基于移动用户轨迹相似性的用户分类方法和系统与流程
本发明涉及通信
技术领域:
,特别是涉及一种基于移动用户轨迹相似性的用户分类方法和系统。
背景技术:
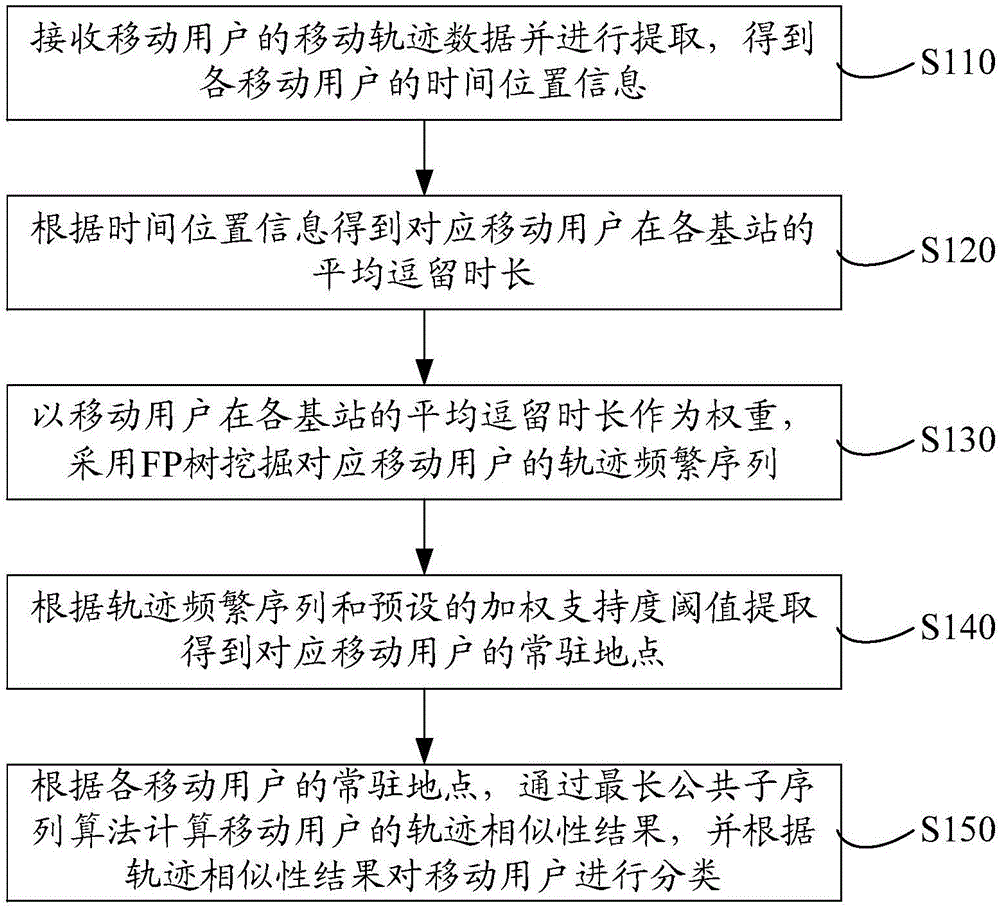
:随着移动通信和移动应用的快速发展,用户对手机的使用率及依赖性不断提高,移动运营商积累了大量移动用户实时记录的定位数据。分析移动用户位置的相似性,提取移动用户的相似路径在出行路径预测、兴趣区域发现、轨迹聚类、个性化路径推荐等领域具有广泛的应用。传统的移动用户轨迹相似性计算方法是先对用户位置进行定义建立用户-位置信息模型,然后结合时间效应利用协同过滤的算法找到区域性相似的用户。由于这种算法需要对全地市基站和用户建立矩阵,这样必然会导致稀疏矩阵的出现,数据的稀疏性为算法的执行带来灾难性的后果。传统的移动用户轨迹相似性计算方法存在计算复杂度高的缺点。技术实现要素:基于此,有必要针对上述问题,提供一种可降低计算复杂度的基于移动用户轨迹相似性的用户分类方法和系统。一种基于移动用户轨迹相似性的用户分类方法,包括以下步骤:接收移动用户的移动轨迹数据并进行提取,得到各移动用户的时间位置信息;根据所述时间位置信息得到对应移动用户在各基站的平均逗留时长;以移动用户在各基站的平均逗留时长作为权重,采用FP树挖掘对应移动用户的轨迹频繁序列;根据所述轨迹频繁序列和预设的加权支持度阈值提取得到对应移动用户的常驻地点;根据各移动用户的常驻地点,通过最长公共子序列算法计算移动用户的轨迹相似性结果,并根据所述轨迹相似性结果对移动用户进行分类。一种基于移动用户轨迹相似性的用户分类系统,包括:轨迹数据提取模块,用于接收移动用户的移动轨迹数据并进行提取,得到各移动用户的时间位置信息;逗留时长计算模块,用于根据所述时间位置信息得到对应移动用户在各基站的平均逗留时长;频繁序列挖掘模块,用于以移动用户在各基站的平均逗留时长作为权重,采用FP树挖掘对应移动用户的轨迹频繁序列;常驻地点提取模块,用于根据所述轨迹频繁序列和预设的加权支持度阈值提取得到对应移动用户的常驻地点;轨迹相似性计算模块,用于根据各移动用户的常驻地点,通过最长公共子序列算法计算移动用户的轨迹相似性结果,并根据所述轨迹相似性结果对移动用户进行分类。上述基于移动用户轨迹相似性的用户分类方法和系统,接收移动用户的移动轨迹数据并进行提取,得到各移动用户的时间位置信息。根据时间位置信息得到对应移动用户在各基站的平均逗留时长,以移动用户在各基站的平均逗留时长作为权重,采用FP树挖掘对应移动用户的轨迹频繁序列。根据轨迹频繁序列和预设的加权支持度阈值提取得到对应移动用户的常驻地点,根据各移动用户的常驻地点,通过最长公共子序列算法计算移动用户的轨迹相似性结果,并根据轨迹相似性结果对移动用户进行分类。通过对移动轨迹数据并提取得到各移动用户的时间位置信息,避免移动用户轨迹数据的稀疏性而导致相似度算法效率低下。以移动用户在各基站的平均逗留时长作为权重,采用FP树挖掘对应移动用户的轨迹频繁序列并找到移动用户的常驻地点,解决了移动用户轨迹随机性和繁杂性而导致算法效率和算法低下的问题,既能保证用户的轨迹规律,又能降低数据的数量,降低了计算复杂度。附图说明图1为一实施例中基于移动用户轨迹相似性的用户分类方法的流程图;图2为另一实施例中基于移动用户轨迹相似性的用户分类方法的流程图;图3为一实施例中基于移动用户在基站逗留时长的加权FP树示意图;图4为一实施例中基于移动用户轨迹相似性的用户分类系统的结构图;图5为另一实施例中基于移动用户轨迹相似性的用户分类系统的结构图。具体实施方式在一个实施例中,一种基于移动用户轨迹相似性的用户分类方法,如图1所示,包括以下步骤:步骤S110:接收移动用户的移动轨迹数据并进行提取,得到各移动用户的时间位置信息。