一种TM4SF1特异性嵌合抗原受体及其应用的利记博彩app
本发明涉及生物免疫领域,具体地,本发明涉及一种tm4sf1特异性嵌合抗原受体及其应用。
背景技术:
嵌合抗原受体(car)由抗原识别区、跨膜区、胞内信号区构成,一般通过病毒转导或者电穿孔,使car分子表达在t细胞表面形成car-t细胞。car-t细胞通过胞外抗原识别区识别肿瘤抗原,招募t细胞到肿瘤细胞表面,并通过胞内信号区激活t细胞,使t细胞行使杀伤作用,以杀伤肿瘤细胞,从而达到治疗肿瘤的目的。car分子的设计根据胞内信号区的不同经过了四代的发展,其中第一代car分子仅包含cd3ζ;第二代car分子除cd3ζ之外还包含一个共刺激因子,例如cd28,cd137,ox40等;第三代car分子同时包含串联的两个共刺激因子;第四代car分子中包含了il-12等能改善肿瘤微环境的细胞因子。car-t通过靶向cd19分子在血液肿瘤方向取得突破性进展,部分研究中有效率达到了90%。但是,car-t在实体瘤领域一直没有突破,所以迫切需要新的肿瘤靶点,新的car分子设计以促进其在实体瘤领域的应用。
tm4sf1(transmembrane-4lsixfamilymember1)是一个整合在细胞质膜上的糖蛋白,在多种癌症细胞中高度表达,包括肝细胞癌,非小细胞肺癌等;tm4sf1还高度表达在人癌症血管的内皮细胞上。tm4sf1同时在多种组织器官中存在微弱的表达。tm4sf1功能在于能够调控多种肿瘤细胞的运动性和粘附性。由于tm4sf1在多种肿瘤细胞中高表达同时与肿瘤内血管的生成有关,所以是一个潜在的肿瘤治疗靶点。
技术实现要素:
本发明的目的在于克服现有技术中的缺陷,提供一种新的通过靶向tm4sf1的car分子,并证明其在实体瘤治疗中的潜在应用。具体的说,本发明提供一种tm4sf1特异性嵌合抗原受体(car),这种car分子通过靶向肿瘤细胞表面的tm4sf1蛋白并激活t细胞下游的信号通路,赋予t细胞杀伤带有tm4sf1靶点肿瘤细胞的能力。
为实现上述目的,本发明采用如下技术方案:
本发明的第一个目的是提供一种tm4sf1特异性嵌合抗原受体,其包括包括胞外识别区、铰链区、跨膜区和胞内信号区;其中,胞外识别区为抗-tm4sf1抗体序列。
为了进一步优化上述tm4sf1特异性嵌合抗原受体,本发明所采取的技术措施还包括:
优选地,所述抗-tm4sf1抗体序列为一种结合tm4sf1的单链可变区(scfv)序列,更优选地,在本发明一实施例中,该抗体序列为来源于本领域已公开的tm4sf1单克隆抗体l6,该tm4sf1单克隆抗体l6包括如seqidno.1所示的重链可变区(vh)氨基酸序列和如seqidno.2所示的轻链可变区(vl)氨基酸序列。
进一步地,根据scfv的构成规则,vh和vl序列通过一段柔性linker氨基酸序列为ggggsggggsggggs连接到一起,形成scfv序列。
优选地,所述铰链区为cd8hinge区域,其氨基酸序列如seqidno.3所示。
优选地,所述跨膜区所述跨膜区为cd8跨膜区或cd28跨膜区中的任一个,其中,所述cd8跨膜区的氨基酸序列如seqidno.4所示,所述cd28跨膜区的氨基酸序列如seqidno.5所示。
优选地,所述胞内信号区包含cd28、4-1bb、cd3ζ中的至少一个;更优选地,所述胞内信号区为cd28、4-1bb和cd3ζ中的至少两个的串联。其中,所述cd28的氨基酸序列如seqidno.6所示,所述4-1bb的氨基酸序列如seqidno.7所示,所述cd3ζ的氨基酸序列如seqidno.8所示。
进一步地,所述胞内信号区为t细胞信号传导激活区域。
优选地,基于以上tm4sf1car分子的结构,本发明所述的该嵌合抗原受体包括l6-28z、l6-bbz、l6-28bbz中的任一个,其结构如图1所示;其中,所述l6-28z的氨基酸序列如seqidno.9所示,所述l6-bbz的氨基酸序列如seqidno.10所示,所述l6-28bbz的氨基酸序列如seqidno.11所示。可以理解的是,也可根据本领域适用的其他结构来组成tm4sf1嵌合抗原受体。
具体地,在不同的car分子中,其跨膜区可相同,也可不同;其胞内信号区可相同,也可不同。
优选地,在本发明一具体实施例中,若tm4sf1嵌合抗原受体为l6-28z,则其跨膜区为cd8,其胞内信号区为cd28-cd3ζ;若tm4sf1嵌合抗原受体为l6-bbz,则其跨膜区为cd8,其胞内信号区为4-1bb-cd3ζ;若tm4sf1嵌合抗原受体为l6-28bbz,则其跨膜区为cd28,其胞内信号区为cd28-4-1bb-cd3ζ。
本发明的第二个目的是提供一种编码上述tm4sf1特异性嵌合抗原受体的核酸。
优选地,所述核酸的核苷酸序列包括seqidno.12~seqidno.14所示序列。更具体地说,seqidno.12所示序列的核酸编码l6-28z,seqidno.13所示序列的核酸编码l6-bbz,seqidno.14所示序列的核酸编码l6-28bbz。
car分子的氨基酸序列及其编码核酸序列如下表所示:
本发明的第三个目的是提供一种含有编码上述tm4sf1特异性嵌合抗原受体的核酸的重组表达载体。
优选地,所述重组表达载体包括慢病毒、逆转录病毒、腺病毒、腺相关病毒或质粒等;更优选地,在本发明一实施例中,原始重组表达载体为慢病毒。具体的,在该实施例中所使用的载体为慢病毒载体pcdh-ef1-mcs-t2a-copgfp(以下简写为pcdh),其图谱见图2。在该载体中,car分子的表达由ef1启动子驱动转录表达,带有gfp标记基因作为慢病毒转导的标志。car慢病毒载体质粒在辅助包装质粒pspax2和vsv-g包膜质粒pmd2.g存在的情况下,共转染hek293t细胞,即可包装为带有car分子的慢病毒。
本发明的第四个目的是提供一种含有编码上述tm4sf1特异性嵌合抗原受体的核酸的重组表达载体的宿主细胞。
优选地,所述宿主细胞为t细胞或含有t细胞的细胞群。
本发明还涉及一种上述宿主细胞的构建方法,其包括重组表达载体的构建步骤、重组表达载体的包装步骤以及将重组表达载体转导至宿主细胞的步骤。
最后,本发明还提供一种上述tm4sf1特异性嵌合抗原受体,上述编码tm4sf1特异性嵌合抗原受体的核酸,上述重组表达载体以及宿主细胞在哺乳动物肿瘤治疗中的应用。
优选地,哺乳动物实体肿瘤包括但不限于,肾脏肿瘤、神经母细胞瘤、生殖细胞瘤、骨肉瘤、软骨肉瘤、软组织肉瘤、肝脏肿瘤、胸腺瘤、肺母细胞瘤、胰母细胞瘤、血管瘤等。
更具体的说,上述应用为一种tm4sf1car-t细胞,其通过慢病毒介导的转导使得t细胞带有tm4sf1car,从而赋予了t细胞识别tm4sf1分子的能力,并靶向tm4sf1阳性的哺乳动物实体肿瘤。
在一个实施例中,将tm4sf1car-t细胞与表达tm4sf1的肿瘤细胞系calu-3,calu-6-tm4sf1共孵育,结果显示tm4sf1car-t细胞能够在靶细胞的刺激下大量的产生ifn-γ;但是却不能在与tm4sf1阴性的细胞系calu-6共孵育时产生ifn-γ;同时非tm4sf1靶向的car-t细胞19-28bbz不能够在tm4sf1阳性细胞刺激下产生ifn-γ。该实施例说明了tm4sf1car-t细胞的良好的特异性靶向性,能够在tm4sf1刺激下将t细胞杀伤功能激活。
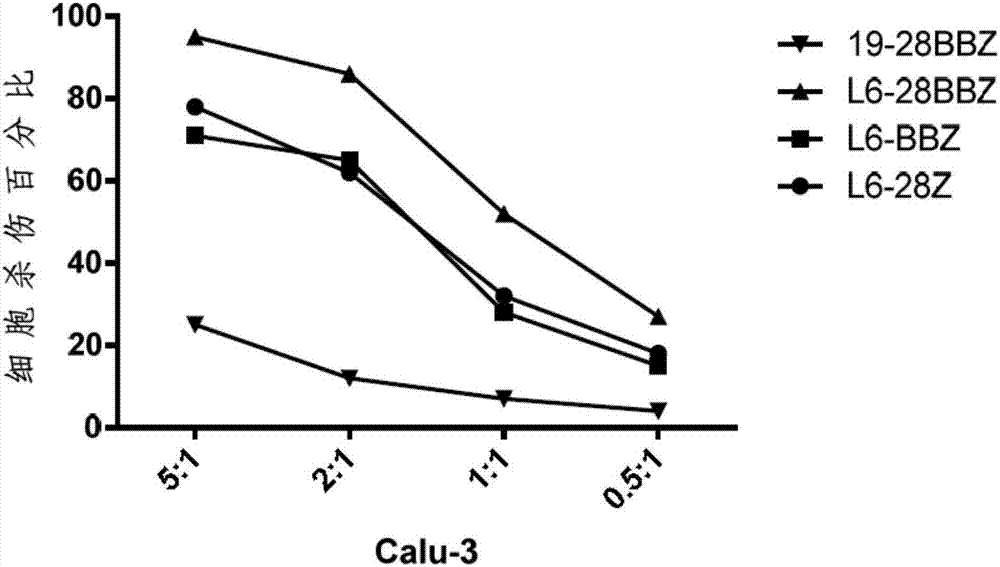
在另一实施例中,证明了在一定的效靶比(car-t细胞:靶细胞)下,tm4sf1car-t细胞能够有效的杀伤tm4sf1阳性的肿瘤细胞;但是非tm4sf1靶向的car-t细胞19-28bbz不能够有效杀伤靶细胞。该实施例说明了tm4sf1car-t能够在体外能够有效的裂解tm4sf1阳性的肿瘤细胞。
