处理器和将架构指令转译成微指令的方法与流程
一直以来都存在针对存储程序处理器的性能改进的恒定需求,其中这些程序处理器通常被称为中央处理单元(CPU)和微处理器。历史上,一些处理器已经包括了用以实现处理器的指令集架构(Instruction Set Architecture,ISA)的至少一些架构指令以及用以服务于例外的微代码。传统的处理器每时钟周期从处理器的微代码存储器获取单个微代码指令,这样特别是在具有每时钟处理多个指令的能力的处理器中可能会限制微编码架构指令和/或例外服务例程的性能。
技术实现要素:
本发明提供一种处理器,其具有指令集架构即ISA,所述处理器包括:执行流水线,其具有执行微指令的多个执行单元;以及指令转译器,用于将所述ISA所定义的架构指令转译成微指令,所述指令转译器包括:存储器,用于保持微代码指令并且每时钟周期响应于地址提供多个微代码指令;队列,用于保持所述存储器所提供的微代码指令;分支解码器,其连接在所述存储器和所述队列之间,用于对所述存储器所提供的所述多个微代码指令进行解码以检测所述多个微代码指令中的一个或多个本地分支指令,使得要将所述多个微代码指令中的直到所述一个或多个本地分支指令的程序顺序首位本地分支指令为止但不包括所述程序顺序首位本地分支指令的微代码指令写入所述队列,并且防止将所述多个微代码指令中的所述程序顺序首位本地分支指令及其后续微代码指令写入所述队列,其中,本地分支指令由所述指令转译器而非所述执行流水线进行解析;以及多个微代码转译器,用于将每时钟周期从所述队列接收到的多个微代码指令转译成多个微指令以提供至所述执行流水线。
本发明还提供一种用于将架构指令转译成微指令以供执行流水线执行的方法,所述架构指令是由处理器的指令集架构即ISA所定义的,所述执行流水线具有多个执行单元,所述方法包括以下步骤:通过存储器来每时钟周期响应于地址而提供多个微代码指令;通过连接在所述存储器和队列之间的分支解码器来对所述存储器所提供的所述多个微代码指令进行解码,以检测所述多个微代码指令中的一个或多个本地分支指令;使得要将所述多个微代码指令中直到所述一个或多个本地分支指令的程序顺序首位本地分支指令为止但不包括所述程序顺序首位本地分支指令的微代码指令写入所述队列;并且防止将所述多个微代码指令中的所述程序顺序首位本地分支指令及其后续微代码指令写入所述队列;其中,所述本地分支指令由所述分支解码器而非由所述执行流水线进行解析;以及通过多个微代码转译器将每时钟周期从所述队列接收到的所述多个微代码指令转译成多个微指令以提供至所述执行流水线。
附图说明
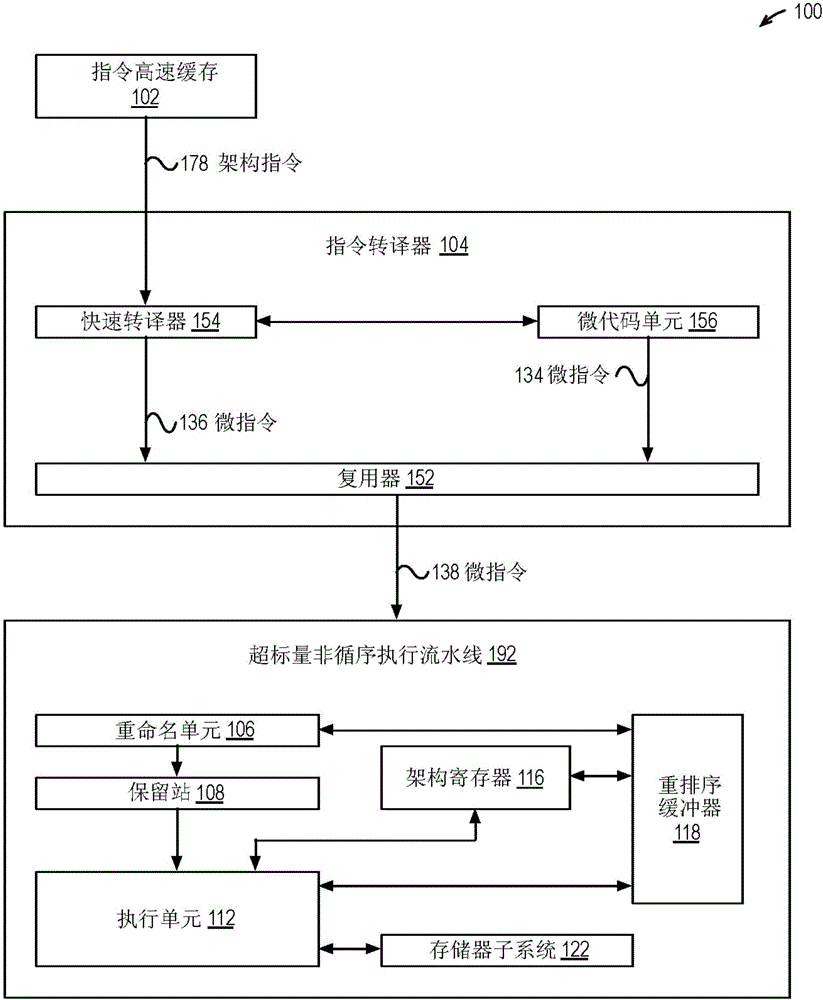
图1是示出处理器的框图。
图2是更详细地示出图1的处理器的指令转译器的框图。
图3是示出图2的微代码单元的操作的流程图。
图4是示出图2的微代码单元的操作的流程图。
具体实施方式
本地分支指令(local branch instruction)是由指令转译器(instruction translator)而非由处理器的执行流水线进行解析的分支指令。本地分支指令可以是诸如无条件跳转指令、调用指令或返回指令等的目标地址可以从指令转译器的调用/返回堆栈获得的无条件分支指令。本地分支指令还可以是条件分支指令,其中该条件分支指令的条件(诸如静态条件等)可以由指令转译器进行解析,因此无需由执行流水线进行解析。
非本地分支指令(non-local branch instruction)是由处理器的执行流水线进行解析的分支指令。
微代码(microcode)是作为非架构指令的指令的例程或程序线程,其中,该非架构指令在处理器的非架构存储器中存储、用于实现架构指令执行和/或服务于例外。由微代码来实现执行的架构指令通常是复杂的和/或不频繁执行的。微代码所服务的例外可以是架构例外和/或微架构例外。微代码例程可以包括一个或多个分支指令。
微指令(microinstruction)是由处理器的一个或多个执行单元来执行并且由与处理器的ISA定义的指令集不同的指令集所定义的指令。处理器的ISA的示例是x86ISA。架构指令被转译成一个或多个微指令。执行单元所进行的一个或多个微指令的统一执行实现了架构指令,即,进行生成如ISA所定义的架构指令的结果所需的操作。
