一种仿人机器人阅读系统及方法
本发明涉及智能机器人,更具体地,涉及一种仿人机器人阅读系统及方法。
背景技术:
1、在现代社会中,智能机器人的应用范围越来越广泛,一些目前已经应用的仿人机器人包括:可以根据用户输入的语言或其他信息来进行回答、支持、建议等互动的社交机器人和用于儿童教育、教育资源匮乏地区以及远程教育等领域的教育机器人,这些机器人广泛应用在商业、教育、娱乐等领域。但这些机器人往往只能简单地从文本中提取信息并进行语音播报,无法模拟人类阅读过程中的各种细节和语音表达方式等。
2、儿童阅读对于儿童的身心健康和智力发展至关重要。现代社会信息量庞大,阅读已成为获取知识和信息的主要途径,通过阅读可以帮助儿童丰富视野,开拓思路,增强语言表达和沟通能力,提高自我认知和综合素质。同时,儿童期是人们认知发展最为迅速的时期,启蒙教育尤为重要。因此,对于儿童阅读的研究和推广具有非常重要的意义,它不仅有助于儿童的认知和智力发展,还可以帮助建立健康、积极向上的价值观。为此,需要从儿童阅读的角度,倾听儿童的声音,了解儿童的心理需求,为他们提供更切实有效的阅读资源与支持,促进儿童的全面发展。
3、盲人阅读是一种通过触摸读写盲文的方法来阅读,是盲人获取知识和信息的主要方式。对于盲人而言,盲文阅读的学习成本高,由于盲文时一种特殊的读写方法,学习起来需要耗费大量的时间和精力。同时盲文阅读需要专门的工具,现在虽然存在盲文点字机或盲人电脑等专门的工具,而这些设备需要费用较高且使用门槛较高。而且盲文是通过手指触摸并辨认不同的凸点来阅读的,所以阅读速度相对较慢,需要更多的时间和耐心,这也导致阅读速度较慢。对于盲人阅读技术和教育的研究和提升,对于促进盲人群体的自我发展和社会融入具有十分重要的意义。因此,有必要开发一种仿人机器人阅读系统,使得儿童和盲人的阅读更加智能化和人性化。
4、现有技术公开了一种基于人形机器人的文字识别方法及人形机器人,该方法人形机器人获取文字图像,进而采用开源计算机视觉库方式,对该获取的文字图像进行图像处理,得到黑白效果的图像,进而对该得到的黑白效果的图像进行文字识别,识别出该图像中的文字信息。该方法的缺陷是,没有将文字信息转化为语音信息,对盲人群体的阅读方式没有很好的改变。
5、为此,结合以上需求和现有技术缺陷,本技术提出了一种仿人机器人阅读系统及方法。
技术实现思路
1、本发明提供了一种仿人机器人阅读系统及方法,能够获取文字信息并转化为语音信息,且能够使仿人机器人的唇部配合语音信息活动。
2、本发明的首要目的是为解决上述技术问题,本发明的技术方案如下:
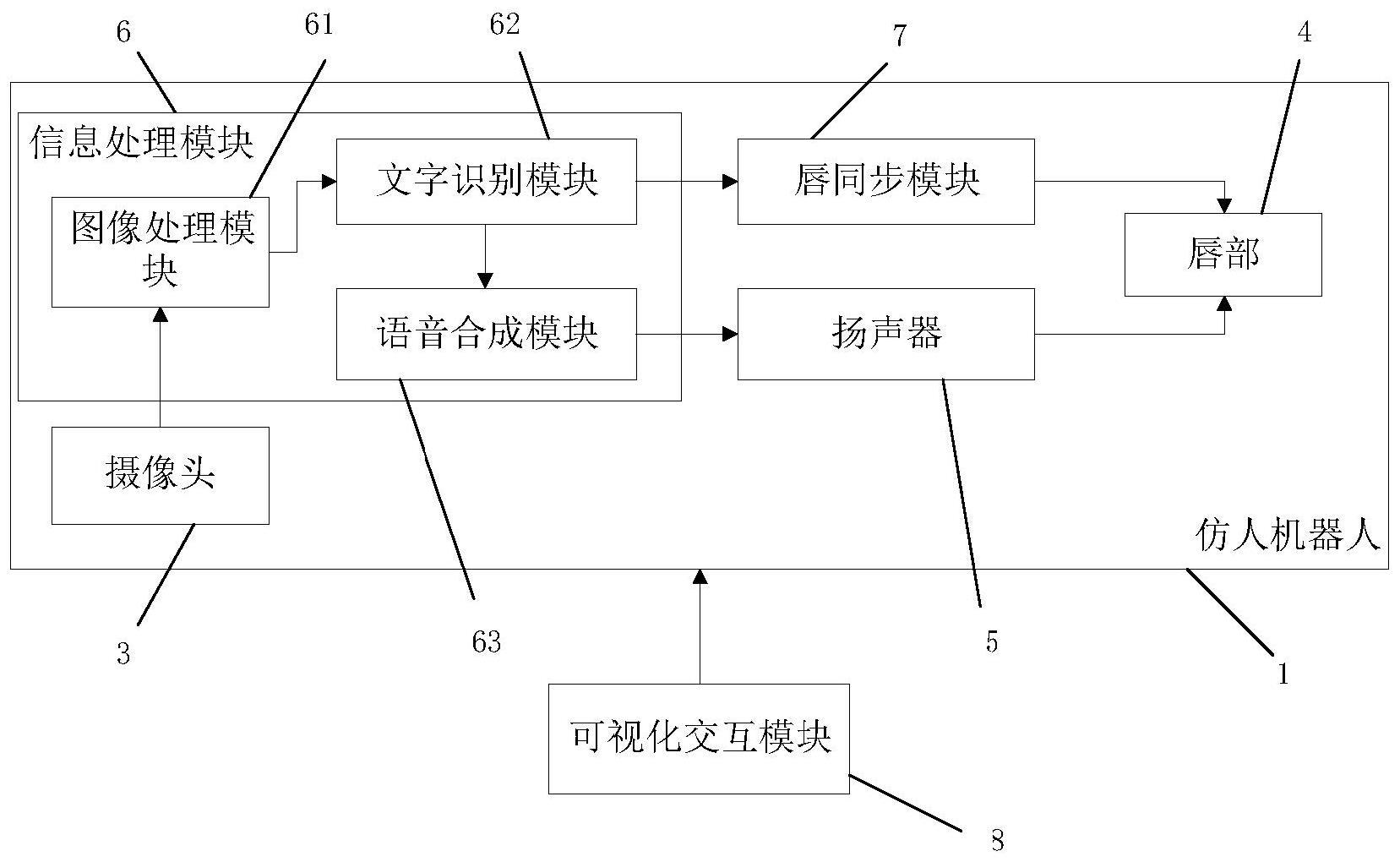
3、本发明第一方面提供了一种仿人机器人阅读系统,包括有设置在仿人机器人眼部的摄像头、设置在仿人机器人的唇部的扬声器、信息处理模块和唇同步模块。