在另一实施例中,基于tm4sf1阳性肺癌细胞系calu-3构建了nod-scid免疫缺陷鼠皮下移植肿瘤模型。使用本发明tm4sf1car-t细胞l6-28bbz治疗该荷瘤小鼠,结果说明,tm4sf1car-t细胞可以有效清除tm4sf1阳性肿瘤细胞,并且治疗组的小鼠在30天全部存活;但是对照19-28bbz组中肿瘤不断长大,并且在30天时仅有20%小鼠存活下来。
与现有技术相比,本发明具有以下有益效果:
当前car-t技术在实体瘤领域的应用并不成功,一个很重要的原因就是缺少合适的实体瘤靶点。本发明提供了一个新的通过car-t技术靶向实体瘤的靶点tm4sf1,该基因在正常组织细胞中不表达或仅少量表达,而在肺癌,肝癌等实体肿瘤组织以及肿瘤血管内皮细胞中高度表达,特别是在肿瘤干细胞上高表达。本发明所述的tm4sf1car分子可以通过修饰t细胞,并使特异性car-t细胞高效特异的治疗tm4sf1阳性实体肿瘤。
附图说明
图1为tm4sf1特异性嵌合抗原受体(car)分子结构的说明示意图;
图2为慢病毒载体pcdh结构的说明示意图;
图3为tm4sf1car分子酶切鉴定电泳的结果示意图;
图4为流式细胞术检测tm4sf1转导t细胞转导效率的结果示意图;
图5为不同肿瘤细胞系中tm4sf1表达水平的示意图;
图6为tm4sf1car-t细胞ifn-γ分泌情况的示意图;
图7a和图7b为tm4sf1car-t细胞体外杀伤tm4sf1靶细胞的结果示意图;
图8a和图8b为tm4sf1car-t细胞小鼠体内杀伤tm4sf1阳性移植肿瘤的结果示意图。
具体实施方式
本发明提供一种tm4sf1特异性嵌合抗原受体(即靶向tm4sf1的car分子),其包含胞外识别区、铰链区、跨膜区和胞内信号区,其中胞外识别区为抗-tm4sf1抗体序列(scfv序列,seqidno.1以及seqidno.2),铰链区为cd8hinge区域(seqidno.3),跨膜区为cd8跨膜区(seqidno.4)或cd28跨膜区(seqidno.5)中的任一个,胞内信号区包含cd28(seqidno.6)、4-1bb(seqidno.7)、cd3ζ(seqidno.8)中的至少一个。
本发明的嵌合抗原受体具体为l6-28z(seqidno.9)、l6-bbz(seqidno.10)和l6-28bbz(seqidno.11),其分别由seqidno.12~seqidno.14所示序列的核酸编码。
本发明在实施例一提供了构建上述car分子到慢病毒载体pcdh中的方法。实施例二中提供了将car分子包装成为慢病毒,转导t细胞,测定转染效率的方式。实施例三提供了构建tm4sf1靶细胞,以及car-t细胞杀伤tm4sf1靶细胞的能力。实施例四提供了car-t细胞在小鼠模型中抑制tm4sf1阳性肿瘤生长的能力。
下面结合附图和实施例,对本发明的具体实施方式作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
实施例一
本实施例提供了构建上述car分子到慢病毒载体pcdh中的方法。
通过本实施例构建tm4sf1car分子,根据car分子信号区域的不同,将其分为了l6-28z,l6-bbz,l6-28bbz三种:其中l6-28z中采用的胞内信号区为cd28-cd3ζ;l6-bbz中采用的胞内信号区为4-1bb-cd3ζ;而在l6-28bbz中所采用的胞内信号区为cd28-4-1bb-cd3ζ,其分子结构模式图如图1所示。通过常规分子克隆手段将如上car分子构建到了慢病毒载体pcdh中,慢病毒载体pcdh的结构如图2所示。
l6-28bbz载体构建:首先化学合成了l6-28bbz核酸片段至puc57载体中(上海奥吉生物有限公司),使用noti/xbai双酶切得到l6-28bbz片段。noti/xbai双酶切慢病毒载体pcdh,电泳后凝胶回收7kb大小左右dna片段。将l6-28bbz与载体pcdh使用t4dna连接酶,室温连接1-2小时,随后转化stbl3感受态细胞。第二天接种单菌落至lb扩增培养,并提取质粒。使用ncoi酶切验证所得质粒是否正确,酶切结果见图3,第二泳道。将正确质粒送测序,进一步验证其序列是否正确。留下正确的质粒命名为pcdh-l6-28bbz进行下一步实验。
l6-28z载体构建:首先化学合成了l6-28z的铰链区、跨膜区和胞内区序列puc57-28z(上海奥吉生物有限公司合成)。将puc57-28z和pcdh-l6-28bbz分别进行bamhi/noti双酶切,并电泳回收。将pcdh-l6-28bbz与28z用t4dna连接酶,室温连接1-2小时,随后转化stbl3感受态细胞。第二天接种单菌落至lb扩增培养,并提取质粒。使用ncoi酶切验证所得质粒是否正确,酶切结果见图3,第三泳道。将正确质粒送测序,进一步验证其序列是否正确。留下正确的质粒命名为pcdh-l6-28z进行下一步实验。
l6-bbz载体构建:使用引物bbf(5’-aaacggggcagaaagaaactcctgt-3’,seqidno.17)和cd3zr(5’-gcgagggggcagggcctgcatgtga-3’,seqidno.18),以l6-28bbz为模板进行pcr扩增bbz信号区序列;用引物carf(5’-atggccttaccagtgaccgccttgc-3’,seqidno.19)和cd8tmr(5’-gcagtaaagggtgataaccagtgac-3’,seqidno.20),以l6-28z为模板扩增l6scfv,cd8铰链区和跨膜区序列。之后进行搭桥pcr将前后两部分序列拼接为完整l6-bbz,引物为carf2(5’-ctagctagcatggccttaccagtgaccgccttgc-3’,seqidno.21)和cd3zr2(5’-cgggatccgcgagggggcagggcctgcatgtga-3’,seqidno.22)两者分别使用并分别进行noti/xbai双酶切,并电泳回收。并用t4dna连接酶,室温连接1-2小时,随后转化stbl3感受态细胞。第二天接种单菌落至lb扩增培养,并提取质粒。使用ncoi酶切验证所得质粒是否正确,酶切结果见图3,第四泳道。将正确质粒送测序,进一步验证其序列是否正确。留下正确的质粒命名为pcdh-l6-bbz进行下一步实验。
实施例二
本实施例为tm4sf1car-t细胞的构建。
car慢病毒的包装:首先使用qiagen无内毒素大提质粒试剂盒分别提取实施例一构建的慢病毒质粒pcdh-l6-28z、pcdh-l6-bbz、pcdh-l6-28bbz、pcdh-19-28bbz(非靶向tm4sf1对照car分子质粒)以及慢病毒系统辅助包装质粒pmd2.g和pspax2。在转染前一天将2.5×10e7293t铺至t75培养瓶中。转染前1小时将293t细胞培养基换为10ml无血清培养基。使用磷酸钙沉淀法将质粒共转染到293t细胞中,转染后24小时将细胞培养基换为15ml完全培养基dmem+10%fbs。转染后48小时收取细胞上清,并加入15ml新鲜完全培养基。72小时再次收取细胞上清,弃去细胞。将收取的细胞上清使用0.45um滤膜过滤,之后5000g离心1min以去除杂质。随后40000g离心2小时,沉淀病毒,使用0.1mlpbs重悬病毒。放置-80℃冻存备用。
t细胞转导:采用常规方法采血并分离pbmc,在含有5%人ab血清和300iu/ml白细胞介素-2的x-vivo15培养基中,并用抗cd3/cd28单克隆抗体刺激。开始培养以后48小时,将活化t细胞悬浮于含有硫酸鱼精蛋白和300iu/il-2的x-vivo15培养基中,加入相应慢病毒(l6-28z,l6-bbz,l6-28bbz或者19-28bbz)。然后将t细胞在37℃培养3小时。然后用rpmi培养基+10%胎牛血清和il-2将上清液稀释2倍,将t细胞在稀释的上清液中过夜培养,然后返回x-vivo15培养基(含有il-2,5%人ab血清)中培养。72小时后利用流式细胞术检测gfp表达以检测car分子转导效率。如图4所示,观察到l6-28z,l6-bbz,l6-28bbz,19-28bbz在t细胞上阳性率大约在60%-70%,19-28bbz作为tm4sf1car-t细胞的非靶向对照car-t细胞。
