一种基于区域分割的控制方法及系统与流程
本发明涉及物联网领域,特别是涉及一种基于区域分割的控制方法及系统。
背景技术:
粒子群算法是近年来由J.Kennedy和R.C.Eberhart等开发的一种新的进化算法,其数学理论如下:在一个D维搜索区域(解空间)内存在N个粒子,每个粒子被视为D维搜索空间的一个搜索个体,描述粒子状态的参数有两个,分别为速度与位置,粒子根据自身的经验(个体历史最优)和群体经验(群体历史最优)来指导自己的“飞行”(即通过速度的变化来改变位置),粒子速度与位置分别进行更新,最终得到最优解。粒子群算法属于进化算法的一种,从随机解出发,通过迭代寻找最优解,通过适应度来评价解的品质,但它比遗传算法规则更为简单,它没有遗传算法的“交叉”和“变异”操作。
粒子群算法,用于物联网系统中,目的是降低无线传感节点的功耗,从而延长物联网中无线传感节点的使用周期。现有的粒子群算法或提高了算法的收敛速度确无法提高算法的收敛精度,或提高了算法的收敛精度却无法提高算法的收敛速度,这就使得现有的粒子群算法存在着收敛速度与收敛精度之间相互矛盾的缺点,也就使得物联网系统中无线传感节点的功耗增加,从而缩短了物联网中无线传感节点的使用周期。
技术实现要素:
本发明的目的是提供一种基于区域分割的控制方法及系统,通过设计单个粒子的指数递减惯性权重,然后通过信息交叉优化进行区域分割,通过柯西算子进行粒子自适应变异,以实现不大幅增加计算复杂度的前提下提高收敛速度并提高收敛精度,从而降低物联网系统中无线传感节点的功耗,延长物联网中无线传感节点的使用周期。
一种基于区域分割的控制方法,所述方法包括:
获取搜索区域S与目标函数fit;
获取设定的迭代次数、相关系数及区域分割边界,所述相关系数包括设定的迭代次数;
在所述搜索区域内获取所述目标函数粒子历史最优位置与全局最优位置的欧氏距离,根据所述欧式距离计算粒子惯性权重;
根据所述惯性权重更新粒子速度;
根据所述粒子速度更新粒子位置;
根据更新后的粒子速度与更新后的粒子位置进行区域分割;
判断区域分割后的粒子是否满足自适应变异条件;
若不满足,返回所述根据惯性权重更新粒子速度的步骤;
若满足,对所述粒子进行自适应变异;
根据所述自适应变异后的粒子的速度与位置更新个体历史最优解pbest和群体历史最优解gbest;
判断当前的迭代次数是否小于所述设定的迭代次数值;
若是,将所述当前迭代次数加1,返回所述根据惯性权重更新粒子速度的步骤;
若否,根据更新后的个体历史最优解和群体历史最优解计算全局最优解。
可选的,所述获取相关系数具体包括:获取系数a,b,c,d,其中a=0.5,b=50,c=0.35,d=0.8。
可选的,所述计算惯性权重具体包括:
利用公式计算惯性权重;
其中,Lij为第i次迭代中的第j个粒子历史最优位置与全局最优位置的欧氏距离,D表示搜索区域维度,gk表示全局最优位置在k维上的分量,pjk为第j个粒子历史最优位置在k维上的分量,ωmax为0.9,ωmin为0.4,Lmax表示搜索区域的所有粒子欧氏距离的最大值,ti为当前迭代次数,tmax为设定的迭代次数。
可选的,所述根据惯性权重更新粒子速度具体包括:
利用公式
vij(t+1)=ωijvij(t)+c1r1(pbestij(t)-xij(t))+c2r2(gbestg(t)-xij(t))更新粒子速度,其中t是迭代次数,c1为自身加速常数,c2为全局加速常数,r1和r2是[0,1]之间的随机数,vij(t)表示第t次迭代中粒子i的速度在j维上的分量,vij(t+1)表示第t+1次迭代中粒子i的速度在j维上的分量,ωij为惯性权重,pbestij(t)为第t次迭代中粒子i的个体历史最优解,gbestg(t)为t次迭代中群体历史最优解,xij(t)为第t次迭代中粒子i的位置在j维上的分量。