4、所述信息处理模块接收摄像头获取的原始图像,对所述原始图像进行处理,输出文字信息至唇同步模块,输出语音信息至扬声器,所述扬声器根据语音信息输出语音。
5、所述唇同步模块将获取的文字信息处理为唇部动作信息,并根据扬声器输出语音的进度控制所述仿人机器人的唇部执行对应动作。
6、进一步的,还包括有可视化交互模块,所述可视化交互模块接收控制者输入的指令后,输出控制信息至所述摄像头,并控制摄像头获取视野范围内的图像作为原始图像并传输至所述信息处理模块;所述可视化交互模块通过预设的音色设置控制所述扬声器,所述扬声器根据语音信息输出预设音色的语音。
7、进一步的,所述信息处理模块包括有:图像处理模块、文字识别模块和语音合成模块;所述图像处理模块接收摄像头获取的原始图像后,对原始图像进行处理得到处理后的图像信息,并输入至文字识别模块,所述文字识别模块从处理后的图像信息中获取文字信息,并分别输入至语音合成模块和唇同步模块,所述语音合成模块将文字信息转换为语音信息,并输入至扬声器,所述唇同步模块将文字信息转换为唇部动作信息,并通过唇部动作信息与扬声器输出语音的进度控制所述仿人机器人的唇部执行对应动作。
8、进一步的,在所述仿人机器人的唇部内设置有控制装置,所述控制装置包括有:第一活动部、第二活动部、第三活动部和舵机;所述第一活动部和第二活动部分别用于控制仿人机器人的唇部的两个嘴角,所述第三活动部用于控制仿人机器人的下巴和唇部的下嘴唇;所述第一活动部和第二活动部通过舵机控制水平方向角度的张合,所述第三活动部舵机控制垂直方向角度的张合。
9、其中,所述唇同步模块根据唇部动作信息和扬声器输出语音的进度对舵机进行角度控制并带动第一活动部、第二活动部和第三活动部运动,实现仿人机器人的唇部开合。
10、根据上述技术特征,所述仿人机器人优化了传统机器人阅读系统往往只能简单地从文本中提取信息并进行语音播报,无法模拟人类阅读过程中的各种细节和语音表达方式等问题。
11、本发明第二方面提供了一种仿人机器人阅读方法,该方法用于所述的一种仿人机器人阅读系统,包括以下步骤:
12、s1、采用设置在仿人机器人眼部的摄像头获取原始图像。
13、s2、利用信息处理模块对原始图像进行处理,得到文字信息和语音信息。
14、s3、采用唇同步模块对文字信息进行处理,得到唇部动作信息。
15、s4、利用扬声器根据语音信息输出语音,并根据输出语音的进度和唇部动作信息控制仿人机器人的唇部执行对应动作。
16、进一步的,步骤s2中,所述信息处理模块包括有图像处理模块、文字识别模块和语音合成模块,所述对原始图像进行处理,得到文字信息和语音信息的具体过程为:
17、所述图像处理模块读取摄像头获取的原始图像,采用文档边缘检测算法获取原始图像中文本所在位置的边缘信息网络,输出文本图像的角点坐标;对原始图像进行透视变换和降噪,将原始图像变换为正视的图像信息,采用自适应维纳滤波器去除文本图像的噪音,得到处理后的图像信息。
