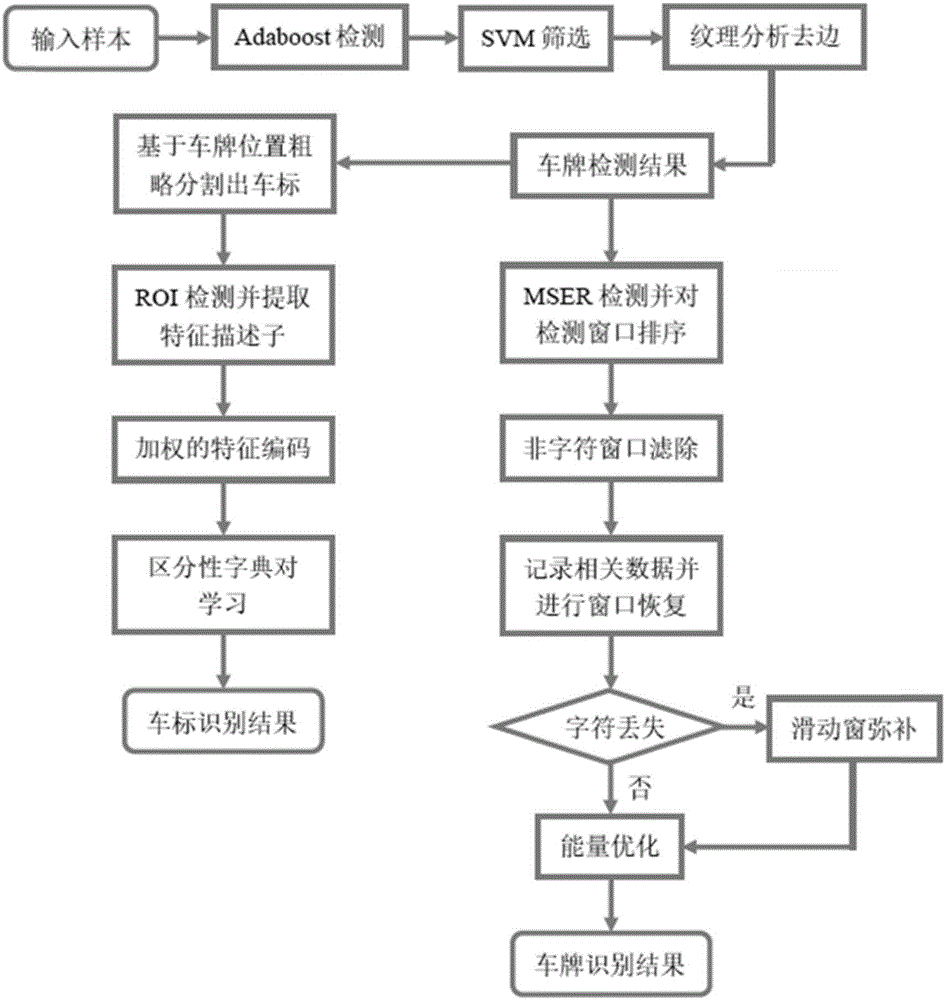
:近年来,随着人们生活品质的逐步提升,汽车的需求量也日益增大。为了提高道路交通管理效率,有效应对盗车、违规驾驶等交通问题,智能交通系统应运而生,其关键技术包括车牌和车标识别。车牌是车辆的唯一标识,自动并正确地识别车牌有利于提高交通与车辆管理效率。然而,仅仅依靠车牌识别技术并不足以解决日趋复杂的交通问题。车标作为区分不同汽车厂商最显著的标识,可以有效弥补车牌识别技术存在的不足,大大提升系统的可靠性。车牌识别方法通常包括车牌检测、字符分割、字符识别等步骤。Thanongsak等提出一种基于车牌模式和监督学习的4层反向传播神经网络,识别率达96%。Menotti等的卷积神经网络与SVM相结合的方法,精度达96%以上。Sharma等利用小波变换获取特征,结合多类径向基的神经网络的方法,定位精度为97.6%,识别率达98.8%。王毅等人提出一种基于HVS色彩模型结合Adaboost的车牌检测方法,定位成功率达98.1%。但是由于拍摄视角、光照、分辨率、场景等因素的影响,在现有方法中。字符分割往往是整个方法的关键,常用的方法有垂直投影法,连通域分析法等,其效果直接决定着后续的识别。然而,车牌污损、不清晰等因素使得传统的过于依赖字符分割的方法性能大大降低。在车标识别方面,现有的一些方法有:Sam等的径向切比雪夫的方法,识别率达92%,但其测试样本较少,代表性不强;Zhang等的模板匹配的方法,识别率达95%;Llorca等的HOG+SVM的方法,识别率达92.6%;Psyllos等的基于Merge-SIFT特征的方法,识别率达94.6%,但对低分辨率的情况效果不好;Yu等的基于Bag-of-Words的方法,识别率达97.3%,其样本为分割较好、仅包含车标的图像,对于实际中粗略分割的样本鲁棒性差。Huang等的基于预训练的卷积神经网络的方法,识别率达99.07%。虽然,上述方法取得了不错的效果,但大多是基于已经定位分割得比较理想的车标样本,而目前现有方法在车标定位上的准确率往往还不能令人满意,从而使这些依赖于准确定位分割的方法难以有效处理实际应用中包含复杂背景的车标图片。技术实现要素:为了克服上述现有技术的不足,本发明首先提出一种鲁棒的车牌识别方法。该方法具有鲁棒性强、避免过于依赖字符分割的优点。本发明还提出一种鲁棒的车标识别方法,该方法对于不精确的车标定位具有较好的鲁棒性。为了实现上述目的,本发明的技术方案为:一种鲁棒的车牌识别方法,包括车牌检测阶段和车牌识别阶段,在车牌检测阶段实现车牌区域的定位,基于定位后的车牌图像再进行车牌识别,其中车牌识别阶段具体实现过程为:11)对定位后车牌区域进行灰度化;12)利用最大稳定极值区域MSER检测方法在灰度化的车牌区域中寻找最大稳定极值区域,并对其检测结果进行候选字符窗口的排序,具体是根据每个候选字符窗口左上角起点的横坐标进行排序;13)对MSER的检测结果进行非字符窗口的初步滤除;14)记录并保存初步过滤后的每个候选字符窗口的置信度、中心点坐标以及宽和高,进而得到该特定车牌的字符宽、高均值;15)利用保存的中心点坐标以及特定车牌的字符宽、高的均值进行字符窗口恢复;16)利用基于滑动窗的检测方法和该特定车牌字符宽、高的均值,进一步检测MSER方法可能漏检的字符;17)利用能量优化的方法对候选字符窗口进行识别,输出最终车牌识别的结果;能量优化方程如下式所示:其中,x={xi|i=1,2,...,n}为窗口类标的集合,xi表示第i个窗口的类标,Ei(xi)=1-p(xi|ci)为一元项,表示自能量,其中ci表示第i个窗口,p(xi|ci)为窗口ci属于xi类的概率。