现在参考图1,示出用于例示处理器100的框图。处理器100包括指令高速缓存102、指令转译器104和超标量非循序执行流水线192。指令高速缓存102基于架构程序计数器(未示出)对来自系统存储器的架构指令进行高速缓存并且将架构指令178提供至指令转译器104。指令转译器104将架构指令178转译成提供至执行流水线192的微指令138。执行流水线192执行微指令138以产生转译后的如处理器100的ISA所定义的架构指令178的结果。在一个实施例中,处理器100ISA是x86ISA。指令转译器104每时钟周期获取多个微代码指令(例如参见图2的微代码指令272)以转译成微指令138,从而如这里更详细地说明那样,相对于每时钟周期获取单个微代码指令的传统处理器的吞吐量而言,增加每时钟周期向执行流水线192提供的微指令138的吞吐量。这相对于每时钟周期获取单个微代码指令的传统处理器而言,潜在地改进了服务于诸如中断等的例外的微代码的性能。
执行流水线192包括重命名单元106、保留站108、执行单元112、架构寄存器116、重排序缓冲器118和存储器子系统122。执行单元112执行微指令138。在一个实施例中,执行单元112包括一个或多个整型单元、一个或多个媒体/浮点型单元、一个或多个分支单元以及一个或多个加载/存储单元。例如,存储器子系统122包括存储器顺序缓冲器、一个或多个高速缓存存储器(例如,一级指令高速缓存、一级数据高速缓存)、转译后备缓冲器、表查找引擎、一个或多个数据预取器、写入合并缓冲器以及诸如加载队列、存储队列、探测队列和填充队列等的各种请求队列。
指令转译器104按程序顺序向重命名单元106提供微指令138。重命名单元106从指令转译器104接收微指令138并且按程序顺序针对各微指令138分配重排序缓冲器118中的条目。例如,重排序缓冲器118是循环队列,并且分配重排序缓冲器118中的条目以保持微指令138的程序顺序。执行单元112不按程序顺序执行微指令138。然而,重命名单元106检查微指令138之间的依赖性并且将依赖性信息与微指令138一起沿着执行流水线192发送。保留站108保持微指令138,直到准备好执行微指令138为止。保留站108和调度器(未示出)使用依赖性信息来确保在准备好执行微指令138之前不向执行单元112发出微指令138以进行执行。在执行单元112可以执行微指令138的情况下并且在微指令138的所有源操作数均可用的情况下,准备好执行微指令138。更具体地,在执行了微指令138所依赖于的任何微指令138并且生成了其结果作为源操作数的情况下,微指令138的源操作数可用。
在一个实施例中,重排序缓冲器118在各条目中包括用于存储所执行的微指令138的结果的区域。在已经执行了微指令138并且生成了该微指令138的结果以在结果总线上提供从而提供至重排序缓冲器118的情况下,将该微指令138的重排序缓冲器118条目标记为已执行。然而,可以不使微指令138提交,即,微指令138的结果可以不被置于架构状态,直到该微指令138是执行流水线192中最老的微指令138。因而,尽管执行单元112不按程序顺序执行微指令138,但重命名单元106和重排序缓冲器118一起运行以确保微指令138按程序顺序提交。还可根据需要将这些结果经由转发总线转发回执行单元112以在下一时钟周期中使用。执行流水线192可被配置为每时钟周期使4个最老的微指令138提交。在架构指令178所转换成的所有微指令138均已提交之后,则架构指令178提交。例如,在作为实现架构指令178的微代码例程的最后一个微指令138的微指令138提交的情况下,使架构指令178提交。
