基于匹配模型二次识别的语音识别方法及系统与流程
本发明属于人机语音交互技术领域,特别是一种识别准确度高、用户体验好的基于匹配模型二次识别的语音识别方法及实现该方法的系统。
背景技术:
语音识别是理想的人机交互中介工具,是推动机器向更智能化发展的重要技术。能听懂人讲话,可以进行思考和理解人的意图,并最终对人作出语音或者行动上的响应的智能化机器一直是人工智能的终极目标之一。
在大数据的背景下,机器学习逐渐渗透到智能家居、车载语音、身份识别等领域。基于大数据的深度学习研究方法对语音识别系统性能的提升有重要意义。早在几年前就有国外学者提出了关于将深度学习研究方法运用在语音识别上(geoffreyhinton,lideng,dongyu.deepneuralnetworksforacousticmodelinginspeechrecognition)。
但是通过调整模型结构以及参数来提升语音识别系统准确率的方法,在实际用户语音噪声背景不匹配时会导致语音识别准确率急剧下降,严重影响人机交互体验。
技术实现要素:
本发明的目的在于提供一种基于匹配模型二次识别的语音识别方法,识别准确度高、用户体验好。
本发明的另一目的在于提供一种基于匹配模型二次识别的语音识别系统,识别准确度高、用户体验好。
实现本发明目的的技术解决方案为:
一种基于匹配模型二次识别的语音识别方法,包括如下步骤:
(10)语音处理:对用户输入的语音进行预处理及特征提取;
(20)语音识别:识别解析用户的语音信息,提取并保存用户性别和环境噪声信息;
(30)用户评价:接收用户对第一次识别结果的反馈信息,如第一次识别结果不符合期望,则继续进行二次识别,发出二次识别请求;
(40)匹配模型识别:在二次识别请求下,根据用户性别和环境噪声情况,匹配一个最优的语音识别模型,重新识别并输出解析结果。。
实现本发明另一目的的技术解决方案为:
一种基于匹配模型二次识别的语音识别系统,包括:
语音处理单元(1),用于对用户输入的语音进行预处理及特征提取;
语音识别单元(2),用于识别解析用户的语音信息,提取并保存用户性别和环境噪声信息;
用户评价(3),用于接收用户对第一次识别结果的反馈信息;
匹配模型识别单元(4),用于根据用户性别和环境噪声情况,匹配一个最优的语音识别模型,重新识别并输出解析结果。
本发明与现有技术相比,其显著优点为:
1、识别准确度高:本发明的方法基于机器学习,利用针对不同用户的输入语音情况在对应的训练集上建立与之匹配的声学模型,很好的保证了识别系统的准确率;
2、用户体验好:本发明的方法重复利用了用户输入语音,避免了一旦识别出错只能二次输入的情况,极大的提升了用户体验。
下面结合附图和具体实施方式对本发明作进一步的详细描述。
附图说明
图1为本发明基于匹配模型二次识别的语音识别方法的主流程图。
图2是图1中识别解析用户的语音信息步骤的原理框图。
图3是图1中用户性别提取步骤的原理框图。
图4是图1中环境噪声提取步骤的流程图。
具体实施方式
如图1所示,本发明基于匹配模型二次识别的语音识别方法,包括如下步骤:
(10)语音处理:对用户输入的语音进行预处理及特征提取;
现有技术中,常见的语音识别模型建模过程包括以下步骤:
(1)获取足量已经标注好的训练数据,提取每个训练样本的梅尔域倒谱系数(mfcc)作为声学特征;整理训练数据的标注信息提取文本特征矢量
(2)将训练样本的声学特征向量输入到由受限玻尔兹曼机器(rbm)堆叠构成的深度神经网络(dnn)中,采用gmm-hmm基线系统经强制对齐得到神经网络的输出层。将训练样本的网络输出结果与实际标注信息进行对照得到输出层的误差信号,利用误差反向传播(bp)算法来调整网络参数。反复训练,调整参数得到最终的声学模型。
(3)根据样本文本特征矢量,分析得到统计意义上的语言环境中的词序列概率。用三音素的n-gram分析方法训练语言模型,得到样本空间的语言模型。
(4)运用维特比解码算法,把由训练样本空间抽取得到的发音词典,语音模型以及声学模型连成一个网络,通过搜索网络中的最优路径完成待解析的用户输入语音的解码。
(20)语音识别:识别解析用户的语音信息,提取并保存用户性别和环境噪声信息;
如图2所示,所述(20)语音识别步骤中,识别解析用户的语音信息步骤包括:
(211)提取用户输入语音的梅尔域倒谱系数(mfcc)作为声学特征;
(212)将输入语音的特征向量输入到已经在训练样本集上训练完成的声学模型中,解码得到输入语音的音素成分。
(213)用户输入语音的音素组成信息被输入到解码器中,解码器综合训练集的发音词典以及语言模型,给用户输入语音一个最优词序列作为最终的识别解析结果。
