股票分析方法和系统与流程
本发明涉及股票分析技术领域,特别是涉及一种股票分析方法和系统。
背景技术:
全球的股票市场内,股票种类众多,价格瞬息万变,不同行业的股票之间存在一定的关联性,同时因为某些股票投资机构的投资操作,也导致不同的股票之间存在很强的关联,但由于股票自身价格波动的不确定性,股票数据量大、以及股票关联的不确定性因素众多,无论是众多的股票散户,还是股票分析机构,如何从海量的股票数据中,准确分析各股票之间的关联性,是股票分析领域一个重要的课题。
技术实现要素:
基于此,有必要针对各股票间关联性的分析问题,提供一种股票分析方法和系统,其中所述方法包括:
获取第一原始股票序列和第二原始股票序列;
根据预设的嵌入维数、预设的嵌入延迟、所述第一原始股票序列和所述第二原始股票序列,构建各第一股票状态向量和各第二股票状态向量;
对所述各第一股票状态向量进行排序,获取各第一股票重排序向量,并根据所述各第一股票重排序向量和所述各第二股票状态向量,获取各第二股票重排序向量;
根据所述各第二股票重排序向量和预设的权重系数,计算所述各第二股票重排序向量的非单调交叉点取值概率;
根据所述各第二股票重排序向量的非单调交叉点取值概率,计算第一股票到第二股票方向的交叉置换熵;
根据所述第一股票到第二股票方向的交叉置换熵,确定所述第一原始股票序列和所述第二原始股票序列的耦合强度。
在其中一个实施例中,在所述获取第一原始股票序列和第二原始股票序列的步骤之后,所述方法还包括:
将所述第一原始股票序列和所述第二原始股票序列进行时间同步处理,获取第一股票同步后序列和第二股票同步后序列;
对所述第一股票同步后序列和第二股票同步后序列进行标准化处理,获取第一股票标准化序列和第二股票标准化序列,
所述根据预设的嵌入维数、预设的嵌入延迟、所述第一原始股票序列和所述第二原始股票序列,构建各第一股票状态向量和各第二股票状态向量,还包括:
根据预设的嵌入维数、预设的嵌入延迟、所述第一股票标准化序列和所述第二股票标准化序列,构建各第一股票状态向量和各第二股票状态向量。
在其中一个实施例中,所述根据预设的嵌入维数、预设的嵌入延迟、所述第一原始股票序列和所述第二原始股票序列,构建各第一股票状态向量和各第二股票状态向量,包括:
以所述预设的嵌入延迟为提取步长,在所述第一原始股票序列和所述第二原始股票序列中,分别从第一个数据开始提取预设的嵌入维数个数据,组成所述第一原始股票序列和所述第二原始股票序列的第一个状态向量,直至最后一个状态向量的最后一个数据为所述第一原始股票序列和所述第二原始股票序列的最后一个数据为止。
在其中一个实施例中,所述对所述各第一股票状态向量进行排序,获取各第一股票重排序向量,并根据所述各第一股票重排序向量和所述各第二股票状态向量,获取各第二股票重排序向量,包括:
对所述各第一股票状态向量进行非递减排序,获取所述各第一股票重排序向量;
根据所述各第一股票重排序向量,获取所述各第一股票重排序向量的位置向量;
根据所述各第一股票重排序向量的位置向量,对与所述各第一股票重排序向量相对应的各第二股票状态向量进行排序,获取所述各第二股票重排序向量。
在其中一个实施例中,所述预设的权重系数包括:
根据所述第二股票重排序向量的特征值计算所述预设的权重系数,所述特征值包括算术平均值、方差值、相关系数、连乘累计赋权值其中的一个。
在其中一个实施例中,在根据所述各第二股票重排序向量的非单调交叉点取值概率,计算第一股票到第二股票方向的交叉置换熵的步骤之后,所述方法还包括:
对所述各第二股票状态向量进行排序,获取各第二股票重排序向量,并根据所述各第二股票重排序向量和所述各第一股票状态向量,获取各第一股票重排序向量;
根据所述各第一股票重排序向量和预设的权重系数,计算所述各第一股票重排序向量的非单调交叉点取值概率;