在重排序缓冲器118条目包括各微指令138的结果所用的存储器的实施例中,使微指令138提交包括将结果写入适当的架构寄存器116。在可供候选的实施例中,执行流水线192包括作为架构寄存器116所用的存储器的物理寄存器文件(未示出),并且重排序缓冲器118条目不包括结果所用的存储器。作为替代,重命名单元106针对各微指令138的结果分配物理寄存器文件中的寄存器,并且重命名单元106基于所分配到的物理寄存器文件中的寄存器来检查依赖性。重命名单元106还维持表示物理寄存器文件中的各寄存器的状态的表。更具体地,在微指令138提交的情况下,重命名单元106对保持微指令138的结果的物理寄存器文件的寄存器的状态进行更新,以表示物理寄存器文件现在包含相关联的架构寄存器116的架构状态。
指令转译器104包括快速转译器154、微代码单元156和复用器(mux)152。快速转译器154将架构指令178转译成微指令136。微代码单元156将架构指令178转译成微指令134。复用器152根据指令转译器104的模式选择来自快速转译器154的微指令136或来自微代码单元156的微指令134,以作为微指令138提供至执行流水线。在一个实施例中,队列(未示出)对微指令138进行缓冲以提供至执行流水线192。
快速转译器154转译相对简单和/或频繁执行的架构指令178。例如,快速转译器154包括如下的可编程逻辑阵列的集合,这些可编程逻辑阵列针对架构指令178的子集,可在单个时钟周期中将各架构指令178转译成一个或多个微指令136。在一个实施例中,快速转译器154每时钟周期能够转译多达4个架构指令178并且每时钟周期能够提供多达6个微指令136。在快速转译器154能够转译架构指令178的情况下,指令转译器104维持快速转译状态,在这种情况下,复用器152选择快速转译器154所生成的微指令136。
然而,在快速转译器154遇到微编码的架构指令178或者被通知了例外条件的情况下,快速转译器154停止转译架构指令178并且将控制转移至微代码单元156并改变成微代码模式,在这种情况下,复用器152选择微代码单元156所生成的微指令134。在这种情况下,快速转译器154提供微代码ROM 202(参见图2)中所存储的进行微编码架构指令178或服务于例外的微代码例程的地址。以下参考其余的图来更详细地说明微代码单元156及其操作。
在一个实施例中,某些架构指令178是混合的。也就是说,快速转译器154提供微代码指令136的一部分并且其余的架构指令178是微编码的,即,快速转译器154在快速转译模式下提供微指令136的头部,然后模式改变为微代码模式并将控制转移至微代码单元156,以使得微代码例程能够经由微代码单元156所提供的微指令134来进行架构指令178的其余功能。
例如,如以下更详细地说明那样,指令转译器104每时钟周期获取多个微代码指令,以增加提供至执行流水线192的微指令138的吞吐量,从而针对微编码的架构指令178和/或微编码的例外服务例程利用执行流水线192的超标量能力并提高该超标量能力的利用率。
现在参考图2,示出用于更详细地示出图1的处理器100的指令转译器104的框图。指令转译器104包括地址生成器206、微代码ROM 202、分支解码器208、微代码指令队列212、队列控制器214、多个微代码转译器216和调用/返回单元222(CRU)。微代码ROM 202是包括4个可分开寻址的存储体(bank)(统称为存储体204以及单独称为存储体204的存储体A 204A、存储体B204B、存储体C 204C和存储体D 204D)的存储体型存储器。以这种方式,微代码ROM 202每时钟周期可向分支解码器208提供4个微代码指令272。如图所示,微代码ROM 202将4个微代码指令272分别在标记为0~3的4个通道上提供至分支解码器208。通道0按程序顺序提供第一微代码指令272,通道1按程序顺序提供第二微代码指令272,通道2按程序顺序提供第三微代码指令272,并且通道3按程序顺序提供第四微代码指令272。根据一个实施例,各存储体204有利地具有单个读取端口以使得该存储体204的大小和功耗最小化。