Eij(xi,xj)为二元项,表示互能量,当xi与xj均为背景类时,Eij(xi,xj)=0,否则Eij(xi,xj)=λexp(-[100-Overlap(xi,xj)]2),其中Overlap(xi,xj)表示窗口之间重叠部分占窗口总面积的百分数,λ为调整互能量权重的参数,ε表示互有交集的窗口对的集合。车牌检测阶段的具体实现过程为:21)用Adaboost检测器对车牌样本进行检测,获取若干个候选区域;22)利用SVM分类器对Adaboost检测结果进行筛选,找出置信度最高的区域;23)对SVM的筛选结果进行纹理分析,确定车牌的边界,获取精确定位的车牌区域;24)对纹理分析的结果进行判定,基于下面的公式,当θ>0.8时,则没有过分割,保留基于纹理分析的定位结果,否则拒绝基于纹理分析的定位结果,保留SVM筛选及精确定位后的结果;其中AreaTexture_analysis表示基于纹理分析去边处理后车牌区域的面积,AreaSVM表示SVM筛选及精确定位后车牌区域的面积。一种基于所述车牌识别方法的车标识别方法,包括以下步骤:31)根据车标与车牌位置关系的先验知识,以及精确定位的车牌位置坐标,获得车标所在的大致区域;32)利用Adaboost检测器在大致区域中进行车标检测,获得车标的候选区域(记为ROI),在这些ROI的并集区域内等间隔地提取局部描述子;接着对所有ROI进行加权,构建权值图,具体过程如下:构建一张尺寸与输入图像I相同的辅助权值图W,令Ri∈S为第i个ROI的像素位置集合,S为输入图像中所有ROI的集合,RI为输入图像中所有像素位置的集合,对于每一个Ri,利用下式计算其权值分布,其中,|Ri|表示Ri中所有像素的数量,(x,y)表示像素的坐标。假设每个ROI同等重要,利用下式合并图片中所有ROI的权重分布,从而构建出完整的权值图;33)利用加权的特征编码方式对车标样本进行表达,具体过程如下:设为提取的局部描述子特征向量集合,l为特征维数,N为特征向量的个数。利用K-means生成一个包含M个聚类的码本求解与特征向量yi相对应的编码向量ci,如下式:其中,符号⊙表示逐个元素相乘,λ为调节保真度和规范化之间平衡的参数;di刻画yi与码本B中各码字bj的相似关系,用于调节ci的局部性,由下式求得:其中,||yi,B||=[||y1,b1||,||y2,b2||,...,||yi,bM||]T,||yi,bj||表示yi与bj之间的欧式距离,参数σ用于调整局部性;为了提高编码效率,对每个yi∈Y,选出使其欧式距离||yi,B||最小的前K个码字,构成局部基向量矩阵对应的编码向量通过下式最小化求解:接着,利用学习得到的权值图W对局部编码向量进行加权,如下式所示:ci←W(x,y)ci即利用(x,y)处的权值W(x,y)来加权与该处描述子所对应的编码向量ci;接着,需要对加权后的编码向量进行最大值池化,如下式:c=max(c1,c2,...,cN)其中max执行逐分量的最大化操作。引入空间金字塔结构在多个尺度下对编码向量进行分区域的池化处理。金字塔被分成L层,在第r层(r=1,2,...,L),图像的特征空间会被分成2r-1×2r-1个矩形区域,在其中每个矩形区域内提取l维池化的编码向量。