根据所述各第一股票重排序向量的非单调交叉点取值概率,计算第二股票到第一股票方向的交叉置换熵;
根据所述第一股票到第二股票方向的交叉置换熵和所述第二股票到第一股票方向的交叉置换熵,确定所述第一原始股票序列和第二原始股票序列的耦合方向。
本发明所提供的股票分析方法,提取两个股票的原始数据后,按照预设的嵌入维数和嵌入延迟,分别构建各第一股票状态向量和各第二股票状态向量,将各所述第一股票状态向量进行重排序后,根据排序后的第一股票重排序向量,获取各第二股票重排序向量,再根据所述各第二股票重排序向量和预设的权重系数,计算第一股票到第二股票方向的交叉置换熵,最后根据所述第一股票到第二股票方向的交叉置换熵,确定所述第一原始股票序列和所述第二原始股票序列的耦合强度。本发明所提供的股票分析方法,对于价格波动大的股票的分析,计算出来的股票间的耦合强度结果更加准确。
在其中一个实施例中,对原始的股票数据进行同步及标准化的处理,使得用于分析的基础数据更加完善和标准,从而使得股票间的耦合强度的计算结果更加准确。
在其中一个实施例中,根据第一股票状态向量非递减排序后的位置向量,对第二股票状态向量进行排序,能够挖掘不同股票间的关联度,在股票间的耦合强度的计算结果中,体现股票间的关联强度。
在其中一个实施例中,根据重排序后的股票状态向量的特征值,设定权重系数,加入非单调交叉点取值概率的计算中,能够更好的体现状态向量的选定特征,在最终的股票关联度的计算结果中,更好的体现原始股票数据的波动性等特征。
在其中一个实施例中,通过比较两只股票间的相互之间的耦合强度,确定所述两只股票间的耦合方向,在确定股票间耦合强度的同时,进一步确定股票间的耦合方向,为股票间的关联性分析提供了更加清晰的关联方向。
本发明还提供一种股票分析系统,包括:
原始股票序列获取模块,用于获取第一原始股票序列和第二原始股票序列;
状态向量构建模块,用于根据预设的嵌入维数、预设的嵌入延迟、所述第一原始股票序列和所述第二原始股票序列,构建各第一股票状态向量和各第二股票状态向量;
重排序向量确定模块,用于对所述各第一股票状态向量进行排序,获取各第一股票重排序向量,并根据所述各第一股票重排序向量和所述各第二股票状态向量,获取各第二股票重排序向量;
交叉点取值概率计算模块,用于根据所述各第二股票重排序向量和预设的权重系数,计算所述各第二股票重排序向量的非单调交叉点取值概率;
交叉置换熵计算模块,用于根据所述各第二股票重排序向量的非单调交叉点取值概率,计算第一股票到第二股票方向的交叉置换熵;
耦合强度确定模块,用于耦合强度确定模块,用于根据所述第一股票到第二股票方向的交叉置换熵,确定所述第一原始股票序列和所述第二原始股票序列的耦合强度。
在其中一个实施例中,还包括:
序列同步模块,用于将所述第一原始股票序列和所述第二原始股票序列进行时间同步处理,获取第一股票同步后序列和第二股票同步后序列;
序列标准化模块,用于对所述第一股票同步后序列和第二股票同步后序列进行标准化处理,获取第一股票标准化序列和第二股票标准化序列,
所述重排序向量确定模块,还用于根据预设的嵌入维数、预设的嵌入延迟、所述第一股票标准化序列和所述第二股票标准化序列,构建各第一股票状态向量和各第二股票状态向量。
在其中一个实施例中,所述状态向量构建模块,用于以所述预设的嵌入延迟为提取步长,在所述第一原始股票序列和所述第二原始股票序列中,分别从第一个数据开始提取预设的嵌入维数个数据,组成所述第一原始股票序列和所述第二原始股票序列的第一个状态向量,直至最后一个状态向量的最后一个数据为所述第一原始股票序列和所述第二原始股票序列的最后一个数据为止。
在其中一个实施例中,所述重排序向量确定模块,包括:
状态向量排序单元,用于对所述各第一股票状态向量进行非递减排序,获取所述各第一股票重排序向量;
位置向量获取单元,用于根据所述各第一股票重排序向量,获取所述各第一股票重排序向量的位置向量;
重排序向量获取单元,用于根据所述各第一股票重排序向量的位置向量,对与所述各第一股票重排序向量相对应的各第二股票状态向量进行排序,获取所述各第二股票重排序向量。
在其中一个实施例中,所述预设的权重系数,包括根据所述第二股票重排序向量的特征值计算所述预设的权重系数,所述特征值包括算术平均值、方差值、相关系数、连乘累计赋权值其中的一个。
在其中一个实施例中,所述状态向量构建模块,还用于对所述各第二股票状态向量进行排序,获取各第二股票重排序向量,并根据所述各第二股票重排序向量和所述各第一股票状态向量,获取各第一股票重排序向量;
所述交叉点取值概率计算模块,还用于根据所述各第一股票重排序向量的非单调交叉点取值概率,计算第二股票到第一股票方向的交叉置换熵;
所述交叉置换熵计算模块,还用于根据所述各第一股票重排序向量的非单调交叉点取值概率,计算第一股票的交叉置换熵;
耦合方向确定模块,用于根据所述第一股票到第二股票方向的交叉置换熵和所述第二股票到第一股票方向的交叉置换熵,确定所述第一原始股票序列和第二原始股票序列的耦合方向。
本发明所提供的股票分析系统,提取两个股票的原始数据后,按照预设的嵌入维数和嵌入延迟,分别构建各第一股票状态向量和各第二股票状态向量,将各所述第一股票状态向量进行重排序后,根据排序后的第一股票重排序向量,获取各第二股票重排序向量,再根据所述各第二股票重排序向量和预设的权重系数,计算第一股票到第二股票方向的交叉置换熵,最后根据所述第一股票到第二股票方向的交叉置换熵,确定所述第一原始股票序列和所述第二原始股票序列的耦合强度。本发明所提供的股票分析系统,对于价格波动大的股票的分析,计算出来的股票间的耦合强度结果更加准确。
在其中一个实施例中,对原始的股票数据进行同步及标准化的处理,使得用于分析的基础数据更加完善和标准,从而使得股票间的耦合强度的计算结果更加准确。
在其中一个实施例中,根据第一股票状态向量非递减排序后的位置向量,对第二股票状态向量进行排序,能够挖掘不同股票间的关联度,在股票间的耦合强度的计算结果中,体现股票间的关联强度。
在其中一个实施例中,根据重排序后的股票状态向量的特征值,设定权重系数,加入非单调交叉点取值概率的计算中,能够更好的体现状态向量的选定特征,在最终的股票关联度的计算结果中,更好的体现原始股票数据的波动性等特征。
在其中一个实施例中,通过比较两只股票间的相互之间的耦合强度,确定所述两只股票间的耦合方向,在确定股票间耦合强度的同时,进一步确定股票间的耦合方向,为股票间的关联性分析提供了更加清晰的关联方向。
附图说明
图1为一个实施例中的股票分析方法的流程示意图;
图2为另一个实施例中的股票分析方法的流程示意图;
图3为又一个实施例中的股票分析方法的流程示意图;
图4为重排序向量的走势图;
图5为一个实施例中的股票分析系统的结构示意图;
图6为另一个实施例中的股票分析系统的结构示意图;
图7为又一个实施例中的股票分析系统的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
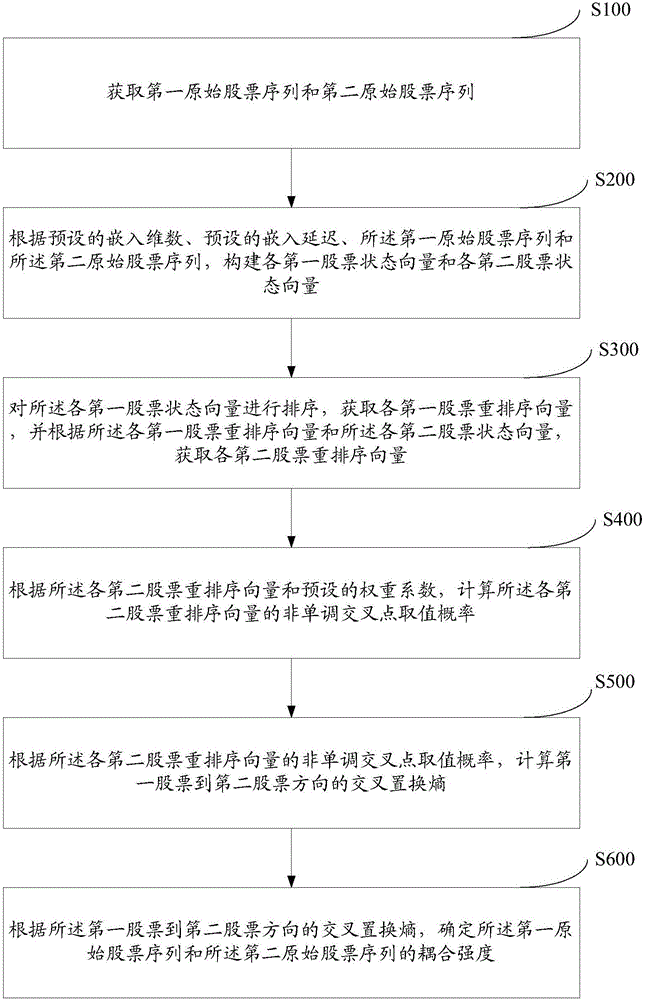
图1为一个实施例中的股票分析方法的流程示意图,如图1所示的股票分析方法包括:
步骤S100,获取第一原始股票序列和第二原始股票序列。
具体的,获取任意两个需要计算相关性的股票的原始数据,且所述两个股票的原始数据需按照相同的时段提取。
例如,获取两个股票的原始序列分别为(xi,i=1,2,...,N}和和(yi,i=1,2,...,N}。