可选的,所述更新粒子位置具体包括:利用公式xij(t+1)=xij(t)+vij(t+1)更新粒子位置,其中vij(t+1)表示第t+1次迭代中粒子i的速度在j维上的分量,xij(t)表示第t次迭代中粒子i的位置在j维上的分量,xij(t+1)表示第t+1次迭代中粒子i的位置在j维上的分量。
可选的,所述进行区域分割具体包括:
(1)在所述搜索区域内,按照粒子到全局最优位置的欧氏距离进行排序,以欧氏距离设定值为界,将粒子搜索区域分成两部分:界限内区域与界限外区域,界限内区域的粒子定义为第一粒子,界限外区域的粒子定义为第二粒子;
(2)从所述第一粒子中选择两个粒子j和k,利用公式Vi=aVj+(1-a)Vk和Xi=aXj+(1-a)Xk进行交叉操作,即将粒子j和粒子k的速度和位置按预设权重比例进行交叉,生成一个新粒子i的速度及位置信息,其中Vj为粒子j的速度,Vk为粒子k的速度,Vi为新粒子i的速度,Xj为粒子j的位置坐标,Xk为粒子k的位置坐标,Xi为新粒子i的位置坐标,a为常数,在[0,1]之间;
(3)用新粒子i的信息取代一个所述第二粒子的信息;
(4)执行步骤(2)和(3)直到所有所述第二粒子被取代,从而形成新的种群;
(5)反复执行步骤(1)~(4),多次分割搜索区域至分割次数达到预设值。
可选的,所述判断粒子是否满足自适应变异条件具体包括:
判断粒子j是否至少满足以下条件之一:
(3)群体历史最优解gbest在连续b次迭代内均无改善,b的理想取值为:若满足即为粒子满足自适应变异条件;
(4)粒子j与全局最优粒子k的距离函数s(l)满足若满足即为粒子满足自适应变异条件,其中s(l)为粒子j与全局最优粒子k的距离函数,lkj为粒子j与全局最优粒子k之间的欧氏距离,n为粒子个数,c为[0,1]之间的常数,D为搜索区域。
可选的,所述对所述粒子进行自适应变异具体包括:
利用公式和对粒子j进行自适应变异,其中Vj1,为粒子j变异前速度,Vj2为粒子j变异后速度,Xj1为粒子j变异前位置坐标,Xj1为粒子j变异后位置坐标,rand为为[0,1]之间随机值生成函数,用于产生一个[0,1]的随机值。
可选的,所述系统包括:
搜索区域与目标函数获取模块,用于获取搜索区域S与目标函数fit;
设定的迭代次数、相关系数及区域分割边界获取模块,用于获取设定的迭代次数、相关系数及区域分割边界;
距离计算模块,用于在所述搜索区域内计算所述目标函数粒子历史最优位置与全局最优位置的欧氏距离;
惯性权重计算模块,用于计算惯性权重;
粒子速度更新模块,用于根据所述惯性权重更新粒子速度;
粒子位置更新模块,用于更新粒子位置;
区域分割模块,用于进行区域分割;
自适应变异条件判断模块,用于判断粒子是否满足自适应变异条件;
自适应变异模块,用于当满足所述自适应变异条件时,对所述粒子进行自适应变异;
最优解更新模块,用于更新个体历史最优解pbest和群体历史最优解gbest;
迭代次数判断模块,用于判断当前迭代次数是否小于设定的迭代次数值;
迭代次数控制模块,用于当当前迭代次数小于设定的迭代次数值时,将所述当前迭代次数加1;
全局最优解计算模块,用于当当前迭代次数不小于设定的迭代次数值时,计算全局最优解。
根据本发明提供的具体实施例,本发明的有益效果为:
通过设计单个粒子的指数递减惯性权重,然后通过信息交叉优化进行区域分割,通过柯西算子进行粒子自适应变异,在保持低的计算复杂度的前提下提高了收敛速度同时提高了收敛精度,从而降低了物联网系统中无线传感节点的功耗,延长了物联网中无线传感节点的使用周期。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
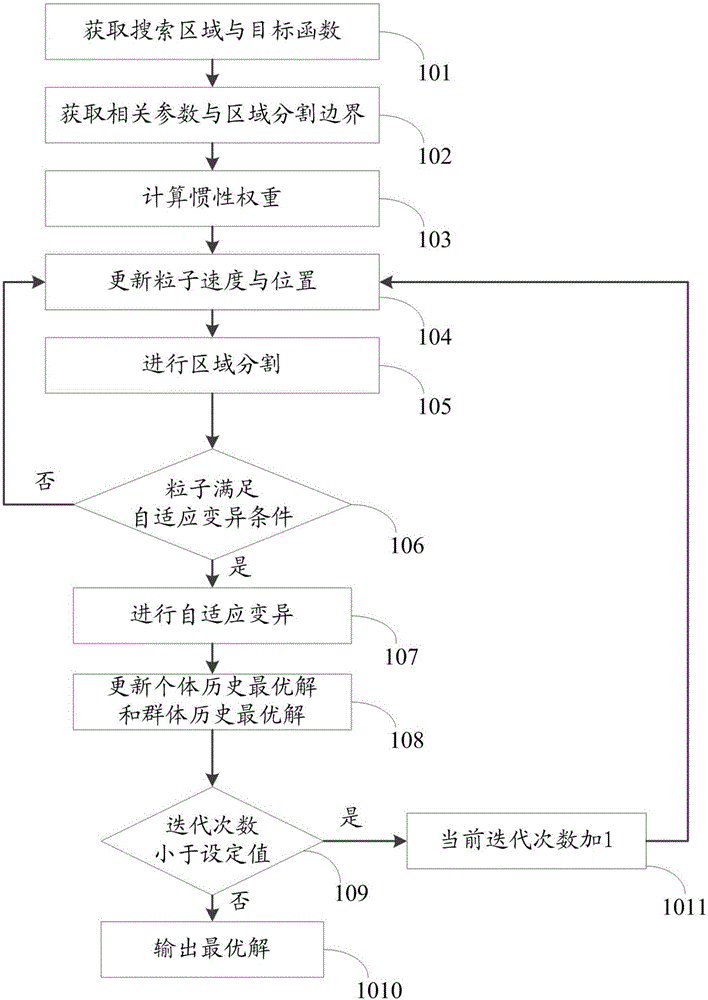
图1为本发明基于区域分割的控制方法流程图;
图2为本发明基于区域分割的控制方法实施例1的收敛曲线图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种基于区域分割的控制方法及系统,通过设计单个粒子的指数递减惯性权重,然后通过信息交叉优化进行区域分割,通过柯西算子进行粒子自适应变异,以实现不增加计算复杂度的前提下提高收敛速度并提高收敛精度,从而降低物联网系统中无线传感节点的功耗,延长物联网中无线传感节点的使用周期。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为本发明基于区域分割的控制方法流程图。如图1所示,所述方法包括:
步骤101:获取搜索区域与目标函数,例如,一维搜索区域可以设其搜索区间为[-a,a];目标函数即为待分析的函数,例如,可以为
步骤102:根据搜索区域和目标函数获取相关系数及区域分割边界,所述相关系数包括设定的迭代次数等其他系数;对于分割边界,例如,一维搜索区域搜索区间为[-a,a],可以设其区域分割边界为fr,则其对应的分割区间为[-fr,fr];
步骤103:在搜索区域内获取目标函数粒子历史最优位置与全局最优位置的欧氏距离,根据所述欧式距离计算粒子惯性权重ωij,具体为:
其中,Lij为第i次迭代中的第j个粒子历史最优位置与全局最优位置的欧氏距离,D表示搜索区域维度,gk表示全局最优位置在k维上的分量,pjk为第j个粒子历史最优位置在k维上的分量,ωmax为0.9,ωmin为0.4,Lmax表示搜索区域的所有粒子欧氏距离的最大值,ti为当前迭代次数,tmax为设定的迭代次数。
显然,从而推得也即保证了ωij在(0.4,0.9)理想区间,同时也使线性递减权重优化为指数的非线性递减权重,使粒子速度变化呈现出前期快后期慢的特征,更好地平衡全局搜索与局部挖掘;更为重要的是在同一次迭代中,不同的粒子根据其与全局最优位置的欧氏距离不同而被赋予不同的惯性权重,离全局最优位置越远的粒子以越快的速度向其靠近,而在全局最优位置附近的粒子则做小范围精细探索,增大发现全局最优位置的概率,从而在大大提高收敛速度的同时也很好地兼顾了发现新的最优解的概率,因此充分利用粒子的差异性提高了算法的收敛速度。
步骤104:利用步骤103中得到的惯性权重更新粒子速度,并根据所述粒子速度更新粒子位置,具体为:
利用vij(t+1)=ωijvij(t)+c1r1(pbestij(t)-xij(t))+c2r2(gbestg(t)-xij(t))更新粒子速度,其中t是迭代次数,c1为自身加速常数,c2为全局加速常数,r1和r2是[0,1]之间的随机数,vij(t)表示第t次迭代中粒子i的速度在j维上的分量,vij(t+1)表示第t+1次迭代中粒子i的速度在j维上的分量,ωij为惯性权重,pbestij(t)为第t次迭代中粒子i的个体历史最优解,gbestg(t)为t次迭代中群体历史最优解,xij(t)为第t次迭代中粒子i的位置在j维上的分量。
