用于头盔的主动噪声和认知控制的利记博彩app
背景技术:
1.技术领域。
本公开涉及一种用于头盔中的主动噪声和认知控制的系统和方法(通常称为“系统”)。
2.相关技术。
摩托车手在骑车时的听力是现代环境中的关键安全因素。令人遗憾的是,摩托车手的听力可能受到例如发动机噪声、风噪声和由头盔设计引起的噪声等噪声的阻碍。例如摩托车手经历的噪声水平等高噪声水平可能增加疲劳、影响反应时间并阻碍注意力,从而有力地降低摩托车手及其周围人的安全。此外,长时间的高强度噪声可能对摩托车手的听力具有长期的影响。在公路速度下,即使佩戴传统的头盔,噪声水平也可能容易超过100db(a)。对于日常摩托车手以及职业摩托车手(例如警察),还有对于飞行员、军事人士和佩戴头盔的摩托车运动爱好者来说,这是特别麻烦的。
为了对抗噪声,一些摩托车头盔在耳朵区域周围使用消音材料。其他摩托车手可能会选择使用耳塞来减少噪声,并防止噪声引起的听力损失。降低噪声的另一种方法是内置主动噪声消除系统。在所有的情况下,噪声降低在一些情况下可能太强,例如,可能会在一定程度上降低或消除所需声音,例如摩托车手自己的摩托车或其他车辆、警笛、喇叭和其周围的其他警告信号。或者,在其他情况下,例如当摩托车手自己的摩托车声音或任何其他噪声太大时,噪声降低对于不期望的声音可能太弱。当摩托车手听音乐时,情况可能变得甚至更加复杂,这种音乐在一些情况下是所期望的声音,但是当更重要的所需声音(例如由其他车辆、警笛、喇叭和摩托车手周围其他警告信号产生的声音)发生时可能不是所期望的。
技术实现要素:
一种主动降噪系统包括:具有刚性壳体的头盔,所述壳体配置为在空间上划分壳体内部与壳体周围环境;以及至少一个主动噪声控制通道。所述至少一个主动噪声控制通道被配置为接收表示在壳体周围环境中发生的至少一个期望声音模式的至少一个期望声音信号,并且基于所述至少一个期望声音信号,产生反声,所述反声被配置为通过叠加与在壳体内部发生的内部声音相互作用。所述内部声音包括第一内部声音分量和第二内部声音分量,所述第一内部声音分量不对应于所述至少一个期望声音模式,而所述第二内部声音分量对应于所述至少一个期望声音模式。所述反声还被配置为衰减所述第一内部声音分量,并且使所述第二内部声音分量放大、不衰减或衰减到比所述第一内部声音分量小的程度。
一种用于具有刚性壳体的头盔的主动降噪方法,所述刚性壳体在空间上划分壳体内部与壳体周围环境,所述主动降噪方法包括:接收表示在壳体周围环境中发生的至少一个期望声音模式的至少一个期望声音信号,以及基于所述至少一个期望声音信号,产生反声,所述反声被配置为通过叠加与在壳体内部发生的内部声音相互作用。所述内部声音包括第一内部声音分量和第二内部声音分量,所述第一内部声音分量不对应于所述至少一个期望声音模式,而所述第二内部声音分量对应于所述至少一个期望声音模式。所述反声还被配置为衰减所述第一内部声音分量,并且使所述第二内部声音分量放大、不衰减或衰减到比所述第一内部声音分量小的程度。
一种计算机程序被配置为结合适当的硬件执行用于具有刚性壳体的头盔的主动降噪方法,所述刚性壳体在空间上划分壳体内部与壳体周围环境,所述主动降噪方法包括:接收表示在壳体周围环境中发生的至少一个期望声音模式的至少一个期望声音信号,以及基于所述至少一个期望声音信号,产生反声,所述反声被配置为通过叠加与在壳体内部发生的内部声音相互作用。所述内部声音包括第一内部声音分量和第二内部声音分量,所述第一内部声音分量不对应于所述至少一个期望声音模式,而所述第二内部声音分量对应于所述至少一个期望声音模式。所述反声还被配置为衰减所述第一内部声音分量,并且使所述第二内部声音分量放大、不衰减或衰减到比所述第一内部声音分量小的程度。
通过审查以下附图和详细描述,其他系统、方法、特征和优点对本领域技术人员来说将显而易见或将变得显而易见。所有这些额外的系统、方法、特征和优点旨在包括在本说明书内,在本发明的范围内,并且由所附权利要求书保护。