步骤S200,根据预设的嵌入维数、预设的嵌入延迟、所述第一原始股票序列和所述第二原始股票序列,构建各第一股票状态向量和各第二股票状态向量。
具体的,为分析所述两个原始股票序列之间的关联性,首先根据预设的嵌入维数和嵌入时延,构建两个股票的状态向量。所述嵌入维数和所述嵌入延迟,用于将原始股票序列构建为预设的多维度的数据向量后,进行后续交叉置换熵的计算。
以所述预设的嵌入延迟为提取步长,在所述第一原始股票序列和所述第二原始股票序列中,分别从第一个数据开始提取预设的嵌入维数个数据,组成所述第一原始股票序列和所述第二原始股票序列的第一个状态向量,直至最后一个状态向量的最后一个数据为所述第一原始股票序列和所述第二原始股票序列的最后一个数据为止。
分别计算步骤S100中的两个原始股票序列在s维空间上的状态向量:
Xt={xt,xt+τ,xt+2τ,...,xt+(s-1)τ}
Yt={yt,yt+τ,yt+2τ,...yt+(s-1)τ}
其中τ为嵌入延迟,t=1,2,…,N-(s-1)τ。在状态向量重构步骤中,嵌入维数s与嵌入延迟的选择十分重要,维数s的选择要保证时间序列的重构不会破坏序列本身的任何拓扑结构;嵌入延迟τ不可过大填充整个状态空间,也不可使重构的状态空间主对角线坍塌,本方案中,取用时间延迟τ恒等于1。
举例说明,假设第一原始股票序列为{X1,X2,X3,X4,X5},以3为嵌入维度,1为嵌入步长,获取到的第一股票状态向量为:
若以3为嵌入维度,2为嵌入步长,则获取到的第一股票状态向量为:
步骤S300,对所述各第一股票状态向量进行排序,获取各第一股票重排序向量,并根据所述各第一股票重排序向量和所述各第二股票状态向量,获取各第二股票重排序向量;
具体的,对所述第一股票状态向量进行排序,可采用非递减排序的方式,也可采用非递增排序的方式。
例如,对所述各第一股票状态向量进行非递减排序,获取所述各第一股票重排序向量;根据所述各第一股票重排序向量,获取所述各第一股票重排序向量的位置向量;根据所述各第一股票重排序向量的位置向量,对与所述各第一股票重排序向量相对应的各第二股票状态向量进行排序,获取所述各第二股票重排序向量。
设第一股票状态向量为Xt’,第二股票状态向量为Yt’,首先对Xt’向量进行非递减的排列,并以π(X)表示其置换的位置(也就是原数据在向量Xt’中的位置),例如,π(X):以π(X)记录的位置为标准,重新排列向量Yt’,结果记为gt(X,Y)=Yt(π(X))。由于两条完全同步的向量按照上述规则重新排列之后,gt(X,Y)会是一条单调递增的序列,因此可以以gt(X,Y)的单调递增程度来量化向量之间的同步性水平。
举例说明,如第一个第一股票状态向量为(14,12,18),第一个第二股票状态向量为(21,25,28)对所述第一个第一股票状态向量进行非递减排序后,变为(12,14,18),其位置向量为(2,1,3),相应的第二个股票重排序向量为(25,21,28)。
步骤S400,根据所述各第二股票重排序向量和预设的权重系数,计算所述各第二股票重排序向量的非单调交叉点取值概率;
具体的,计算所述各第二股票重排序向量的非单调交叉点取值概率,在序列gt(X,Y)的曲线上,对每一个数据点自左向右画水平线,水平线与序列本身组成的曲线之间的交叉点总数即为gt(X,Y)的单调递增程度,具体过程如图4所示,图4表示Xt’与Yt’的原始走势,黑色曲线表示以从小到大的顺序排列Xt’之后的走势图,灰色曲线表示以π(X)的位置,重新排列向量Yt’之后的曲线走势,圆圈表示交叉点。
将上述过程遍历第二股票重排序向量的所有状态向量,并记第t个区间内交叉点数目为κt:
其中Θ[x]是Heaviside函数,定义为:
若第一股票重排序向量和第二股票重排序向量是完全同步的,那么gt(X,Y)应该是一条单调递增的序列,此时交叉点数目为0。另外,在每个区间内,交叉点个数的最大值为Δ=(s-1)(s-2)/2,因此区间内交叉点的数目可以表示为唯一的整数δ,δi∈[0,Δ],i=1,2,...,Δ+1。统计所有区间内交叉点的个数κt,总共会有Δ+1种取值,分别计算每一个取值可能出现的相对频率:
其中1≤t≤N-(s-1)τ,0≤i≤Δ+1,#为集合的势,也就是满足条件的元素个数。
实际应用中,对于波动剧烈,带有脉冲的序列,只提取排序结构的信息,很多时间序列中的振幅信息可能会丢失。为了量化波动幅度较大序列间的耦合性,本步骤通过增加一个权重ω来提升算法的信息量和精准度。
定义新的相对频率为:
其中1≤t≤N-(s-1)τ,0≤i≤Δ,1A(U)表示集合A的指示函数,定义为:
根据所述第二股票重排序向量的特征值计算所述预设的权重系数,所述特征值包括算术平均值、方差值、相关系数、连乘累计赋权值其中的一个。
举例说明,权重ωt可以使用两个相邻向量gt(X,Y)的均值计算:
权重ωt也可以使用两个相邻向量gt(X,Y)的方差计算:
其中表示gt(X,Y)的算术平均值。
步骤S500,根据所述各第二股票重排序向量的非单调交叉点取值概率,计算第一股票到第二股票方向的交叉置换熵。
具体的,根据上述非单调交叉点取值概率,获得两条原始时间序列在耦合模式下的概率分布P={p(δi),i=1,2,...,Δ+1},以香农熵形式定义的交叉置换熵(CPE)即为:
步骤S600,根据所述第一股票到第二股票方向的交叉置换熵,确定所述第一原始股票序列和所述第二原始股票序列的耦合强度。
具体的,根据所述第一股票到第二股票方向的交叉置换熵,可以用来判断所述第一原始股票序列和所述第二原始股票序列的耦合强度。若熵值越大,两个股票原始序列之间的耦合强度就越弱,当两个股票原始序列完全随机时,熵值达到最大。理想情况下,若两个股票原始序列相对频率满足均一分布,即那么对应的熵值会达到理论最大值log(Δ+1)。
本发明所提供的股票分析方法,提取两个股票的原始数据后,按照预设的嵌入维数和嵌入延迟,分别构建各第一股票状态向量和各第二股票状态向量,将各所述第一股票状态向量进行重排序后,根据排序后的第一股票重排序向量,获取各第二股票重排序向量,再根据所述各第二股票重排序向量和预设的权重系数,计算第一股票到第二股票方向的交叉置换熵,最后根据所述第一股票到第二股票方向的交叉置换熵,确定所述第一原始股票序列和所述第二原始股票序列的耦合强度。本发明所提供的股票分析方法,对于价格波动大的股票的分析,计算出来的股票间的耦合强度结果更加准确。
在本实施例中,根据第一股票状态向量非递减排序后的位置向量,对第二股票状态向量进行排序,能够挖掘不同股票间的关联度,在股票间的耦合强度的计算结果中,体现股票间的关联强度。
在本实施例中,根据重排序后的股票状态向量的特征值,设定权重系数,加入非单调交叉点取值概率的计算中,能够更好的体现状态向量的选定特征,在最终的股票关联度的计算结果中,更好的体现原始股票数据的波动性等特征。
图2为另一个实施例中的股票分析方法的流程示意图,如图2所示的股票分析方法包括:在图1所示的实施例中,在步骤S100之前,所述方法还包括一下步骤:
步骤S80,将所述第一原始股票序列和所述第二原始股票序列进行时间同步处理,获取第一股票同步后序列和第二股票同步后序列。
具体的,由于取到的统一时段的原始股票数据,会存在数据遗漏等,所述第一原始股票序列和所述第二原始股票序列不能完全同步,导致最终的计算结果不准确,因此需要进行时间同步处理。
所述时间同步处理,包括剔除不能在时间上一一对应的股票原始数据,将缺失的数据进行插值等。最终获取到时间完全同步的两个原始股票序列。