将每层的特征向量全部串联起来构成最终维的向量。34)利用区分性字典对学习(DDPL)方法对编码特征进行识别并输出结果:设X=[X1,X2,...,XK]为包含K类的训练样本集,为第k类的子集,p为特征向量维数,h为每类样本的数量。令D为所要学习的字典,A为编码系数矩阵。基于组稀疏的区分性字典对模型,目标函数定义如下式:其中,{Dk,Pk}构成了关于第k类的子字典对;Ak是第k类的的编码系数矩阵;表示除了Xk之外的所有训练样本;参数λ>0控制Pk对的表达;τ、ω为正,用于平衡对应项的贡献;mk是Ak的均值列向量,m是所有类的均值列向量,Mk是各列为mk的矩阵;di表示D的第i列,用于避免平凡解。与传统技术相比,本发明的优点有:(1)针对传统的车牌检测方法鲁棒性不强、分割出的车牌区域含有较多背景的问题,本发明提出一种结合Adaboost检测、SVM筛选以及纹理分析去边的车牌精确检测方法,对光照、视角、分辨率、场景等具有较好的鲁棒性,大大减少了检测出的车牌区域中的背景干扰。(2)针对传统的车牌识别技术过于依赖准确的字符分割的问题,本发明提出一种以最大稳定极值区域检测为主、滑动窗检测为辅,结合能量优化的车牌识别方法,能够有效检出传统的字符分割方法难以处理的车牌污损、不清晰等情况下的字符,而且使得字符检测与识别同步进行,打破传统的“先分割再识别”的模式。(3)针对传统车标识别技术对车标定位依赖较大的问题,本发明提出一种基于加权的特征编码和基于判别性字典对的稀疏表达车标识别方法,在仅提供粗定位的车标区域时也能够取得高识别率。附图说明图1为车牌检测模块实现流程图。图2为车牌识别模块实现流程图。图3为车标识别模块实现流程图。图4为本发明车牌车标识别方法的总体实现流程图。具体实施方式下面结合附图对本发明做进一步的描述,但本发明的实施方式并不限于此。本发明的车牌车标组合识别方法,具有较强的鲁棒性。其主要实现两个功能:一是对待检车辆进行车牌识别;二是对待检车辆进行车标识别。总体过程是首先检测出车牌的位置,根据先验知识获得粗分割的车标,再利用本发明的方法对车牌和车标进行识别。车牌识别和车标识别:(一)车牌识别车牌识别阶段主要包括两大模块:车牌检测阶段和车牌识别阶段。(1)车牌检测阶段,如图1;1)利用Adaboost检测器对样本进行检测,获取若干个候选区域。2)利用SVM分类器对Adaboost检测结果进行筛选,找出置信度最高的区域。3)对SVM的筛选结果进行纹理分析,通过对目标区域的前景线、前景点比例、背景线等统计,从而确定车牌的边界,最终获取精确定位的车牌区域。4)对纹理分析的结果进行判定,去除过分割的情况。如式(1)所示,当θ>0.8时,认为没有过分割,保留基于纹理分析的定位结果,否则拒绝基于纹理分析的定位结果,保留SVM筛选及精确定位后的结果;(2)车牌识别阶段,如图2;本发明中提出了一种以最大稳定极值区域检测(MSER)为主,滑动窗检测为辅,结合能量优化的车牌识别方法。具体过程如下:1)对精确定位的车牌图片灰度化。2)利用MSER方法寻找车牌中的最大稳定极值区域,并对其检测结果——即候选字符窗口,根据每个窗口左上角起点的横坐标大小进行排序;3)对MSER检测结果进行非字符窗口的初步滤除。主要分为两步:第一步,利用SVM字符分类器滤除一部分非字符窗口,主要去除一些较为明显的非字符窗口。