移动轨迹数据具体包括移动用户发生业务的起始时间、起始基站名称、切换基站的时间、切换基站的名称、在每一个基站的逗留时长、主叫号码、被叫号码、用户发生的业务类型等数据。移动用户的轨迹一般由一系列按照时间依次排序的位置组成,Tri={(L1,t1),(L2,t2),…,(Li,ti),…,(Ln,tn)}。(Li,ti)表示用户出现在某个基站的位置Li对应的时间ti。移动用户轨迹是按照时间序列形成有序的集合,因此,在考虑时间因素的情况下,可将移动用户的轨迹抽取移动用户的时间位置序列。上述的移动用户轨迹的表示为Tri={(L1,L2,t1,t2),(L2,L3,t2,t3),…,(Li,ti,Li+1,ti+1),…,(Ln-1,tn-1,Ln,tn)}。序列中(L1,L2,t1,t2)表示移动用户在时刻t1出现在基站L1,然后在时刻t2离开基站L1前往基站L2。利用运营商的移动用户动态的、具有时间时效性的用户移动轨迹数据查找用户轨迹度,抽取移动用户的时间位置序列,按照发生业务的起始时间的顺序对每一个用户的时间位置数据。将位置序列映射为具有时间和地理位置信息的序列,以发生时间的序列表示移动用户的轨迹,避免由于轨迹稀疏性而导致算法低下的问题。步骤S120:根据时间位置信息得到对应移动用户在各基站的平均逗留时长。根据提取得到的时间位置信息可知道移动用户在各基站的出现时刻和离开时刻,可直接计算出移动用户在各基站的平均逗留时长。步骤S130:以移动用户在各基站的平均逗留时长作为权重,采用FP树挖掘对应移动用户的轨迹频繁序列。对于移动用户轨迹数据的频繁模式定义为如下形式:Li→Lj定义是一个移动用户从位置Li向位置Lj移动的规律。移动用户频繁轨迹提取是从移动用户移动轨迹数据集中提取支持度大于最小支持度阈值的集合。因此,移动用户频繁模式反映了移动用户群体在移动行为上具有相同特征或规律。本实施例中引入闭合频繁项集来保证挖掘得到的移动用户行为信息量最全面且数据规模最小。假设频繁移动模式Tpi属于频繁闭合移动模式,其必须满足:在频繁模式集中不存在任一个模式Tpj,满足且(Tpj)>=Tpi。采用频繁闭合序列模式挖掘经典算法,以基站平均逗留时间作为项目权重构建FP树,挖掘对应移动用户的轨迹频繁序列,轨迹频繁序列表征移动用户逗留各基站的权重。具体地,在一个实施例中,步骤S130包括步骤132至步骤136。步骤132:将各基站的平均逗留时长作为对应的项目权重,挖掘得到用户轨迹项集及对应的项集权重。根据用户在每一个基站的逗留时长设置每一个项目(基站)的权重,挖掘用户发生轨迹的项目项集(基站组合)得到用户轨迹项集,将用户轨迹项集的项集权重定义为各项目权重的平均值。步骤134:根据用户轨迹项集及对应的项集权重生成条件模式基。查询所有用户轨迹项集,可得知各项目在哪些用户轨迹项集中出现,统计有某一项目出现的用户轨迹项集的数量得到该项目的总计值。根据各项目的总计值降序依次为头节点和其他节点,生成条件模式基。此外,步骤132之后,步骤134之前,还可包括对用户轨迹项集的项集权重进行归一化处理的步骤,步骤134中根据归一化处理后的项集权重生成条件模式基,便于数据处理。步骤136:根据条件模式基构造对应的加权FP树,并得到对应移动用户的轨迹频繁序列。结合移动用户在各基站的平均逗留时长,根据FP树构造的思想,采用条件模式基构造对应的加权FP树,根据加权FP树导出对应移动用户的轨迹频繁序列。步骤S140:根据轨迹频繁序列和预设的加权支持度阈值提取得到对应移动用户的常驻地点。加权支持度阈值的具体取值并不唯一。根据轨迹频繁序列,按照设定的加权支持度阈值判断相应的频繁模式,获得该移动用户的用户常驻区域模式,从而得到移动用户的常驻地点。