18、文字识别模块接收处理后的图像信息,采用文字检测技术对处理后的图像信息进行检测,对文字区域进行裁剪得到文字区域信息;采用文字识别技术从文字区域信息中提取文字信息,并将文字信息转换为标签序列和二进制编码形式。
19、语音合成模块接收文字识别模块提取的二进制形式的文字信息,采用自然语言处理技术将文字信息以句为单位拆分为文本;采用语音合成技术将文本逐句处理为单句语音信息,并根据原始文本信息将单句语音信息整合为完整文本的语音信息。
20、进一步的,所述采用文档边缘检测算法获取图像信息中文本所在位置的边缘信息网络的具体过程为:
21、采用res2net101网络提取原始图像的特征,并作为后续网络的输入,采用注意力值为权重双分支求和的双分支全连接层,所述双分支全连接层包括第一分支和第二分支。
22、将第一分支的输出和第二分支的输出利用注意力机制求和后分别输入至第一线性层和第二线性层进行变换后,经过激活函数后输出对应通道的注意力系数,将第一分支的输出和第二分支的输出按照注意力系数进行逐通道加权求和作为最后的输出,输出结果为文本图像的角点坐标。
23、根据文本图像的角点坐标,对原始图像进行透视变换,将原始图像转换为正视的图像,采用自适应维纳滤波器去除文本图像的噪音,得到处理后的图像信息。
24、所述采用文字检测技术对处理后的图像信息进行检测的具体过程为:
25、将处理后的图像信息作为输入图像输入至特征提取网络,得到四个特征图,其中四个特征图分别为输入图像大小的1/4、1/8、1/16和1/32,分别对四个特征图进行上采样处理,经过上采样处理的特征图大小为原特征图大小的1/4,对四个经过上采样处理的特征图进行多特征融合得到特征图f,对特征图f进行处理得到概率图p和阈值图t,利用可微分二值化模块通过概率图p和阈值图t得到文字区域,根据文字区域对处理后的图像信息进行裁剪,输出文字区域信息。
26、所述采用文字识别技术从文字区域信息中提取文字信息的具体过程为:
27、将文字区域信息输入至文字识别网络的卷积层,提取文字特征图并输入至循环层,对特征序列进行预测并输出预测标签的分布,最后采用转录层将预测标签分布转换为标签序列,所述标签序列即为识别得到的文字。
28、将识别得到的文字转换为二进制编码形式,得到文字信息。
29、进一步的,语音合成模块输出语音信息的具体过程为:
30、读取文字信息,利用自然语言处理技术,根据中文阅读的规则将文字信息拆分为以句为单位的文本,采用语音合成网络对文本进行处理,首先读取二进制编码形式的文本,将其转换文字格式后作为输入音素序列,经过第一快速傅里叶变换模块的处理后,通过长度调节器来预测音素对应的频谱长度,经过时间预测网络预输出音频持续时间,然后经过第二快速傅里叶变换模块后输出频谱,最后经过全连接层输出音频,将单句文字信息合成为语音信息;其中,音频和语音信息均可通过预设改变音色。