实施例三
本实施例为tm4sf1car-t细胞活性的测定。
tm4sf1car-t靶细胞的鉴定和构建:使用qpcr检测了calu-6,calu-3等肺癌细胞系上tm4sf1的表达,如图5所示,calu-3细胞系高表达tm4sf1基因,而calu-6几乎不表达tm4sf1基因。使用编码tm4sf1基因的慢病毒载体,利用嘌呤霉素筛选,构建得到高表达tm4sf1基因的calu-6细胞系。calu-6-tm4sf1细胞系的tm4sf1表达水平见图5。根据图5结果可知,calu-3,calu-6-tm4sf1细胞系为tm4sf1阳性表达,而calu-6细胞系tm4sf1阴性。
ifn-γ分泌实验:在96孔板中将l6-28z,l6-bbz,l6-28bbz,19-28bbz四种car-t细胞(效应细胞)与靶细胞以5:1效靶比混合。在37℃培养24小时,之后使用标准elisa方法检测ifn-γ的表达。结果如图6所示,当三种tm4sf1靶向的car-t细胞与calu-3或者calu-6-tm4sf1共培养时,car-t细胞会大量分泌ifn-γ,并且l6-28bbz的分泌量高于l6-28z和l6-28bbz,说明第三代car结构的l6-28bbz靶向tm4sf1的活性优于第二代car结构的l6-28z以及l6-28bbz。而tm4sf1的三种car分子与低表达tm4sf1的calu-6细胞共孵育是不能大量产生ifn-γ,说明本发明所构建car-t细胞具有良好的靶向特异性。而作为对照,非靶向tm4sf1的19-28bbzcar-t细胞并未产生大量ifn-γ,也说明了本发明所构建car-t细胞具有良好的靶向特异性。
实施例四
本实施例验证tm4sf1car-t细胞体杀伤tm4sf1靶细胞的能力。
用5-羧基荧光素琥珀酰亚胺基(cfse)将靶细胞染色,分别取实施例二中的car-t细胞与tm4sf1阳性的calu-3,calu-6-tm4sf1以如下的效靶比混合共培养:0.5:1,1:1,2:1,5:1。经过4小时共培养后,将细胞用pi试剂盒染色,同时设置对照组,对照组中加入靶细胞但同时未加入效应car-t细胞。使用流式细胞术对细胞杀伤进行检测。结果见图7a和图7b。tm4sf1car-t细胞能够有效杀伤calu-3以及calu-6-tm4sf1细胞,但是对照的19-28bbzcar-t细胞不能够有效杀伤这两种靶细胞。第三代car结构的l6-28bbz杀伤tm4sf1阳性肺癌细胞的活性优于第二代car结构的l6-28z以及l6-28bbz。
本实施例说明l6-28bbz,l6-28z,l6-bbz三种car分子构建的car-t细胞能够有效杀伤tm4sf1阳性的肺癌细胞。
实施例五
本实施例验证car-t细胞在小鼠模型中抑制tm4sf1阳性肿瘤生长的能力。
使用6周龄nod-scid免疫缺陷鼠,皮下注射5×106calu-3肺癌细胞系,允许肿瘤生长5-15天,用测径器测量肿瘤大小,以肿瘤最长长度乘最长长度垂直方向的长度得到一mm2为单位的肿瘤大小。当肿瘤大小达到20-30mm2时,通过静脉注射5×106的tm4sf1car-t细胞l6-28bbz或者19-28bbz,之后每3天测量肿瘤大小,当肿瘤直径达到1.5cm时,处死小鼠。
本实施例结果如图8a和图8b所示,注射l6-28bbzcar-t细胞6天之后肿瘤开始变小,到15-18天已经基本完全清楚肿瘤,并且所有小鼠均存活到第30天。然而对照非靶向tm4sf1的19-28bbzcar-t细胞不能够使肿瘤细胞减小,在30天时小鼠的存活率仅为20%。
本实施例说明,本发明的靶向tm4sf1的car-t细胞能够有效清除小鼠tm4sf1阳性肿瘤移植瘤模型中的肿瘤。
以上对本发明的具体实施例进行了详细描述,但其只作为范例,本发明并不限制于以上描述的具体实施例。对于本领域技术人员而言,任何对本发明进行的等同修改和替代也都在本发明的范畴之中。因此,在不脱离本发明的精神和范围下所作的均等变换和修改,都应涵盖在本发明的范围内。
sequencelisting
<110>上海科医联创生物科技有限公司
<120>一种tm4sf1特异性嵌合抗原受体及其应用
<160>22
<170>patentinversion3.5
<210>1
<211>120
<212>prt
<213>artificialsequence
<220>
<223>重链可变区(vh)氨基酸序列,鼠源蛋白
<400>1
glnileglnleuvalglnserglyprogluleulyslysproglyglu
151015
thrvallysilesercyslysalaserglytyrthrphethrasntyr
202530
glymetasntrpvallysglnalaproglylysglyleulystrpmet
354045
glytrpileasnthrtyrthrglyglnprothrtyralaaspaspphe
505560
lysglyargphealapheserleugluthrseralatyrthralatyr
65707580
leuglnileasnasnleulysasngluaspmetalathrtyrphecys
859095
alaargphesertyrglyasnserargtyralaasptyrtrpglygln
100105110
glythrthrleuthrvalserser
115120
<210>2
<211>107
<212>prt
<213>artificialsequence
<220>
<223>轻链可变区(vl)氨基酸序列,鼠源蛋白
<400>2
glnilevalleuserglnserproalaileleuseralaserprogly
151015
glulysvalthrleuthrcysargalaserserservalserphemet
202530
asntrptyrglnglnlysproglyserserprolysprotrpiletyr
354045
alathrserasnleualaserglyvalproglyargpheserglyser
505560
glyserglythrsertyrserleualaileserargvalglualaglu
65707580
aspalaalathrtyrtyrcysglnglntrpasnserasnproleuthr
859095
pheglyalaglythrlysleugluleulysarg
100105
<210>3
<211>45
<212>prt
<213>artificialsequence
<220>
<223>cd8hinge区域氨基酸序列,人源蛋白
<400>3
thrthrthrproalaproargproprothrproalaprothrileala
151015
serglnproleuserleuargproglualacysargproalaalagly
202530
glyalavalhisthrargglyleuaspphealacysasp
354045
<210>4
<211>24
<212>prt
<213>artificialsequence
<220>
<223>cd8跨膜区氨基酸序列,人源蛋白
<400>4
iletyriletrpalaproleualaglythrcysglyvalleuleuleu
151015
serleuvalilethrleutyrcys
20
<210>5
<211>28
<212>prt