在查找常驻点过程中,采用驻留时长作为权值,有效剔除一些常去的但是逗留很短的地方(比如:地铁站、公交站等),这些地方由于用户改变交通工具而使得轨迹发生一定程度的变化。以移动用户在各基站的平均逗留时长作为权重,采用加权FP树查找用户的常驻点,解决了移动用户轨迹随机性和繁杂性而导致算法效率和算法低下的问题。步骤S150:根据各移动用户的常驻地点,通过最长公共子序列算法计算移动用户的轨迹相似性结果,并根据轨迹相似性结果对移动用户进行分类。采用传统的LCSS(LongestCommonSubsequence,最长公共子序列)算法,是通过轨迹本身计算轨迹相似度。本实施例中,在计算得到各移动用户的常驻地点之后,结合轨迹本身和移动用户出现在某个地方的时间规律计算轨迹相似度,得到移动用户的轨迹相似性结果。根据轨迹相似性结果对移动用户进行分类的具体方式并不唯一,可以是在计算得到两个移动用户的轨迹相似度之后,若轨迹相似度高于预设值,则将这两个移动用户分为同一类;还可以是在计算某一移动用户与其他所有移动用户的轨迹相似度之后,将该移动用户以及与该移动用户的轨迹相似度高于预设值的其他移动用户分为同一类。通过根据轨迹相似性结果对移动用户进行分类,将轨迹相似度高的移动用户分为同一类,以便于对通信运营商或者移动运营商不同的业务需求挖掘提供数据支持。在一个实施例中,步骤S150中根据各移动用户的常驻地点,通过最长公共子序列算法计算移动用户的轨迹相似性结果,包括步骤152至步骤156。步骤152:根据移动用户的时间位置信息,提取移动用户间的最长公共子序列以及各移动用户的常驻地点对应的时间。由于各个移动用户的时间位置信息已知,根据建立的具有时间和地理位置信息的序列可直接提取得到两个移动用户之间的最长公共子序列,以及这两个移动用户在常驻地点所对应的时间。步骤154:根据各移动用户的常驻地点对应的时间计算移动用户间的时间相似性系数。获得用户常驻区域模式的基础上,结合时间因素,以时间相似性系数反映所有用户在邻近时间在相同的地理位置的比例。具体地,本实施例中,步骤154包括:其中,COL为时间相似性系数,△T为精度,本实施例中设为1个小时。Ti(u)表示移动用户u在某一个时间精度内达到某一个基站Li(u)的时刻,Tj(v)表示移动用户v在某一个时间精度内达到某一个基站Lj(v)的时刻,δ(Li(u),Lj(v))为重合性公式,当两个用户的基站重合时值为1,否则为0。步骤156:根据移动用户间的最长公共子序列以及对应移动用户间的时间相似性系数计算得到移动用户的轨迹相似性结果。结合时间和地理的因素衡量用户轨迹的相似性,提升了用户轨迹相似度计算的精度。例如可剔除一些家里住在附近,公司是同事的用户。毕竟用户的上下班时间有一定的规律。在相似时间出现在相同地点的用户数据对商家的营销活动才具有一定的参考性,对于用车出行的商家、运营商的重入网用户的识别才有实际的意义。具体地,本实施例中,步骤156包括:其中,DLCSS表示用户u和用户v的轨迹相似性,公式的第一部分表示用户u和用户v一天的最长公共子序列,第二部分表示在每一个时间精度下,两位用户在邻近时间在相同的地理位置的比例。在一个实施例中,如图2所示,步骤S150之后,基于移动用户轨迹相似性的用户分类还可包括步骤S160。步骤S160:根据移动用户的移动轨迹数据对轨迹相似性结果进行准确性验证,得到验证结果并显示。具体可根据相似性结果关联电话号码进行正确率验证,得到验证结果并发送至显示器进行显示,以便操作人员得知相似性计算准确性。为了更好地理解上述基于移动用户轨迹相似性的用户分类方法,下面结合具体实施例进行详细的解释说明。用户移动轨迹数据的提取和预处理。