地址生成器206生成提供至微代码ROM 202的微代码取指地址268。第一加法器224-1使取指地址268递增1,第二加法器224-2使取指地址268递增2,并且第三加法器使取指地址268递增3,并且将递增后的各地址与取指地址268一起分别提供至微代码ROM 202。将4个地址各自提供至微代码ROM 202的相应存储体204以实现4个顺次微代码指令272的获取。微代码ROM 202包括将4个地址各自引导至4个存储体204中的适当存储体204的第一组复用器(未示出)以及根据取指地址268的2个最低有效位将4个存储体204所提供的4个微代码指令272各自引导至分支解码器208的适当通道的第二组复用器(未示出)。如果取指地址268的最低两位的值是0,则将取指地址268提供至存储体A 204A,将递增1的地址提供至存储体B 204B,将递增2的地址提供至存储体C 204C,并且将递增3的地址提供至存储体D 204D;如果取指地址268的最低两位的值是1,则将取指地址268提供至存储体B 204B,将递增1的地址提供至存储体C 204C,将递增2的地址提供至存储体D 204D,并且将递增3的地址提供至存储体A 204A;如果取指地址268的最低两位的值是2,则将取指地址268提供至存储体C 204C,将递增1的地址提供至存储体D 204D,将递增2的地址提供至存储体A 204A,并且将递增3的地址提供至存储体B 204B;以及如果取指地址268的最低两位的值是3,则将取指地址268提供至存储体D 204D,将递增1的地址提供至存储体A 204A,将递增2的地址提供至存储体B 204B,将递增3的地址提供至存储体C 204C。类似地,将存储体A 204A的输出提供至分支解码器208的与取指地址268对4取模的最低两位的值相对应的通道;将存储体B 204B的输出提供至分支解码器208的与取指地址268加1并对4取模的最低两位的值相对应的通道;将存储体C 204C的输出提供至分支解码器208的与取指地址268加2并对4取模的最低两位的值相对应的通道;并且将存储体D 204D的输出提供至分支解码器208的与取指地址268加3并对4取模的最低两位的值相对应的通道。
取指地址268保持在微代码程序计数器(未示出)中。最初,即,在快速转译器154切换至微代码模式时,微代码程序计数器加载有快速转译器154所提供的微代码例程的地址。如上所述,本地分支指令是由指令转译器104、更具体地由微代码单元156而非由执行流水线192进行解析的分支指令。与此相对,非本地分支指令是必须发出至执行流水线192以进行解析并且不能由微代码单元156进行解析的分支指令。对分支指令进行解析意味着判断是否采用分支指令,以及如果采用分支指令则确定分支指令的目标地址。每当从微代码ROM 202获取到微代码指令272序列时,更新取指地址268(即,微代码程序计数器)。如果分支解码器208判断为微代码指令272序列中没有任何本地分支指令,则地址生成器206使得获取下一顺次指令。更具体地,加法器226使取指地址268递增4,即,进行增量为微代码指令272数量的递增。然而,如果分支解码器208在微代码指令272序列中检测到本地分支指令,则分支解码器208对该本地分支指令进行解析,并且如果采用了该分支指令的方向,则分支解码器208向地址生成器206提供解析后的目标地址266以更新微代码程序计数器,从而获取解析后的目标地址266处的下一微代码指令272序列。
在调用微代码指令的情况下,始终采用该方向,并且分支解码器208所计算出的目标地址266是调用指令之后的下一顺次地址,如以下更详细说明的那样,该下一顺次地址是提供至调用/返回单元222并被推入当前调用/返回堆栈254的返回地址。调用微代码指令由微代码单元156进行解析,因而是本地分支指令。在返回微代码指令的情况下,始终采用该方向,并且如以下更详细说明的那样,从当前调用/返回堆栈254弹出返回地址298,并且将返回地址298提供至地址生成器206以更新微代码程序计数器。返回微代码指令由微代码单元156进行解析,因而是本地分支指令。始终采用无条件跳转微代码指令,并且无条件跳转微代码指令可以是本地分支或非本地分支。在本地无条件跳转的情况下,在指令本身中指定目标地址266,而执行流水线192计算非本地无条件跳转的目标地址。类似地,条件跳转微代码指令可以是本地或非本地的。在本地条件跳转微代码指令的情况下,微代码单元156对方向进行解析并且目标地址266包括在指令本身中,而执行流水线192对方向进行解析并且计算非本地条件跳转的目标地址。优选地,微代码单元156有效地预测到不采用任何非本地分支指令,并且不基于微代码指令272序列中非本地分支指令的存在而中断顺次获取处理。结果,如果执行流水线192将非本地分支指令解析为已采用,则冲刷(flush)包括微代码指令队列212的微代码单元156流水线,并且执行流水线192提供新的目标地址以更新微代码程序计数器。