第二步,根据字符规格特性滤除SVM无法有效去除的一些污点和局部字符。4)记录并保存每个候选字符窗口的置信度、中心点坐标以及宽和高,进而得到该特定车牌的字符宽、高均值。5)利用保存的中心点坐标以及字符宽、高的均值进行字符窗口恢复。6)利用基于滑动窗的检测方法和该特定车牌字符宽、高的均值,进一步检测MSER方法可能漏检的字符。7)利用能量优化的方法对候选字符窗口进行识别,输出最终车牌识别的结果。能量优化方程如式(2)所示。其中,x={xi|i=1,2,...,n}为窗口类标的集合,xi表示第i个窗口的类标,Ei(xi)=1-p(xi|ci)为一元项,表示自能量,其中ci表示第i个窗口,p(xi|ci)为窗口ci属于xi类的概率。Eij(xi,xj)为二元项,表示互能量,当xi与xj均为背景类时,Eij(xi,xj)=0,否则Eij(xi,xj)=λexp(-[100-Overlap(xi,xj)]2),其中Overlap(xi,xj)表示窗口之间重叠部分占窗口总面积的百分数,λ为调整互能量权重的参数。ε表示互有交集的窗口对的集合。(二)车标识别,如图3;1)车标粗定位。根据车标与车牌位置关系的先验知识,以及精确定位的车牌位置坐标,获得粗略分割的车标区域。2)感兴趣的区域(记为ROI)检测和局部描述子提取。利用Adaboost检测器在大致区域中进行车标检测,找出所有感兴趣区域,在这些ROI的并集区域内等间隔地提取局部描述子;接着对所有ROI进行加权,构建权值图,具体过程如下:构建一张尺寸与输入图像I相同的辅助权值图W。令Ri∈S为第i个ROI的像素位置集合,S为输入图像中所有ROI的集合,RI为输入图像中所有像素位置的集合。对于每一个Ri,可以利用式(3)计算其权值分布。其中,|Ri|表示Ri中所有像素的数量,(x,y)表示像素的坐标。假设每个ROI同等重要,利用式(4)合并图片中所有ROI的权重分布,从而构建出完整的权值图。3)利用加权的特征编码方式对车标样本进行表达。具体过程如下:设为提取的局部描述子特征向量集合,l为特征维数,N为特征向量的个数。利用K-means生成一个包含M个聚类的码本求解与特征向量yi相对应的编码向量ci,如式(5)所示:其中,符号⊙表示逐个元素相乘,λ为调节保真度和规范化之间平衡的参数;di刻画yi与码本B中各码字bj的相似关系,用于调节ci的局部性,由式(6)求得:其中,||yi,B||=[||y1,b1||,||y2,b2||,...,||yi,bM||]T,||yi,bj||表示yi与bj之间的欧式距离,参数σ用于调整局部性;为了提高编码效率,对每个yi∈Y,选出使其欧式距离||yi,B||最小的前K个码字,构成局部基向量矩阵对应的编码向量可以通过最小化式(7)求解:接着,利用学习得到的权值图W对局部编码向量进行加权,如式(8)所示:ci←W(x,y)ci(8)即利用(x,y)处的权值W(x,y)来加权与该处描述子所对应的编码向量ci;接着,对加权后的编码向量进行最大值池化,如式(9)所示:c=max(c1,c2,...,cN)(9)其中max执行逐分量的最大化操作。引入空间金字塔结构在多个尺度下对编码向量进行分区域的池化处理。金字塔被分成L层,在第r层(r=1,2,...,L),图像的特征空间会被分成2r-1×2r-1个矩形区域,在其中每个矩形区域内提取l维池化的编码向量。将每层的特征向量全部串联起来构成最终维的向量。