利用公式xij(t+1)=xij(t)+vij(t+1)更新粒子位置,其中vij(t+1)表示第t+1次迭代中粒子i的速度在j维上的分量,xij(t)表示第t次迭代中粒子i的位置在j维上的分量,xij(t+1)表示第t+1次迭代中粒子i的位置在j维上的分量。
步骤105:根据更新后的粒子速度与粒子位置进行区域分割,具体操作步骤为:
(1)在所述搜索区域内,按照粒子到全局最优位置的欧氏距离进行排序,以欧氏距离设定值为界,设定值为0.5*Lmax(Lmax为所有粒子到全局最优位置的欧氏距离的最大值),将粒子搜索区域分成两部分:界限内区域与界限外区域,界限内区域的粒子定义为第一(较优)粒子,界限外区域的粒子定义为第二(较劣)粒子;
(2)从所述第一(较优)粒子中选择两个粒子j和k,利用公式Vi=aVj+(1-a)Vk和Xi=aXj+(1-a)Xk进行交叉操作,即将粒子j和粒子k的速度和位置按预设权重比例进行交叉,生成一个新粒子i的速度及位置信息,其中Vj为粒子j的速度,Vk为粒子k的速度,Vi为新粒子i的速度,Xj为粒子j的位置坐标,Xk为粒子k的位置坐标,Xi为新粒子i的位置坐标,a为常数,在[0,1]之间;
(3)用新粒子i的信息取代一个所述第二(较劣)粒子的信息;
(4)执行步骤(2)和(3)直到所有所述第二(较劣)粒子被取代,从而形成新的种群;
(5)反复执行步骤(1)~(4),多次分割搜索区域至分割次数达到预设值。
由于采用了用第一(较优)粒子交叉信息取代第二(较劣)粒子措施,导致第二(较劣)粒子很快收敛于第一(较优)粒子的界限内,使搜索区域快速收敛,克服了传统的粒子群算法(Particle Swarm Optimization,PSO)中粒子受最大速度及方程的限制而只能一步步向最优解靠近的不足,同时粒子的运动不再仅仅由个体最优和全局最优两个参数决定,随机选择用于交叉的两粒子信息也对粒子的运动产生重要影响,从而降低了收敛精度的问题。
以一维搜索区域为例,设其搜索区间为[-a1,a1],经过交叉后粒子集中于[-fr1,fr1]中,从而形成新的搜索区域[-a2,a2],再次交叉后粒子集中于[-fr2,fr2],形成更小搜索区域[-a3,a3],接着交叉后粒子集中于[-fr3,fr3]......,其中,fr=a1,fr1=a2,fr2=a3,通过不断循环迭代分割区域最终使所有粒子均集中于最优解附近。这里的关键是较优粒子是随机选择,而并非是选择两个最优粒子进行交叉,也就是说较劣粒子被取代的本质不是向最优粒子或者某个特定粒子靠拢,而是向整个界限内靠近,从而既达到收敛的目的同时也保证了粒子的多样性。
步骤106:判断区域分割后的粒子是否满足自适应变异条件,若是,执行步骤107,若否,返回步骤104。基于之前的改进,算法的收敛速度及收敛精度均有大幅提高,但仍有可能陷入局部最优而无法跳出。因此,在此基础上进行自适应变异条件判断:迭代进行到一定代数,此时粒子集中于极小的区域内,粒子的位置Vi与pbest和gbest非常接近,导致粒子运动速度几乎为0,进化陷于停滞。此时可根据粒子与全局最优粒子的亲和力(粒子与全局最优粒子欧氏距离越小,则两者亲和力越大;反之亦然)判断是否采取自适应变异操作。具体判断条件为:
判断粒子j是否至少满足以下条件之一:
(1)群体历史最优解gbest在连续b次迭代内均无改善,b的理想取值为:若满足即为粒子满足自适应变异条件;
(2)粒子j与全局最优粒子k的距离函数s(l)满足若满足即为粒子满足自适应变异条件,其中s(l)为粒子j与全局最优粒子k的距离函数,lkj为粒子j与全局最优粒子k之间的欧氏距离,n为粒子个数,c为[0,1]之间的常数,D为搜索区域。