随机抽取某运营商的10000名移动用户两周的轨迹数据,除了用户的发生业务的起始时间、起始基站名称、切换基站的时间、切换基站的名称、在每一个基站的逗留时长、主叫号码、被叫号码、用户发生的业务类型等。在对数据进行挖掘之前,先对数据进行预处理,剔除与求解轨迹相似度无关的字段;然后抽取用户的时间位置序列,最后按照发生业务的起始时间的顺序对每一个用户的时间位置数据。用户轨迹预处理结果具体如表1所示。移动用户号码起始时间结束时间起始基站CI结束基站CI18676445***2014060100190520140601001918235367218676445***2014060100191820140601001932672658218676445***201406010019322014060100194265823105818676445***2014060100194220140601001745424873127118676445***2014060100194820140601002008312715752218676445***2014060200101720140602001140575225752318676445***2014060200114020140602011351575235752218676445***2014060200135120140602031846575225752218676445***20140602001446201406020018465752257522表1经过对移动用户原始的轨迹处理进行预处理之后,得到每一个移动用户的时间位置信息,为下一步数据挖掘做准备。采用FP树挖掘移动用户轨迹频繁序列。对用户移动轨迹的项目以及项集的数据处理。在获取用户时间位置信息的基础上,计算移动用户在每一个基站的平均逗留时间,以此作为项目权重。项目名称及权重如表2所示。项目名称——基站ID权重——平均逗留时间(秒)2353286672306582454248767312711557522266表2从用户移动轨迹处理结果提取用户的项集X={2353,672,6582,42487,31271,57522},根据用户在每一个基站的逗留时间设置每一个项目(基站)的权重,当项目(基站)具有一个权重后,用户发生轨迹的项目项集(基站组合)的权重定义为各项目权重的平均值。用户轨迹项集及权重如表3所示。例如X={2353-42487-672-6582},用户的移动轨迹项集权重为WT(t)=(286+67+30+45)/4=107,经过归一化操作之后,该项集的归一化权重为0.1488。表3建立加权FP树。扫描表3可得到各项目{2353,672,6582,42487,31271,57522}的总计为{5,4,3,4,2,1}。结合用户在每一个基站的逗留时长,根据FP树构造的思想,得到某用户移动轨迹的加权FP树如图3所示。根据加权FP树导出用户逗留基站的权重分别是:2353:0.6558;42487:0.6558;6582:0.5487;672:0.3394;31271:0.2616;57522:0.2767。设加权支持度阈值Wminsup=0.45,根据上述的加权条件树得出的频繁模式如表4所示。表4基于LCSS算法评价移动用户轨迹相似性的结果。基于加权FP树提取移动用户的常驻地点,再结合移动用户在常驻地点的时间因素,计算的10000名移动用户工作日的轨迹相似度的结果。基于LCSS算法评价移动用户轨迹相似性的准确性如表5所示。LCSS区间用户数准确率>=0.71000065.17%>=0.61000079.73%>=0.51000088.56%>=0.41000091.17%表5在计算轨迹相似性时会剔除电话号码的字段进行相似性计算,然后根据相似性的结果再关联电话号码进行正确率验证。