<213>artificialsequence
<220>
<223>cd28跨膜区氨基酸序列,人源蛋白
<400>5
phetrpvalleuvalvalvalglyglyvalleualacystyrserleu
151015
leuvalthrvalalapheileilephetrpvalarg
2025
<210>6
<211>40
<212>prt
<213>artificialsequence
<220>
<223>cd28氨基酸序列,人源蛋白
<400>6
serlysargserargleuleuhisserasptyrmetasnmetthrpro
151015
argargproglyprothrarglyshistyrglnprotyralapropro
202530
argaspphealaalatyrargser
3540
<210>7
<211>42
<212>prt
<213>artificialsequence
<220>
<223>4-1bb氨基酸序列,人源蛋白
<400>7
lysargglyarglyslysleuleutyrilephelysglnprophemet
151015
argprovalglnthrthrglnglugluaspglycyssercysargphe
202530
proglugluglugluglyglycysgluleu
3540
<210>8
<211>112
<212>prt
<213>artificialsequence
<220>
<223>cd3ζ氨基酸序列,人源蛋白
<400>8
argvallyspheserargseralaaspalaproalatyrglnglngly
151015
glnasnglnleutyrasngluleuasnleuglyargarggluglutyr
202530
aspvalleuasplysargargglyargaspproglumetglyglylys
354045
proargarglysasnproglngluglyleutyrasngluleuglnlys
505560
asplysmetalaglualatyrsergluileglymetlysglygluarg
65707580
argargglylysglyhisaspglyleutyrglnglyleuserthrala
859095
thrlysaspthrtyraspalaleuhismetglnalaleuproproarg
100105110
<210>9
<211>488
<212>prt
<213>artificialsequence
<220>
<223>l6-28z氨基酸序列,car,人源蛋白
<400>9
metalaleuprovalthralaleuleuleuproleualaleuleuleu
151015
hisalaalaargproalaserglnilevalleuserglnserproala
202530
ileleuseralaserproglyglulysvalthrleuthrcysargala
354045
serserservalserphemetasntrptyrglnglnlysproglyser
505560
serprolysprotrpiletyralathrserasnleualaserglyval
65707580
proglyargpheserglyserglyserglythrsertyrserleuala
859095
ileserargvalglualagluaspalaalathrtyrtyrcysglngln
100105110
trpasnserasnproleuthrpheglyalaglythrlysleugluleu
115120125
lysargglyglyglyglyserglyglyglyglyserglyglyglygly
130135140
serglnileglnleuvalglnserglyprogluleulyslysprogly
145150155160
gluthrvallysilesercyslysalaserglytyrthrphethrasn
165170175
tyrglymetasntrpvallysglnalaproglylysglyleulystrp
180185190
metglytrpileasnthrtyrthrglyglnprothrtyralaaspasp
195200205
phelysglyargphealapheserleugluthrseralatyrthrala
210215220
tyrleuglnileasnasnleulysasngluaspmetalathrtyrphe
225230235240
cysalaargphesertyrglyasnserargtyralaasptyrtrpgly
245250255
glnglythrthrleuthrvalserserglyserthrthrthrproala
260265270
proargproprothrproalaprothrilealaserglnproleuser
275280285
leuargproglualacysargproalaalaglyglyalavalhisthr
290295300
argglyleuaspphealacysaspiletyriletrpalaproleuala
305310315320
glythrcysglyvalleuleuleuserleuvalilethrleutyrcys
325330335
serlysargserargleuleuhisserasptyrmetasnmetthrpro
340345350
argargproglyprothrarglyshistyrglnprotyralapropro
355360365
argaspphealaalatyrargserargvallyspheserargserala
370375380
aspalaproalatyrglnglnglyglnasnglnleutyrasngluleu
385390395400
asnleuglyargarggluglutyraspvalleuasplysargarggly
405410415
argaspproglumetglyglylysproargarglysasnproglnglu
420425430
glyleutyrasngluleuglnlysasplysmetalaglualatyrser
435440445
gluileglymetlysglygluargargargglylysglyhisaspgly
450455460
leutyrglnglyleuserthralathrlysaspthrtyraspalaleu
465470475480
hismetglnalaleuproproarg
485
<210>10
<211>490
<212>prt
<213>artificialsequence
<220>
<223>l6-bbz氨基酸序列,car,人源蛋白
<400>10
metalaleuprovalthralaleuleuleuproleualaleuleuleu
151015
hisalaalaargproalaserglnilevalleuserglnserproala
202530
ileleuseralaserproglyglulysvalthrleuthrcysargala
354045
serserservalserphemetasntrptyrglnglnlysproglyser
505560
serprolysprotrpiletyralathrserasnleualaserglyval