步骤107:对粒子进行自适应变异操作,粒子执行自适应变异的前提为粒子满足集中极小区域的条件,自适应变异操作采用以下策略:
(1)粒子以其与全局最优粒子的欧氏距离大小决定其变异概率,此概率表达为:其中Lij为第i次迭代中的第j个粒子历史最优位置与全局最优位置的欧氏距离,Lmax表示搜索区域的所有粒子欧氏距离的最大值,d为变异概率调节因子,其值在[0,1]之间。从而p在[0,d]之间,且lkj越小则p越大,也即粒子离全局最优粒子越近则以越大概率产生扰动,从而更可能探索新区域,增大发现最优解的概率。
(2)若粒子产生变异,也即[0,1]之间随机产生函数rand≤p,则对产生变异的粒子j执行以下操作以生成新的速度与位置:
其中引入的柯西变异算子Cauchy的表达式为:Vj1为粒子j变异前速度,Vj2为粒子j变异后速度,Xj1为粒子j变异前位置坐标,Xj1为粒子j变异后位置坐标,rand为[0,1]之间随机值生成函数,用于产生一个[0,1]的随机值。
Cauchy算子的作用是保证数列的收敛性,从而保证粒子的速度与位置不会因为变异过大而无法收敛。由因子项可知,粒子与全局最优粒子亲和力越大,则其变异的速度和位置越大,从而保证粒子在更大区域进行搜索,提高了粒子的多样性以及在更大区域内发现新解的概率;引入与当前迭代次数相关的指数衰减因子使其与迭代次数关联起来,可使粒子变异的速度及位置而在迭代后期不致过大;进一步引入rand函数增加了粒子的随机性和独立性。
步骤108:根据所述自适应变异后的粒子的速度与位置更新个体历史最优解pbest和群体历史最优解gbest;
步骤109:判断当前的迭代次数是否小于设定的迭代次数值,若是,执行步骤1011,若否,执行步骤1010;
步骤1010:根据更新后的个体历史最优解和群体历史最优解计算全局最优解,全局最优解即为群里历史最优解。
步骤1011:当前迭代次数加1,返回步骤104。
图2为本发明基于区域分割的控制方法实施例1的收敛曲线图。选择对比的算法:标准PSO;GLbest-PSO算法,此算法将全局最优与局部最优引入惯性权重中;ALEMSPSO算法,此算法将群体分为自主学习和精英群的多子群,不同种群进行通信来确定全局最优;EICS-CPSO算法,此算法采用免疫克隆选择的策略并采用协同进化的思想保持种群多样性。
实验环境设定:实验硬件环境为Pentium(R)Dual-Core CPUE5800(3.2GHz),内存为4GB,软件平台为MATLAB 2014a。算法采用统一参数设置,为了减少偶然误差带来的随机性,实验均重复30次,结果为30次均值,种群大小N=30,最大迭代次数T=1000,c1=c2=1.495。不同算法的独立参数均按原算法设置。
固定迭代次数T=1000,其他设置均不变。
对比的指标为在不同测试函数的收敛速度及收敛精度,如图2所示,本发明中基于区域分割的自适应变异粒子群算法(Regional-segmentation self-adapting variation particle swarm optimization,RSVPSO)在这两个最为重要的指标上均有明显优势。其较好的收敛性得益于其采用了动态非线性惯性权重,该策略使粒子的速度随权重灵活递减,同时信息交叉使粒子速度及位置变化远比基本粒子群算法快,大大提高了粒子搜索效率;最后基于柯西算子的自适应变异也增大了粒子逃出局部最优的能力,从而保证了粒子搜索解的精度。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!