步骤S90,对所述第一股票同步后序列和第二股票同步后序列进行标准化处理,获取第一股票标准化序列和第二股票标准化序列。
具体的,为使最终的计算结果更加的准确,在对原始股票序列进行时间同步后,再进行数据的标准化处理。例如,采用如下标准化处理公式:
其中min(x)与max(x)分别为序列x的最小值与最大值。
相应的,图1所示的实施例中,步骤S100的所述根据预设的嵌入维数、预设的嵌入延迟、所述第一原始股票序列和所述第二原始股票序列,构建各第一股票状态向量和各第二股票状态向量,还包括:
根据预设的嵌入维数、预设的嵌入延迟、所述第一股票标准化序列和所述第二股票标准化序列,构建各第一股票状态向量和各第二股票状态向量。
在本实施例中,对原始的股票数据进行同步及标准化的处理,使得用于分析的基础数据更加完善和标准,从而使得股票间的耦合强度的计算结果更加准确。
图3为又一个实施例中的股票分析方法的流程示意图,如图3所示的股票分析方法包括:在图1所示的方法之后,还包括如下步骤:
步骤S700,对所述各第二股票状态向量进行排序,获取各第二股票重排序向量,并根据所述各第二股票重排序向量和所述各第一股票状态向量,获取各第一股票重排序向量。
具体的,同图1中的步骤300。
步骤S800,根据所述各第一股票重排序向量和预设的权重系数,计算所述各第一股票重排序向量的非单调交叉点取值概率。
具体的,同图1中的步骤400。
步骤S900,根据所述各第一股票重排序向量的非单调交叉点取值概率,计算第二股票到第一股票方向的交叉置换熵。
具体的,同图1中的步骤500。
步骤S1000,根据所述第一股票到第二股票方向的交叉置换熵和所述第二股票到第一股票方向的交叉置换熵,确定所述第一原始股票序列和第二原始股票序列的耦合方向。
具体的,通过比较所述第一股票到第二股票方向的交叉置换熵和所述第二股票到第一股票方向的交叉置换熵,可以分别得出所述第一股票原始序列与所述第二股票原始序列之间的两个关联强度,利用两个所述关联强度的大小,可以获取到所述两只股票之间的关联方向。例如,所述第一股票原始序列对于所述第二股票原始序列的关联强度,大于所述第二股票原始序列对于所述第一股票原始序列的关联强度,则所述第一只股票关联于所述第二只股票。
在本实施例中,通过比较两只股票间的相互之间的耦合强度,确定所述两只股票间的耦合方向,在确定股票间耦合强度的同时,进一步确定股票间的耦合方向,为股票间的关联性分析提供了更加清晰的关联方向。
图5为一个实施例中的股票分析系统的结构示意图,如图5所示的股票分析系统包括:
原始股票序列获取模块100,用于获取第一原始股票序列和第二原始股票序列。
状态向量构建模块200,用于根据预设的嵌入维数、预设的嵌入延迟、所述第一原始股票序列和所述第二原始股票序列,构建各第一股票状态向量和各第二股票状态向量;用于以所述预设的嵌入延迟为提取步长,在所述第一原始股票序列和所述第二原始股票序列中,分别从第一个数据开始提取预设的嵌入维数个数据,组成所述第一原始股票序列和所述第二原始股票序列的第一个状态向量,直至最后一个状态向量的最后一个数据为所述第一原始股票序列和所述第二原始股票序列的最后一个数据为止。包括:状态向量排序单元,用于对所述各第一股票状态向量进行非递减排序,获取所述各第一股票重排序向量;位置向量获取单元,用于根据所述各第一股票重排序向量,获取所述各第一股票重排序向量的位置向量;重排序向量获取单元,用于根据所述各第一股票重排序向量的位置向量,对与所述各第一股票重排序向量相对应的各第二股票状态向量进行排序,获取所述各第二股票重排序向量。