65707580
proglyargpheserglyserglyserglythrsertyrserleuala
859095
ileserargvalglualagluaspalaalathrtyrtyrcysglngln
100105110
trpasnserasnproleuthrpheglyalaglythrlysleugluleu
115120125
lysargglyglyglyglyserglyglyglyglyserglyglyglygly
130135140
serglnileglnleuvalglnserglyprogluleulyslysprogly
145150155160
gluthrvallysilesercyslysalaserglytyrthrphethrasn
165170175
tyrglymetasntrpvallysglnalaproglylysglyleulystrp
180185190
metglytrpileasnthrtyrthrglyglnprothrtyralaaspasp
195200205
phelysglyargphealapheserleugluthrseralatyrthrala
210215220
tyrleuglnileasnasnleulysasngluaspmetalathrtyrphe
225230235240
cysalaargphesertyrglyasnserargtyralaasptyrtrpgly
245250255
glnglythrthrleuthrvalserserglyserthrthrthrproala
260265270
proargproprothrproalaprothrilealaserglnproleuser
275280285
leuargproglualacysargproalaalaglyglyalavalhisthr
290295300
argglyleuaspphealacysaspiletyriletrpalaproleuala
305310315320
glythrcysglyvalleuleuleuserleuvalilethrleutyrcys
325330335
lysargglyarglyslysleuleutyrilephelysglnprophemet
340345350
argprovalglnthrthrglnglugluaspglycyssercysargphe
355360365
proglugluglugluglyglycysgluleuargvallyspheserarg
370375380
seralaaspalaproalatyrglnglnglyglnasnglnleutyrasn
385390395400
gluleuasnleuglyargarggluglutyraspvalleuasplysarg
405410415
argglyargaspproglumetglyglylysproargarglysasnpro
420425430
glngluglyleutyrasngluleuglnlysasplysmetalagluala
435440445
tyrsergluileglymetlysglygluargargargglylysglyhis
450455460
aspglyleutyrglnglyleuserthralathrlysaspthrtyrasp
465470475480
alaleuhismetglnalaleuproproarg
485490
<210>11
<211>534
<212>prt
<213>artificialsequence
<220>
<223>l6-28bbz氨基酸序列,car,人源蛋白
<400>11
metalaleuprovalthralaleuleuleuproleualaleuleuleu
151015
hisalaalaargproalaserglnilevalleuserglnserproala
202530
ileleuseralaserproglyglulysvalthrleuthrcysargala
354045
serserservalserphemetasntrptyrglnglnlysproglyser
505560
serprolysprotrpiletyralathrserasnleualaserglyval
65707580
proglyargpheserglyserglyserglythrsertyrserleuala
859095
ileserargvalglualagluaspalaalathrtyrtyrcysglngln
100105110
trpasnserasnproleuthrpheglyalaglythrlysleugluleu
115120125
lysargglyglyglyglyserglyglyglyglyserglyglyglygly
130135140
serglnileglnleuvalglnserglyprogluleulyslysprogly
145150155160
gluthrvallysilesercyslysalaserglytyrthrphethrasn
165170175
tyrglymetasntrpvallysglnalaproglylysglyleulystrp
180185190
metglytrpileasnthrtyrthrglyglnprothrtyralaaspasp
195200205
phelysglyargphealapheserleugluthrseralatyrthrala
210215220
tyrleuglnileasnasnleulysasngluaspmetalathrtyrphe
225230235240
cysalaargphesertyrglyasnserargtyralaasptyrtrpgly
245250255
glnglythrthrleuthrvalserserglyserthrthrthrproala
260265270
proargproprothrproalaprothrilealaserglnproleuser
275280285
leuargproglualacysargproalaalaglyglyalavalhisthr
290295300
argglyleuaspphealacysaspphetrpvalleuvalvalvalgly
305310315320
glyvalleualacystyrserleuleuvalthrvalalapheileile
325330335
phetrpvalargserlysargserargleuleuhisserasptyrmet
340345350
asnmetthrproargargproglyprothrarglyshistyrglnpro
355360365
tyralaproproargaspphealaalatyrargserlysargglyarg
370375380
lyslysleuleutyrilephelysglnprophemetargprovalgln
385390395400
thrthrglnglugluaspglycyssercysargpheproglugluglu
405410415
gluglyglycysgluleuargvallyspheserargseralaaspala
420425430
proalatyrglnglnglyglnasnglnleutyrasngluleuasnleu
435440445
glyargarggluglutyraspvalleuasplysargargglyargasp