由表5可知,LSCC区间的合理范围在(0.4,0.5),通信运营商或者移动运营商可根据不同的业务需求挖掘不同用户之间轨迹的相似性,为营销工作提供数据支撑。上述基于移动用户轨迹相似性的用户分类方法,通过对移动轨迹数据并提取得到各移动用户的时间位置信息,避免移动用户轨迹数据的稀疏性而导致相似度算法效率低下。以移动用户在各基站的平均逗留时长作为权重,采用FP树挖掘对应移动用户的轨迹频繁序列并找到移动用户的常驻地点,解决了移动用户轨迹随机性和繁杂性而导致算法效率和算法低下的问题,既能保证用户的轨迹规律,又能降低数据的数量,降低了计算复杂度,且考虑了用户移动轨迹的规律性,贴合用户使用习惯特点。在一个实施例中,一种基于移动用户轨迹相似性的用户分类系统,如图4所示,包括轨迹数据提取模块110、逗留时长计算模块120、频繁序列挖掘模块130、常驻地点提取模块140和轨迹相似性计算模块150。轨迹数据提取模块110用于接收移动用户的移动轨迹数据并进行提取,得到各移动用户的时间位置信息。移动轨迹数据具体包括移动用户发生业务的起始时间、起始基站名称、切换基站的时间、切换基站的名称、在每一个基站的逗留时长、主叫号码、被叫号码、用户发生的业务类型等数据。移动用户轨迹是按照时间序列形成有序的集合,因此,在考虑时间因素的情况下,可将移动用户的轨迹抽取移动用户的时间位置序列。利用运营商的移动用户动态的、具有时间时效性的用户移动轨迹数据查找用户轨迹度,抽取移动用户的时间位置序列,按照发生业务的起始时间的顺序对每一个用户的时间位置数据。将位置序列映射为具有时间和地理位置信息的序列,以发生时间的序列表示移动用户的轨迹,避免由于轨迹稀疏性而导致算法低下的问题。逗留时长计算模块120用于根据时间位置信息得到对应移动用户在各基站的平均逗留时长。根据提取得到的时间位置信息可知道移动用户在各基站的出现时刻和离开时刻,可直接计算出移动用户在各基站的平均逗留时长。频繁序列挖掘模块130用于以移动用户在各基站的平均逗留时长作为权重,采用FP树挖掘对应移动用户的轨迹频繁序列。本实施例中引入闭合频繁项集来保证挖掘得到的移动用户行为信息量最全面且数据规模最小。采用频繁闭合序列模式挖掘经典算法,以基站平均逗留时间作为项目权重构建FP树,挖掘对应移动用户的轨迹频繁序列,轨迹频繁序列表征移动用户逗留各基站的权重。具体地,在一个实施例中,频繁序列挖掘模块130包括闭合频繁项集构建单元、条件模式基生成单元和轨迹频繁序列计算单元。闭合频繁项集构建单元用于将各基站的平均逗留时长作为对应的项目权重,挖掘得到用户轨迹项集及对应的项集权重。根据用户在每一个基站的逗留时长设置每一个项目(基站)的权重,挖掘用户发生轨迹的项目项集(基站组合)得到用户轨迹项集,将用户轨迹项集的项集权重定义为各项目权重的平均值。条件模式基生成单元用于根据用户轨迹项集及对应的项集权重生成条件模式基。查询所有用户轨迹项集,可得知各项目在哪些用户轨迹项集中出现,统计有某一项目出现的用户轨迹项集的数量得到该项目的总计值。根据各项目的总计值降序依次为头节点和其他节点,生成条件模式基。此外,条件模式基生成单元还可对用户轨迹项集的项集权重进行归一化处理,根据归一化处理后的项集权重生成条件模式基,便于数据处理。轨迹频繁序列计算单元用于根据条件模式基构造对应的加权FP树,并得到对应移动用户的轨迹频繁序列。结合移动用户在各基站的平均逗留时长,根据FP树构造的思想,采用条件模式基构造对应的加权FP树,根据加权FP树导出对应移动用户的轨迹频繁序列。常驻地点提取模块140用于根据轨迹频繁序列和预设的加权支持度阈值提取得到对应移动用户的常驻地点。加权支持度阈值的具体取值并不唯一。