分支解码器208从微代码ROM 202接收微代码指令272序列并且使微代码指令272通过作为微代码指令274。分支解码器208对微代码指令272序列进行解码以查找本地分支指令和非本地分支指令这两者。特别地,分支解码器208在从0至3即按程序顺序的通道搜索接收到的微代码指令272序列,并且检测到具有本地分支指令的第一个通道(如果存在),这里将该本地分支指令称为“程序顺序首位的本地分支指令”。分支解码器208还确定以下通道中的微代码指令272序列中的非本地分支的数量,其中该通道在具有程序顺序首位的本地分支指令的通道之前,并且分支解码器208将该数量在信号num_non-local_br 282上输出至调用/返回单元222。分支解码器208还判断程序顺序首位的本地分支指令是否为调用指令,并且如果是调用指令,则使得被提供至调用/返回单元222的推入信号有效。分支解码器208还判断程序顺序首位的本地分支指令是否为返回指令,并且如果是返回指令,则使得被提供至调用/返回单元222的弹出信号286有效。
分支解码器208还将信号num_valid_instrs 288提供至队列控制器214,该信号表示微代码指令272序列中要写入队列212中的指令的数量。更具体地,如果num_valid_instrs 288的值是N,则将分支解码器208所提供的前N个微代码指令274写入队列212。队列控制器214对微代码指令274向队列212中由提供至队列212的写入指针244所指定的位置的写入进行控制。队列控制器214通过使当前写入指针244的值进行增量为num_valid_instrs 288对队列212的大小(即,队列212中的条目的数量)取模的递增,来更新写入指针244。最后,分支解码器208将程序顺序首位的本地分支指令的目标地址266提供给地址生成器206。num_valid_instrs 288是微代码指令272序列中处于程序顺序首位的本地分支指令之前但不包括程序顺序首位的本地分支指令的指令的数量。因而,如果不存在本地分支指令,则num_valid_instrs 288为4;如果程序顺序首位的本地分支指令处于通道3中,则num_valid_instrs 288为3;如果程序顺序首位的本地分支指令处于通道2中,则num_valid_instrs 288为2;如果程序顺序首位的本地分支指令处于通道1中,则num_valid_instrs 288为1;以及如果程序顺序首位的本地分支指令处于通道0中,则num_valid_instrs 288为0。因而,在分支解码器208在微代码指令272序列中检测到本地分支指令的情况下,分支解码器208有效地丢弃程序顺序首位的本地分支指令之后且包括顺序首位的本地分支指令的微代码指令274,即,分支解码器208使得不将这些微代码指令274写入队列212。
在功能上将分支解码器208放置在微代码ROM 202和队列212之间,以使得分支解码器208在微代码指令272序列被写入至队列212之前对微代码指令272序列进行解码,这相对于在功能上将分支解码器208放置在队列212之后而言具有优点。首先,这使得能够仅将微代码指令272序列中直到程序顺序首位的本地分支指令但不包括程序顺序首位的本地分支指令的微代码指令写入队列212,并且不将跟随在程序顺序首位的本地分支指令之后的微代码指令写入队列212。这样可以省电。此外,在分支解码器208对本地分支进行了解码的情况下,这避免了对队列212进行使性能下降的冲刷的需求。