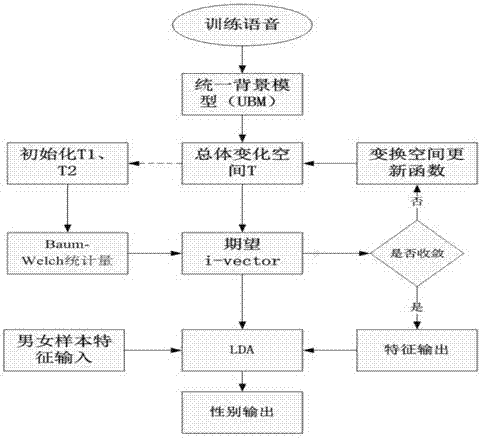
如图3所示,所述(20)语音识别步骤中,用户性别提取步骤包括:
(221)模型训练:采用最大似然准则在足量的数据样本上训练高斯混合模型;
(222)语音特征提取:提取用户输入语音的语音特征,其总体变量空间在ubm上的超级矢量m表示如下,
m=m+tx+e
其中,m是特定输入语句的超级矢量,m是样本数据的均值超级矢量,x是符合正态分布的低维随机矢量,t是描述总体变化的矩阵,e是由噪声或其他非相关因素产生的残差,gmm为高斯混合模型,ubm为统一背景模型;
在已知ubm-gmm模型的参数为ω时,i-vector可以由上式得到,从而解决如下问题:
(223)根据样本数据的baum-welch统计量γk(i)和γy,k(i),公式如下:
可以得到i-vector的提取公式:
(224)特征向量估计:根据i-vector的提取公式,可以利用em算法来估计实际特征向量。
(225)用户性别分析:将提取得到的用户i-vector特征用线性投影分析(lda)方法投影在由500名男性500名女性构成的散布平面上,由此分析出用户性别。
所述(224)特征向量估计步骤包括:
(2241)初始化:在训练样本中随机地选取t,设定t中每个成分的初始值,对于每个训练的语音片段计算其相应的baum-welch统计量。
(2242)设定e值:对于每个训练的语音片段用充足的数据和当前对t的估计,计算ω(i)的期望值,计算的方法如下:
e[ω(i)]=i-1(i)ttr0-1γy(i)
e[ω(i)ωt(i)]=e[ω(i)]e[ωt(i)]+i-1(i)
(2243)设定m值:采用一个方程更新总体变化矩阵t:
(2244)重复或者中止:反复步骤(2242)、(2243),直到迭代次数的固定值或者直到目标函数收敛。
如图4所示,所述(20)语音识别步骤中,环境噪声提取步骤包括:
(231)功率谱密度平滑:计算用户输入语音的功率谱密度,并进行递归平滑,所用公式如下:
y(n,k)=x(n,k)+d(n,k);
|y(n,k)|2=|x(n,k)|2+|d(n,k)|2;
p(n,k)=αp(n-1,k)+(1-α)|y(n,k)|2;
上式中,x(n,k)、d(n,k)、y(n,k)分别表示用户输入语音y(t)中纯净语音x(t)和不相关加性噪声d(t)的短时傅里叶变换形式;|y(n,k)|2、|x(n,k)|2、|d(n,k)|2分别表示输入语音、纯净语音和噪声的功率谱。p(n,k)是对输入语音功率谱密度进过平滑得到的结果,α是平滑因子。
(232)噪声功率谱获取:搜索输入语音的功率谱密度在一定时间窗内的最小值,乘以一个偏差修正量即可得到噪声功率谱,公式如下:
smin(n,k)=min{p(n,k)|n-d+1≤n≤n};
上式中,d是最小值搜索窗口长度,β是偏差补偿因子,
(233)噪声情况判断:利用公式
(30)用户评价:
接收用户对第一次识别结果的反馈信息,如第一次识别结果不符合期望,则继续进行二次识别,发出二次识别请求;
(40)匹配模型识别:在二次识别请求下,根据用户性别和环境噪声情况,匹配一个最优的语音识别模型,重新识别并输出解析结果。
所述(40)匹配模型识别步骤具体为:
接收用户的二次识别请求信号,根据第一次识别得到的性别和噪声情况信息,以用户特征信号作为输入,匹配到预先准备的语音识别模型中,重新按照第一次识别的过程进行二次识别和解析,返回文本结果给用户。
本发明基于匹配模型二次识别的语音识别系统,包括:
语音处理单元(1),用于对用户输入的语音进行预处理及特征提取;
语音识别单元(2),用于识别解析用户的语音信息,提取并保存用户性别和环境噪声信息;
用户评价(3),用于接收用户对第一次识别结果的反馈信息,如第一次识别结果不符合期望,则继续进行二次识别,发出二次识别请求;
匹配模型识别单元(4),用于根据用户性别和环境噪声情况,匹配一个最优的语音识别模型,重新识别并输出解析结果。
根据用户性别和环境噪声情况,匹配一个最优的语音识别模型:匹配模型由4种根据性别(男,女)以及噪声情况(信噪比好,信噪比差)分别独立训练而成的语音识别模型组成,其建模方法跟通用识别模型一致,建模数据不再基于男女混合的有噪无噪均匀分布的训练集,而是分别基于高信噪比的男性语音、高信噪比的女性语音、低信噪比的男性语音、低信噪比的女性语音。以用户原始语音特征作输入,重新识别并输出解析结果。
- 还没有人留言评论。精彩留言会获得点赞!