450455460
proglumetglyglylysproargarglysasnproglngluglyleu
465470475480
tyrasngluleuglnlysasplysmetalaglualatyrsergluile
485490495
glymetlysglygluargargargglylysglyhisaspglyleutyr
500505510
glnglyleuserthralathrlysaspthrtyraspalaleuhismet
515520525
glnalaleuproproarg
530
<210>12
<211>1464
<212>dna
<213>artificialsequence
<220>
<223>l6-28z的编码核酸,人源核酸序列
<400>12
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccagg60
ccggctagccaaattgttctctcccagtctccagcaatcctgtctgcatctccaggggag120
aaggtcacattgacttgcagggccagctcaagtgtaagtttcatgaactggtaccagcag180
aagccaggatcctcccccaaaccctggatttatgccacatccaatttggcttctggagtc240
cctggtcgcttcagtggcagtgggtctgggacctcttactctctcgcaatcagcagagtg300
gaggctgaagatgctgccacttattactgccagcagtggaatagtaacccactcacgttc360
ggtgctgggaccaagctggagctgaaacgaggtggtggtggtagcggcggcggcggctct420
ggtggtggcggatcccagatccagttggtgcagtctggacctgagctgaagaagcctgga480
gagacagtcaagatctcctgcaaggcttctgggtataccttcacaaactatggaatgaac540
tgggtgaagcaggctccaggaaagggtttaaagtggatgggctggataaacacctacact600
ggacagccaacatatgctgatgacttcaagggacggtttgccttctctttggaaacctct660
gcctacactgcctatttgcagatcaacaacctcaaaaatgaggacatggctacatatttc720
tgtgcaagatttagctatggtaactcacgttacgctgactactggggccaaggcaccact780
ctcacagtctcctcaggatccaccacgacgccagcgccgcgaccaccaacaccggcgccc840
accatcgcgtcgcagcccctgtccctgcgcccagaggcgtgccggccagcggcggggggc900
gcagtgcacacgagggggctggacttcgcctgtgatatctacatctgggcgcccttggcc960
gggacttgtggggtccttctcctgtcactggttatcaccctttactgcagtaagaggagc1020
aggctcctgcacagtgactacatgaacatgactccccgccgccccgggcccacccgcaag1080
cattaccagccctatgccccaccacgcgacttcgcagcctatcgctccagagtgaagttc1140
agcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataacgagctc1200
aatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggaccctgag1260
atggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactgcagaaa1320
gataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggaggggcaag1380
gggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgacgccctt1440
cacatgcaggccctgccccctcgc1464
<210>13
<211>1470
<212>dna
<213>artificialsequence
<220>
<223>l6-bbz的编码核酸,人源核酸序列
<400>13
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccagg60
ccggctagccaaattgttctctcccagtctccagcaatcctgtctgcatctccaggggag120
aaggtcacattgacttgcagggccagctcaagtgtaagtttcatgaactggtaccagcag180
aagccaggatcctcccccaaaccctggatttatgccacatccaatttggcttctggagtc240
cctggtcgcttcagtggcagtgggtctgggacctcttactctctcgcaatcagcagagtg300
gaggctgaagatgctgccacttattactgccagcagtggaatagtaacccactcacgttc360
ggtgctgggaccaagctggagctgaaacgaggtggtggtggtagcggcggcggcggctct420
ggtggtggcggatcccagatccagttggtgcagtctggacctgagctgaagaagcctgga480
gagacagtcaagatctcctgcaaggcttctgggtataccttcacaaactatggaatgaac540
tgggtgaagcaggctccaggaaagggtttaaagtggatgggctggataaacacctacact600
ggacagccaacatatgctgatgacttcaagggacggtttgccttctctttggaaacctct660
gcctacactgcctatttgcagatcaacaacctcaaaaatgaggacatggctacatatttc720
tgtgcaagatttagctatggtaactcacgttacgctgactactggggccaaggcaccact780
ctcacagtctcctcaggatccaccacgacgccagcgccgcgaccaccaacaccggcgccc840
accatcgcgtcgcagcccctgtccctgcgcccagaggcgtgccggccagcggcggggggc900
gcagtgcacacgagggggctggacttcgcctgtgatatctacatctgggcgcccttggcc960
gggacttgtggggtccttctcctgtcactggttatcaccctttactgcaaacggggcaga1020
aagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagag1080
gaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactgagagtg1140
aagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctctataac1200
gagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggccgggac1260
cctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaatgaactg1320
cagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgccggagg1380
ggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacctacgac1440
gcccttcacatgcaggccctgccccctcgc1470
<210>14
<211>1602
<212>dna
<213>artificialsequence
<220>
<223>l6-28bbz的编码核酸,人源核酸序列
<400>14
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccagg60
ccggctagccaaattgttctctcccagtctccagcaatcctgtctgcatctccaggggag120
aaggtcacattgacttgcagggccagctcaagtgtaagtttcatgaactggtaccagcag180
aagccaggatcctcccccaaaccctggatttatgccacatccaatttggcttctggagtc240
cctggtcgcttcagtggcagtgggtctgggacctcttactctctcgcaatcagcagagtg300
gaggctgaagatgctgccacttattactgccagcagtggaatagtaacccactcacgttc360
ggtgctgggaccaagctggagctgaaacgaggtggtggtggtagcggcggcggcggctct420
ggtggtggcggatcccagatccagttggtgcagtctggacctgagctgaagaagcctgga480
gagacagtcaagatctcctgcaaggcttctgggtataccttcacaaactatggaatgaac540
tgggtgaagcaggctccaggaaagggtttaaagtggatgggctggataaacacctacact600
ggacagccaacatatgctgatgacttcaagggacggtttgccttctctttggaaacctct660
gcctacactgcctatttgcagatcaacaacctcaaaaatgaggacatggctacatatttc720
tgtgcaagatttagctatggtaactcacgttacgctgactactggggccaaggcaccact780
ctcacagtctcctcaggatccaccacgacgccagcgccgcgaccaccaacaccggcgccc840
accatcgcgtcgcagcccctgtccctgcgcccagaggcgtgccggccagcggcggggggc900
gcagtgcacacgagggggctggacttcgcctgtgatttttgggtgctggtggtggttggt960
ggagtcctggcttgctatagcttgctagtaacagtggcctttattattttctgggtgagg1020
agtaagaggagcaggctcctgcacagtgactacatgaacatgactccccgccgccccggg1080
cccacccgcaagcattaccagccctatgccccaccacgcgacttcgcagcctatcgctcc1140
aaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaa1200
actactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgt1260
gaactgagagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaac1320
cagctctataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagaga1380
cgtggccgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctg1440
tacaatgaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggc1500
gagcgccggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaag1560
gacacctacgacgcccttcacatgcaggccctgccccctcgc1602
<210>15
<211>532
<212>prt
<213>artificialsequence
<220>
<223>19-28bbz氨基酸序列,人源蛋白
<400>15
metalaleuprovalthralaleuleuleuproleualaleuleuleu
151015
hisalaalaargproalaserglnvalglnleuglnglnserglypro
202530
gluleuglulysproglyalaservallysilesercyslysalaser
354045
glytyrserphethrglytyrthrmetasntrpvallysglnserhis
505560
glylysserleuglutrpileglyleuilethrprotyrasnglyala
65707580
sersertyrasnglnlyspheargglylysalathrleuthrvalasp
859095
lysserserserthralatyrmetaspleuleuserleuthrserglu
100105110
aspseralavaltyrphecysalaargglyglytyraspglyarggly
115120125
pheasptyrtrpglyglnglythrthrvalthrvalserserglygly
130135140
glyglyserglyglyglyglyserserglyglyglyseraspileglu
145150155160
leuthrglnserproalailemetseralaserproglyglulysval
165170175
thrmetthrcysseralaserserservalsertyrmethistrptyr
180185190
glnglnlysserglythrserprolysargtrpiletyraspthrser
195200205
lysleualaserglyvalproglyargpheserglyserglysergly
210215220
asnsertyrserleuthrileserservalglualagluaspaspala
225230235240
thrtyrtyrcysglnglntrpserlyshisproleuthrtyrglyala
245250255
glythrlysleugluilelysglyserthrthrthrproalaproarg
260265270
proprothrproalaprothrilealaserglnproleuserleuarg
275280285
proglualacysargproalaalaglyglyalavalhisthrarggly