在微代码指令274填满队列212的情况下,队列212使得至地址生成器206的已满264有效,这引起地址生成器206停止从微代码ROM 202获取指令。然而,有利地,只要队列212未满,则即使在例如由于执行流水线192暂停而使得执行流水线192不能从指令转译器104接收微指令138的情况下,地址生成器206也继续进行获取并且用微代码指令274来填充队列212。此外,队列212可以减少与微代码单元156流水线的长度相关联的性能损失,其中在一个实施例中,微代码单元156流水线包括4个流水线级,由此引起从访问微代码ROM 202起到向执行流水线192提供根据微代码ROM 202转译得到的微指令134的4个时钟周期。
在队列212中没有微代码指令274的情况下,队列212使得至微代码转译器216的为空262有效,这引起微代码转译器216停止将微代码指令276转译成图1的微指令134。然而,有利地,只要队列212不为空,则微代码转译器216每时钟周期从队列212读取微代码指令276并将这些微代码指令276转译成微指令134。优选地,队列212随着各微代码指令276提供用以表示各微代码指令276是否有效的有效信号,以使得微代码转译器216不转译无效的微代码指令276。例如,如果队列212仅包含两个微代码指令276,则队列212将这两个微代码指令276提供在通道0和1上并且使得与通道0和1相关联的有效信号有效,而使得与通道2和3相关联的有效信号无效。优选地,队列控制器214将队列212中的微代码指令276的数量确定为写入指针244的值减去下述的读取指针242的值的差。
微代码转译器216将表示给定时钟周期内转译成微指令134的微代码指令276的数量的num_translated信号246提供至队列控制器214。队列控制器214对来自队列中的由提供至队列212的读取指针242所指定的位置的微代码指令276的读取进行控制。队列控制器214通过使当前读取指针242进行增量为num_traslated信号246的值对队列212的大小(即,队列212中的条目的数量)取模的递增来更新读取指针242。
在一个实施例中,可以根据微代码指令276的复杂度将微代码指令276转译成1~4个微指令。优选地,存在各自能够将微代码指令276转译成不同数量的微指令的4个微代码转译器216。优选地,通道0的转译器216能够将任何类型的微代码指令276转译成要求数量(即,多达4个)的微指令;通道1的转译器216能够对要求1~3个微指令的类型的微代码指令276进行转译;通道2的转译器216能够对要求1~2个微指令的类型的微代码指令276进行转译;以及通道3的转译器216能够对要求仅一个微指令的类型的微代码指令276进行转译。微代码转译器216包括接收4个微代码转译器216的输出的复用矩阵(未示出),并且选择有效的微指令以作为微指令134提供至图1的复用器152。因而,例如,在给定时钟周期内,通道0的微代码转译器216可能会遇到该转译器转译成单个微指令134的微代码指令276,通道1的微代码转译器216可能会遇到要求转译成4个微指令134的微代码指令276,在这种情况下,这些微代码转译器216将仅提供从通道0中的微代码指令276转译得到的单个微指令134,这是由于仅存在供微指令134用的3个剩余槽,而不是4个。然而,有利地,微代码指令队列212提供缓冲器以潜在地改善由于微代码指令流的复杂度、以及指令流内的可变复杂度微代码指令相对于彼此的位置的可变性而引起的每时钟周期所转译的微代码指令的数量的可变性的影响。
调用/返回单元222包括推测指针258、非推测指针256、多个调用/返回堆栈254以及与调用/返回堆栈254相关联的相应多个计数器252。推测指针258指向当前调用/返回堆栈254,即,响应于调用/返回微代码指令而推入/弹出返回地址的调用/返回堆栈254。推测指针258还指向与当前调用/返回堆栈254相关联的计数器252。非推测指针256指向非推测调用/返回堆栈254和关联的计数器252,其中在要采用由执行流水线192进行解析的非本地分支指令(即,隐含错误地预测为不采用微代码单元156的非本地分支指令)的情况下,微代码单元156使该计数器252恢复。也就是说,非预测调用/返回堆栈254保持与处理器100中不存在未解析的非本地分支指令的情况下分支解码器208所遇到的调用指令相关联的返回地址。在这种情况下,推测指针258加载有非推测指针256的值,即,更新推测指针258以指向非推测调用/返回堆栈254。