根据轨迹频繁序列,按照设定的加权支持度阈值判断相应的频繁模式,获得该移动用户的用户常驻区域模式,从而得到移动用户的常驻地点。以移动用户在各基站的平均逗留时长作为权重,采用加权FP树查找用户的常驻点,解决了移动用户轨迹随机性和繁杂性而导致算法效率和算法低下的问题。轨迹相似性计算模块150用于根据各移动用户的常驻地点,通过最长公共子序列算法计算移动用户的轨迹相似性结果,并根据轨迹相似性结果对移动用户进行分类。采用传统的LCSS算法,是通过轨迹本身计算轨迹相似度。本实施例中,在计算得到各移动用户的常驻地点之后,结合轨迹本身和移动用户出现在某个地方的时间规律计算轨迹相似度,得到移动用户的轨迹相似性结果。根据轨迹相似性结果对移动用户进行分类的具体方式并不唯一。在一个实施例中,轨迹相似性计算模块150包括时间位置信息提取单元、时间相似性系数计算单元和轨迹相似性计算单元。时间位置信息提取单元用于提取移动用户间的最长公共子序列以及各移动用户的常驻地点对应的时间。由于各个移动用户的时间位置信息已知,根据建立的具有时间和地理位置信息的序列可直接提取得到两个移动用户之间的最长公共子序列,以及这两个移动用户在常驻地点所对应的时间。时间相似性系数计算单元用于根据各移动用户的常驻地点对应的时间计算移动用户间的时间相似性系数。获得用户常驻区域模式的基础上,结合时间因素,以时间相似性系数反映所有用户在邻近时间在相同的地理位置的比例。具体地,本实施例中,时间相似性系数计算单元根据各移动用户的常驻地点对应的时间计算移动用户间的时间相似性系数包括:其中,COL为时间相似性系数,△T为精度,本实施例中设为1个小时。Ti(u)表示移动用户u在某一个时间精度内达到某一个基站Li(u)的时刻,Tj(v)表示移动用户v在某一个时间精度内达到某一个基站Lj(v)的时刻,δ(Li(u),Lj(v))为重合性公式,当两个用户的基站重合时值为1,否则为0。轨迹相似性计算单元用于根据移动用户间的最长公共子序列以及对应移动用户间的时间相似性系数计算得到移动用户的轨迹相似性结果,并根据轨迹相似性结果对移动用户进行分类。结合时间和地理的因素衡量用户轨迹的相似性,提升了用户轨迹相似度计算的精度。具体地,本实施例中,轨迹相似性计算单元根据移动用户间的最长公共子序列以及对应移动用户间的时间相似性系数计算得到移动用户的轨迹相似性,包括:其中,DLCSS表示用户u和用户v的轨迹相似性,公式的第一部分表示用户u和用户v一天的最长公共子序列,第二部分表示在每一个时间精度下,两位用户在邻近时间在相同的地理位置的比例。在一个实施例中,如图5所示,基于移动用户轨迹相似性的用户分类系统还可包括准确性验证模块160。准确性验证模块160用于在轨迹相似性计算模块150根据各移动用户的常驻地点,通过最长公共子序列算法计算移动用户的轨迹相似性结果,并根据轨迹相似性结果对移动用户进行分类之后,根据移动用户的移动轨迹数据对轨迹相似性结果进行准确性验证,得到验证结果并显示。具体可根据相似性结果关联电话号码进行正确率验证,得到验证结果并发送至显示器进行显示,以便操作人员得知相似性计算准确性。上述基于移动用户轨迹相似性的用户分类系统,通过对移动轨迹数据并提取得到各移动用户的时间位置信息,避免移动用户轨迹数据的稀疏性而导致相似度算法效率低下。以移动用户在各基站的平均逗留时长作为权重,采用FP树挖掘对应移动用户的轨迹频繁序列并找到移动用户的常驻地点,解决了移动用户轨迹随机性和繁杂性而导致算法效率和算法低下的问题,既能保证用户的轨迹规律,又能降低数据的数量,降低了计算复杂度,且考虑了用户移动轨迹的规律性,贴合用户使用习惯特点。以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1