290295300
leuaspphealacysaspphetrpvalleuvalvalvalglyglyval
305310315320
leualacystyrserleuleuvalthrvalalapheileilephetrp
325330335
valargserlysargserargleuleuhisserasptyrmetasnmet
340345350
thrproargargproglyprothrarglyshistyrglnprotyrala
355360365
proproargaspphealaalatyrargserlysargglyarglyslys
370375380
leuleutyrilephelysglnprophemetargprovalglnthrthr
385390395400
glnglugluaspglycyssercysargpheprogluglugluglugly
405410415
glycysgluleuargvallyspheserargseralaaspalaproala
420425430
tyrlysglnglyglnasnglnleutyrasngluleuasnleuglyarg
435440445
arggluglutyraspvalleuasplysargargglyargaspproglu
450455460
metglyglylysproargarglysasnproglngluglyleutyrasn
465470475480
gluleuglnlysasplysmetalaglualatyrsergluileglymet
485490495
lysglygluargargargglylysglyhisaspglyleutyrglngly
500505510
leuserthralathrlysaspthrtyraspalaleuhismetglnala
515520525
leuproproarg
530
<210>16
<211>1596
<212>dna
<213>artificialsequence
<220>
<223>19-28bbz的编码核酸,人源核酸序列
<400>16
atggccttaccagtgaccgccttgctcctgccgctggccttgctgctccacgccgccagg60
ccggctagccaggtacaactgcagcagtctgggcctgagctggagaagcctggcgcttca120
gtgaagatatcctgcaaggcttctggttactcattcactggctacaccatgaactgggtg180
aagcagagccatggaaagagccttgagtggattggacttattactccttacaatggtgct240
tctagctacaaccagaagttcaggggcaaggccacattaactgtagacaagtcatccagc300
acagcctacatggacctcctcagtctgacatctgaagactctgcagtctatttctgtgca360
agggggggttacgacgggaggggttttgactactggggccaagggaccacggtcaccgtc420
tcctcaggtggaggcggttcaggcggcggtggctctagcggtggcggatcggacatcgag480
ctcactcagtctccagcaatcatgtctgcatctccaggggagaaggtcaccatgacctgc540
agtgccagctcaagtgtaagttacatgcactggtaccagcagaagtcaggcacctccccc600
aaaagatggatttatgacacatccaaactggcttctggagtcccaggtcgcttcagtggc660
agtgggtctggaaactcttactctctcacaatcagcagcgtggaggctgaagatgatgca720
acttattactgccagcagtggagtaagcaccctctcacgtacggtgctgggacaaagttg780
gaaatcaaaggatccaccacgacgccagcgccgcgaccaccaacaccggcgcccaccatc840
gcgtcgcagcccctgtccctgcgcccagaggcgtgccggccagcggcggggggcgcagtg900
cacacgagggggctggacttcgcctgtgatttttgggtgctggtggtggttggtggagtc960
ctggcttgctatagcttgctagtaacagtggcctttattattttctgggtgaggagtaag1020
aggagcaggctcctgcacagtgactacatgaacatgactccccgccgccccgggcccacc1080
cgcaagcattaccagccctatgccccaccacgcgacttcgcagcctatcgctccaaacgg1140
ggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactact1200
caagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactg1260
agagtgaagttcagcaggagcgcagacgcccccgcgtacaagcagggccagaaccagctc1320
tataacgagctcaatctaggacgaagagaggagtacgatgttttggacaagagacgtggc1380
cgggaccctgagatggggggaaagccgagaaggaagaaccctcaggaaggcctgtacaat1440
gaactgcagaaagataagatggcggaggcctacagtgagattgggatgaaaggcgagcgc1500
cggaggggcaaggggcacgatggcctttaccagggtctcagtacagccaccaaggacacc1560
tacgacgcccttcacatgcaggccctgccccctcgc1596
<210>17
<211>25
<212>dna
<213>artificialsequence
<220>
<223>引物bbf
<400>17
aaacggggcagaaagaaactcctgt25
<210>18
<211>25
<212>dna
<213>artificialsequence
<220>
<223>引物cd3zr
<400>18
gcgagggggcagggcctgcatgtga25
<210>19
<211>25
<212>dna
<213>artificialsequence
<220>
<223>引物carf
<400>19
atggccttaccagtgaccgccttgc25
<210>20
<211>25
<212>dna
<213>artificialsequence
<220>
<223>引物cd8tmr
<400>20
gcagtaaagggtgataaccagtgac25
<210>21
<211>34
<212>dna
<213>artificialsequence
<220>
<223>引物carf2
<400>21
ctagctagcatggccttaccagtgaccgccttgc34
<210>22
<211>33
<212>dna
<213>artificialsequence
<220>
<223>引物cd3zr2
<400>22
cgggatccgcgagggggcagggcctgcatgtga33
- 还没有人留言评论。精彩留言会获得点赞!