4)利用本发明提出的区分性字典对学习(DDPL)方法对编码特征进行识别并输出结果。设X=[X1,X2,...,XK]为训练样本集,其中为第k类的样本子集,p为特征维数,h为每类样本的数量。令D为所要学习的字典,A为编码系数矩阵。基于组稀疏的区分性字典对模型,定义如下(10)的目标函数:其中,{Dk,Pk}构成了关于第k类的子字典对;Ak是第k类的的编码系数矩阵;表示除了Xk之外的所有训练样本;参数λ>0控制Pk对的表达;τ、ω为正,用于平衡对应项的贡献;mk是Ak的均值列向量,m是所有类的均值列向量,Mk是各列为mk的矩阵;di表示D的第i列,用于避免平凡解。(三)实验数据实验中用于Adaboost训练的车牌正样本3000张,负样本8000张;用于SVM训练的正样本2500张(与Adaboost不同),负样本4000张。用于测试的样本共3334张,其中高速公路采集的样本2495张,分辨率为1360*1024像素,拍摄时间为白天不同时段,具有不同光照、天气、背景,拍摄地点包括不同高速路口;停车场采集样本839张;分辨率为720*576像素,拍摄时间分为白天和夜晚。表1所示为本发明所提出方法在不同数据集下的车牌定位精度。表1本发明所提出方法在不同数据集下的车牌定位精度表2所示为本发明所提出车牌识别方法的整体效果。表2本发明提出车牌识别方法的整体效果表3所示为不同方法的车标识别效果。其中,CS表示使用LLC方法对车标样本进行编码,配合SVM进行分类;WCS表示使用基于加权的LLC方法进行编码,配合SVM进行分类;WCD表示使用基于加权的LLC编码,配合DDPL进行分类。表3不同方法的车标识别效果CSWCSWCD车标识别精度96.5%97.76%97.95%速度0.34/s张0.34/s张0.36/s张表4所示为整个车牌、车标识别系统的测试效果。表4整个车牌、车标识别系统的测试效果从实验结果可以看出,整个系统的车牌识别准确率为97.50%,车标识别准确率为98.16%,系统速度约为1.2s/张,能够较好的完成对车牌和车标信息的提取,而且基本可以实现实时应用的需求。同时,也充分说明了本发明的方法能够具有较好的鲁棒性和实用性。与传统技术相比,本发明的优点有:(1)对于传统的车牌检测方法鲁棒性不强、分割出的车牌四周背景冗余较多的问题,本发明提出一种基于Adaboost检测、SVM筛选,配合纹理分析去边的车牌精确检测方法,可以有效检测不同地点、光照、视角、分辨率、背景复杂度的样本,而且检测出的车标区域包含较少的背景干扰。(2)对于传统的车牌识别技术对字符分割依赖较大的问题,本发明提出一种以最大稳定极值区域检测为主、滑动窗检测为辅,配合能量优化的车牌识别方法,不仅能够有效检出传统的字符分割方法难以处理的车牌污损、不清晰等情况下的字符,而且使得字符检测与识别同步进行,打破传统的“先分割再识别”的模式。(3)对于传统车标识别技术对定位依赖较大,在处理包含复杂背景的样本时鲁棒性较低的问题,本发明提出一种基于加权的特征编码配合区分性字典对学习的车标识别方法,能够有效处理车标粗略定位、分割不好、包含复杂背景的情况,大大降低了对车标定位的依赖。以上所述的本发明的实施方式,并不构成对本发明保护范围的限定。任何在本发明的精神原则之内所作出的修改、等同替换和改进等,均应包含在本发明的权利要求保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1