31、进一步的,步骤s3中,所述采用唇同步模块对文字信息进行处理,得到唇部动作信息的具体过程为:
32、s31、读取文字信息,采用自然语言处理技术将文字信息按照中文字词规则拆分为字或词的组合,输出字词的声母、韵母和音调信息。
33、s32、采用唇文映射技术将字词的声母、韵母和音调信息进行处理,输出对应字词的唇部宽高比和动作持续时间。
34、s33、将唇部宽高比转换为控制装置中舵机控制的宽高比,将动作持续时间转换为控制装置中舵机的控制时间信息,根据舵机的初始角度、结束角度、宽高比及时间信息,得到单位时间内舵机的角度增量,通过定时模式将舵机的角度增量转换为单位时间内的脉冲宽度增量。
35、s34、重复步骤s33直到全部文字信息均转换为对应的单位时间内的脉冲宽度增量,将所有单位时间内的脉冲宽度增量依次拼接得到唇部动作信息。
36、步骤s4中,所述根据输出语音的进度和唇部动作信息控制仿人机器人的唇部执行对应动作的具体过程为。
37、将语音信息输入至扬声器的同时,将唇部动作信息输入至舵机,扬声器根据语音信息输出语音时,舵机根据唇部动作信息控制第一活动部、第二活动部和第三活动部带动仿人机器人的唇部张合。
38、进一步的,所述唇文映射技术具体为:
39、采用dlib模型提取唇部的特征点,选取设定特征点之间的距离作为唇部的宽度和高度,得到唇部的宽高比。
40、收集标准朗读视频,提取文字和时间戳,并提取文字的拼音和音调信息,处理后得到唇文数据集,将所述唇文数据集划分为训练集和测试集,将所述训练集输入至预设的神经网路模型中,完成神经网络模型的初步训练。
41、将所述测试集的文字信息输入至初步训练的神经网络模型,输出文字信息中包含的字词的起始唇形宽高比、结束唇形宽高比和发音持续时间。
42、将所述起始唇形宽高比、结束唇形宽高比和发音持续时间拟合为唇形变化曲线,与该测试集中实际的唇形变化曲线进行比对,计算偏差值,若偏差值大于预设值,则返回重新训练神经网络模型;否则,完成神经网络模型的训练。
43、将步骤s2得到的文字信息输入至训练好的神经网络模型,输出得到起始唇形宽高比、结束唇形宽高比和发音持续时间,以及唇形变化曲线,根据唇形变化曲线得到字词的动作持续时间。
44、根据上述技术特征,达成了利用扬声器和机器人唇部进行协调输出,达到口型和语音的匹配,提升了仿人机器人的仿人程度,使得机器人更加人性化,也使用户更易接受。
45、与现有技术相比,本发明技术方案的有益效果是:
46、本发明提供了一种仿人机器人阅读系统及方法,利用信息处理模块能够将获取的文字信息转化为语音信息,通过唇同步模块能够使仿人机器人的唇部配合语音信息活动,达到口型和语音的匹配,提升了仿人机器人的仿人程度,使得机器人更加人性化,也使用户更易接受。
- 还没有人留言评论。精彩留言会获得点赞!