重排序向量确定模块300,用于对所述各第一股票状态向量进行排序,获取各第一股票重排序向量,并根据所述各第一股票重排序向量和所述各第二股票状态向量,获取各第二股票重排序向量。
交叉点取值概率计算模块400,用于根据所述各第二股票重排序向量和预设的权重系数,计算所述各第二股票重排序向量的非单调交叉点取值概率;所述预设的权重系数,包括根据所述第二股票重排序向量的特征值计算所述预设的权重系数,所述特征值包括算术平均值、方差值、相关系数、连乘累计赋权值其中的一个。
交叉置换熵计算模块500,用于根据所述各第二股票重排序向量的非单调交叉点取值概率,计算第一股票到第二股票方向的交叉置换熵。
耦合强度确定模块600,用于根据所述第一股票到第二股票方向的交叉置换熵,确定所述第一原始股票序列和所述第二原始股票序列的耦合强度。
本发明所提供的股票分析系统,提取两个股票的原始数据后,按照预设的嵌入维数和嵌入延迟,分别构建各第一股票状态向量和各第二股票状态向量,将各所述第一股票状态向量进行重排序后,根据排序后的第一股票重排序向量,获取各第二股票重排序向量,再根据所述各第二股票重排序向量和预设的权重系数,计算第一股票到第二股票方向的交叉置换熵,最后根据所述第一股票到第二股票方向的交叉置换熵,确定所述第一原始股票序列和所述第二原始股票序列的耦合强度。本发明所提供的股票分析系统,对于价格波动大的股票的分析,计算出来的股票间的耦合强度结果更加准确。
在本实施例中,根据第一股票状态向量非递减排序后的位置向量,对第二股票状态向量进行排序,能够挖掘不同股票间的关联度,在股票间的耦合强度的计算结果中,体现股票间的关联强度。
在本实施例中,根据重排序后的股票状态向量的特征值,设定权重系数,加入非单调交叉点取值概率的计算中,能够更好的体现状态向量的选定特征,在最终的股票关联度的计算结果中,更好的体现原始股票数据的波动性等特征。
图6为另一个实施例中的股票分析系统的结构示意图,如图6所示的股票分析系统包括:
序列同步模块80,用于将所述第一原始股票序列和所述第二原始股票序列进行时间同步处理,获取第一股票同步后序列和第二股票同步后序列。
序列标准化模块90,用于对所述第一股票同步后序列和第二股票同步后序列进行标准化处理,获取第一股票标准化序列和第二股票标准化序列。
所述状态向量构建模块200,还用于根据预设的嵌入维数、预设的嵌入延迟、所述第一股票标准化序列和所述第二股票标准化序列,构建各第一股票状态向量和各第二股票状态向量。
在本实施例中,对原始的股票数据进行同步及标准化的处理,使得用于分析的基础数据更加完善和标准,从而使得股票间的耦合强度的计算结果更加准确。
图7为又一个实施例中的股票分析系统的结构示意图,如图7所示的股票分析系统包括:
所述重排序向量确定模块300,还用于对所述各第二股票状态向量进行排序,获取各第二股票重排序向量,并根据所述各第二股票重排序向量和所述各第一股票状态向量,获取各第一股票重排序向量;
所述交叉点取值概率计算模块400,还用于根据所述各第一股票重排序向量和预设的权重系数,计算所述各第一股票重排序向量的非单调交叉点取值概率;
所述交叉置换熵计算模块500,还用于根据所述各第一股票重排序向量的非单调交叉点取值概率,计算第二股票到第一股票方向的交叉置换熵;
耦合方向确定模块700,用于根据所述第一股票到第二股票方向的交叉置换熵和所述第二股票到第一股票方向的交叉置换熵,确定所述第一原始股票序列和第二原始股票序列的耦合方向。
在本实施例中,通过比较两只股票间的相互之间的耦合强度,确定所述两只股票间的耦合方向,在确定股票间耦合强度的同时,进一步确定股票间的耦合方向,为股票间的关联性分析提供了更加清晰的关联方向。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!