各计数器252对从分配到相应的调用/返回堆栈254起分支解码器208所遇到的非本地分支指令的数量进行计数。在分支解码器208从遇到了一个或多个非本地分支指令起(这是由当前计数器252的值为非零所表示的)遇到第一个调用/返回指令的情况下(即,在分支解码器208使推入284/弹出286有效的情况下),调用/返回单元222分配新的调用/返回堆栈254。在这种情况下,调用/返回单元222在将返回地址推入/弹出新分配的调用/返回堆栈254之前,将当前调用/返回堆栈254的内容复制到新分配的调用/返回堆栈254并且将推测指针258更新为指向新分配的调用/返回堆栈254,以使得新分配的调用/返回堆栈254成为当前调用/返回堆栈254。与新分配的调用/返回堆栈254相关联的计数器252清零。注意,调用/返回指令之前的一个或多个非本地分支指令可以存在于同一微代码指令272序列中,在这种情况下,调用/返回单元222使当前计数器252递增并且分配推入/弹出返回地址的新的调用/返回堆栈254。每当执行流水线192解析非本地分支指令时,调用/返回单元222使非推测计数器252递减。在非推测计数器252递减至0的情况下,这表示不存在更多与非推测调用/返回堆栈254相关联的未解析的非本地分支指令,因此调用/返回单元222使非推测指针256递增以指向下一调用/返回堆栈254。
在一个实施例中,调用/返回单元222以与为了所有目的通过引用包含于此的美国专利号7,975,132中所述的微代码单元的快速调用/返回堆栈单元类似的方式运行,但调用/返回单元222被修改为容纳每时钟周期来自微代码ROM的多个微代码指令的获取而非每时钟周期单个微代码指令的获取。更具体地,如上所述,分支解码器208检测微代码指令272序列中处于程序顺序首位的本地分支指令之前的非本地分支指令的数量,并且调用/返回单元222使当前计数器252进行该数量而非1的递增。
优选地,微代码单元156还包括可由系统软件(例如,BIOS或操作系统,例如,经由x86写入模型专用寄存器(WRMSR)架构指令)进行写入以修补微代码的修补随机存取存储器(RAM)(未示出)和修补内容可寻址存储器(CAM)。修补CAM接收取指地址268及其3个递增值。如果取指地址268或者其递增值中的任何递增值与修补CAM中的地址发生碰撞,则修补CAM向修补RAM提供地址。响应于此,修补RAM提供微代码指令,并且复用器(未示出)从修补RAM而非来自微代码ROM 202的微代码指令272中选择微代码指令。
尽管描述了每时钟周期从微代码ROM 202获取到的微代码指令272的数量是4的实施例,但考虑到该数量多于或少于4但至少为2的其它实施例。此外,尽管描述了每时钟周期微代码转译器216所转译的微代码指令276的数量多达4个的实施例,但考虑到该数量多于或少于4但至少为2的其它实施例。最后,尽管描述了每时钟周期指令转译器104向执行流水线192提供的微指令134的数量多达4个的实施例,但考虑到该数量多于或少于4但至少为2的其它实施例。
现在参考图3,示出用于例示图2的微代码单元156的操作的流程图。流程从块302开始。
在块302中,地址生成器206将取指地址268提供至微代码ROM 202,微代码ROM 202响应于此将4个微代码指令272的微代码指令272序列提供至分支解码器208。流程进入块304。
在块304中,分支解码器208对微代码指令272序列进行解码以检测本地和非本地分支指令(如果存在)。流程进入块306。
在块306中,分支解码器208向调用/返回单元222提供微代码指令272序列中按程序顺序出现在程序顺序首位的本地分支指令之前的非本地分支指令的数量,其中该数量可以为零。响应于此,调用/返回单元222使当前计数器252进行该数量的递增。流程进入决定块308。
