一种大数据分类处理方法与流程
本发明涉及数据处理领域,特别是一种大数据分类处理方法。
背景技术:
分类与预测是两种数据分析形式,它们可以用来抽取能够描述重要数据集合或预测未来数据趋势的模型。分类方法用于预测数据对象的离散类别。
分类技术在很多领域都有应用,例如可以通过客户分类构造一个分类模型来对银行贷款进行风险评估;当前的市场营销中很重要的一个特点是强调客户细分。客户类别分析的功能也在于此,采用数据挖掘中的分类技术,可以将客户分成不同的类别,比如呼叫中心设计时可以分为:呼叫频繁的客户、偶然大量呼叫的客户、稳定呼叫的客户、其他,帮助呼叫中心寻找出这些不同种类客户之间的特征,这样的分类模型可以让用户了解不同行为类别客户的分布特征;其他分类应用如文献检索和搜索引擎中的自动文本分类技术;安全领域有基于分类技术的入侵检测等等。机器学习、专家系统、统计学和神经网络等领域的研究人员已经提出了许多具体的分类预测方法。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种大数据分类处理方法,对大数据进行分类,经过分类处理后,用户直接以分类信息管理和使用数据,获取系统智能推荐的相关内容等。
本发明的目的是通过以下技术方案来实现的:一种大数据分类处理方法,它包括学习训练和分类两个步骤;
所述的学习训练包括如下子步骤:
S11:收集已经分类好的文章,形成语料库;
S12:通过庖丁分词将语料库的文章分解成一个一个的词语;
S13:去掉停用词和中性词;
S14:对去掉停用词和中性词后的词汇进行TF-IDF矢量化;
S15:概率统计:根据每一个词汇的TF-IDF值,筛选出用于分类的词汇;
S16:根据以上处理,再根据精度需要,得到一组用于进行分类的常用词汇;
S17:将用于分类的词语形成标准的ARFF数据;
S18:根据ARFF数据采用不同算法计算出用于分类的模型数据;
所述的分类包括如下子步骤:
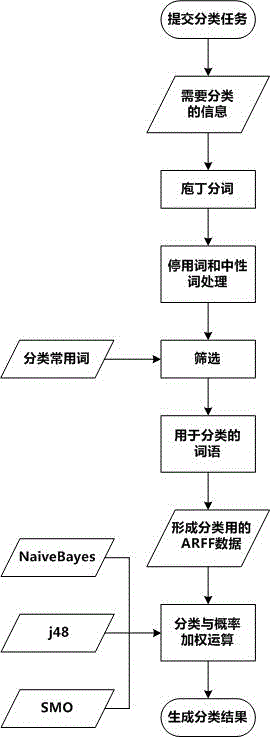
S21:提交分类任务;
S22:获取需要分类的信息;
S23:庖丁分词,对需要分类的信息进行分词;
S24:去掉需要分类的信息中的停用词和中性词,得到用于分类的基本词汇;
S25:进行常用词筛选,得到最终需要用于分类的词语;
S26:对用于分类的词语进行TF-IDF计算,形成分类用ARFF数据;
S27:用学习训练得到的模型数据结合ARFF数据,计算出分到每一类的概率,并进行加权计算,得到分类结果。
所述的停用词包括但不限于的、地、得。
所述的中性词包括但不限于我们、里面、一个、两个。
所述的TF-IDF值包括TF和IDF,TF为某一个词在某一类文章中的概率,IDF该词不在其他类文章的概率。
所述的模型数据的计算算法包括朴素贝叶斯方法、基于C4.5实现的决策树算法和SMO算法。
所述的常用词筛选根据学习训练中得到的常用词汇进行筛选。
本发明的有益效果是:本发明提供了一种大数据分类处理方法,对大数据进行分类,经过分类处理后,用户直接以分类信息管理和使用数据,获取系统智能推荐的相关内容等,能够进行智能学习,分类越积累,分类越准确,推荐相关内容也更准确。
附图说明
图1为学习训练方法流程图;
图2为分类方法流程图。
具体实施方式
下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。
一种大数据分类处理方法,它包括学习训练和分类两个步骤;
如图1所示,所述的学习训练包括如下子步骤:
S11:收集已经分类好的文章,形成语料库,文章越多越好;
S12:通过庖丁分词将语料库的文章分解成一个一个的词语,庖丁分词采用开源的第三方软件;
S13:去掉停用词和中性词,如的、地、得、我们、里面、一个、两个等没有任何意义的词;
S14:对去掉停用词和中性词后的词汇进行TF-IDF矢量化;
S15:概率统计:根据每一个词汇的TF-IDF值,筛选出用于分类的词汇,TF-IDF值包括TF和IDF,TF为某一个词在某一类文章中的概率,IDF该词不在其他类文章的概率,一般采用TF*log IDF来判断词汇是否适用于分类;
S16:根据以上处理,再根据精度需要,得到一组用于进行分类的常用词汇;
S17:将用于分类的词语形成标准的ARFF数据;
S18:根据ARFF数据采用不同算法计算出用于分类的模型数据,算法包括朴素贝叶斯方法、基于C4.5实现的决策树算法和SMO算法,得到NaiveBayes,j48,SMO,三种模型数据。
C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类;SMO算法由Microsoft Research的John C. Platt在1998年提出,并成为最快的二次规划优化算法,特别针对线性SVM和数据稀疏时性能更优。
如图2所示,所述的分类包括如下子步骤:
S21:提交分类任务;
S22:获取需要分类的信息,通过WebService输入需要分类的文本;
S23:庖丁分词,对需要分类的信息进行分词;
S24:去掉需要分类的信息中的停用词和中性词,得到用于分类的基本词汇;
S25:根据学习训练中得到的常用词汇进行筛选,得到最终需要用于分类的词语;
S26:对用于分类的词语进行TF-IDF计算,形成分类用ARFF数据;
S27:用学习训练得到的NaiveBayes,j48,SMO,三种模型数据结合ARFF数据,计算出分到每一类的概率,并进行加权计算,得到分类结果,并通过Webservice返回分类值。
- 还没有人留言评论。精彩留言会获得点赞!