在决定块308中,分支解码器208判断程序顺序首位的本地分支指令是否为调用/返回指令。如果不是,则流程进入块314;否则,流程进入块312。
在块312中,如果程序顺序首位的本地分支指令是调用指令,则分支解码器208使得至调用/返回单元222的推入信号284有效,调用/返回单元222响应于此将目标地址266推入当前调用/返回堆栈254以提供至地址生成器206。然而,如果程序顺序首位的本地分支指令是返回指令,则分支解码器使得至调用/返回单元222的弹出信号286有效,调用/返回单元222响应于此将返回地址298弹出当前调用/返回堆栈254以提供至地址生成器206。流程进入块314。
在块314中,分支解码器向微代码指令队列212表示要将微代码指令272序列中的哪些微代码指令写入队列212。更具体地,如上所述,仅将微代码指令272序列中直到程序顺序首位的本地分支指令为止但不包括程序顺序首位的本地分支指令的微代码指令写入队列212。流程进入块316。
在块316中,分支解码器208对程序顺序首位的本地分支指令(如果存在)进行解析,并且将取指地址268更新为所解析的程序顺序首位的本地分支指令的目标地址266。否则,地址生成器206使取指地址268递增4。只要队列212不为空,则流程返回至块302以将下一微代码指令272序列获取到队列212中。
现在参考图4,示出用于例示图2的微代码单元156的操作的流程图。流程从块402开始。
在块402中,与图3中的从微代码ROM获取微代码指令的微代码指令272序列、由分支解码器208对该微代码指令272序列进行解码以及在本地分支指令的情况下对该微代码指令272序列进行解析、并且只要队列212不为空则将该微代码指令272序列写入队列212的操作并行地,微代码转译器216从队列212读取微代码指令并且将这些微代码指令转译成微指令以提供至执行流水线192。流程结束于块402。
尽管这里已经说明了本发明的各种实施例,但应理解,这些实施例仅是以示例而非限制性的方式所呈现的。对于计算机相关领域的技术人员应显而易见,在没有背离本发明的范围的情况下,可以对本发明进行形式和细节方面的各种修改。例如,软件例如可以启用这里所述的设备和方法的功能、制造、建模、模拟、说明和/或测试。这可以经由一般编程语言(例如,C、C++)、包括Verilog HDL、VHDL等的硬件描述语言(HDL)或其它可用程序的使用来实现。这些软件可以放置在诸如磁带、半导体、磁盘或光盘(例如,CD-ROM、DVD-ROM等)等的任何已知的计算机可用介质、网络、配线或其它通信介质中。这里所述的设备和方法的实施例可以包括在诸如(例如,以HDL实现或指定的)处理器核等的半导体知识产权核中并且在生产集成电路时转换成硬件。此外,这里所述的设备和方法可以作为硬件和软件的组合来实现。因而,本发明不应局限于这里所述的任何典型实施例,而应仅根据所附权利要求书及其等效物来限定。具体地,本发明可以在通用计算机中能够使用的处理器装置中实现。最后,本领域技术人员应理解,在没有背离由所附权利要求书限定的本发明的范围的情况下,他们可以容易地使用所公开的概念和特定实施例作为用于设计或修改其它结构的基础,以实施与本发明的目的相同的目的。
- 还没有人留言评论。精彩留言会获得点赞!
- 一种基于多片arm处理器的符合3u cpci标准尺寸的can接口控制板的利记博彩app
- 一种基于ARM Crotex-A15架构处理器的CPCI板卡的利记博彩app
- 用于将处理器架构状态保存在高速缓存层级中的方法和装置的制造方法
- 动态处理器-存储器再向量化架构的利记博彩app
- 一种基于PowerPC的多处理器通讯架构的利记博彩app
- 线程优化的多处理器架构的利记博彩app
- 多处理器系统之多向可安装架构的利记博彩app
- 用于在具有分布式消息处理器架构的 Diameter 信令路由器(DSR)内屏蔽Diameter 消息 ...的利记博彩app
- 一种支持多芯片架构的基带信号处理器及其处理方法
- 一种amp架构下处理器负载均衡的实现方法及装置的利记博彩app