附图说明
参考以下附图和描述可更好地理解所述系统。附图中的组件不一定按比例绘制,而是将重点放在说明本发明的原理上。此外,在附图中,相同的参考符号表示所有的不同视图中的对应部件。
图1是具有主动噪声控制系统的摩托车头盔的透视图。
图2是可应用于图1中所示的头盔中的示例性主动噪声控制器的信号流程图。
图3是图2中所示的主动噪声控制器的一个通道的信号流程图。
图4是可应用于图3中所示的主动噪声控制处理器的第一示例性主动噪声控制处理器的信号流程图。
图5是可应用于图3中所示的主动噪声控制处理器的第二示例性主动噪声控制处理器的信号流程图。
图6是用于如图1中所示的头盔中的示例性麦克风扬声器组合的透视图;
图7是用于如图1中所示的头盔中的面颊部件的透视图,所述面颊部件包括图6中所示的麦克风扬声器组合;
图8是示出可应用于图2中所示的主动噪声控制系统中的示例性主动噪声控制方法的工序流程图。
图9是示出用于头盔的示例性认知方法的工序流程图。
图10是示出用于头盔的自动噪声控制方法的工序流程图。
具体实施方式
在下面的描述中,所示的所有示例都涉及骑摩托车的摩托车手,但适用于佩戴头盔并驾驶任何类型的陆上、水上或空中交通工具的所有其他驾驶员。噪声在本文中称为任何不期望的声音。影响摩托车手的噪声可能会有很多来源,例如发动机噪声、道路噪声、风噪声和车辆中的其他噪声。随着车辆速度的增加,通常最突出的噪声源是风噪声。摩托车手所经历的所有类型噪声的共同之处在于它们引起摩托车手的耳朵的振动。在一些情况下,头盔可能通过将振动从环境直接传输到摩托车手的耳朵来增加感知到的噪声振幅。例如,随着摩托车手行进速度加快,影响他或她的头盔壳体的风又将产生更多的振动,摩托车手将这些振动感知为噪声。随着速度的增加,这种效应急剧增加。
常见的头盔可以包括几个层,包括壳体、减震层和舒适层。头盔的壳体是最外层且通常由弹性、防水材料制成,例如塑料和纤维复合材料。壳体在空间上(从某种程度上)划分壳体内部与壳体周围环境。头盔的减震层,作为其主要安全层,可以由刚性但减震材料制成,例如可膨胀聚苯乙烯泡沫。虽然不是典型的,但头盔的防火层可以被整合,并且由耐火和防水的例如乙烯基腈的闭孔材料制成。此外,此层可以具有声音和热绝缘性质,并且可以替代地称为声学层。最后,头盔的舒适层可以由意在与摩托车手的皮肤接触的例如本领域已知的棉或其他织物混合物的软质材料制成。也可以存在其他层,并且可以省略或组合一些上述层。
头盔可以包括耳罩,所述耳罩可以被模制到头盔的刚性部分中,例如泡沫层。耳罩可以是静态的,并且仅为摩托车手的耳朵和/或扬声器提供空间,使得摩托车手可以收听音乐或通过电子通信系统通信。在一些情况下,耳罩可以安装到头盔的壳体,使得所述耳罩可以对摩托车手进行扩音并提供更好的舒适感。耳罩可以形成于振动地耦合到头盔的壳体的刚性材料中,或者耳罩直接连接到头盔的壳体。在这两种情况下,来自风和其他噪声源的振动很容易从头盔的壳体传输到耳罩,且然后传输到摩托车手的耳朵。这种振动耦合又为摩托车手创造了刺激性噪声。
图1是示例性摩托车头盔100的透视图。头盔100包括外壳101、声学层102、泡沫层103和舒适层104。声学层102(与发泡层103和/或舒适层104连接)可被构造为形成被动降噪系统。头盔100还包括安装在头盔100的每个内侧上的耳罩105和106,当用户戴上头盔100时用户的耳朵将置于耳罩105和106内。注意,在图1中仅有一个耳罩105是可见的。然而,虚线中所示的相同的耳罩106位于头盔100的相对侧上。耳罩105通过隔离安装件107与头盔100的壳体101隔离(并且耳罩106也是如此)。隔离安装件107可以由减振材料制成。减振材料可以防止壳体振动到达用户的耳朵,并且因此可能降低用户对作为噪声的那些振动的感知。因此,通过将耳罩105安装到除了头盔的壳体101之外的其他部分,并将其与容易传输振动的刚性材料解耦,可以被动地减小传输到耳罩105的噪声。
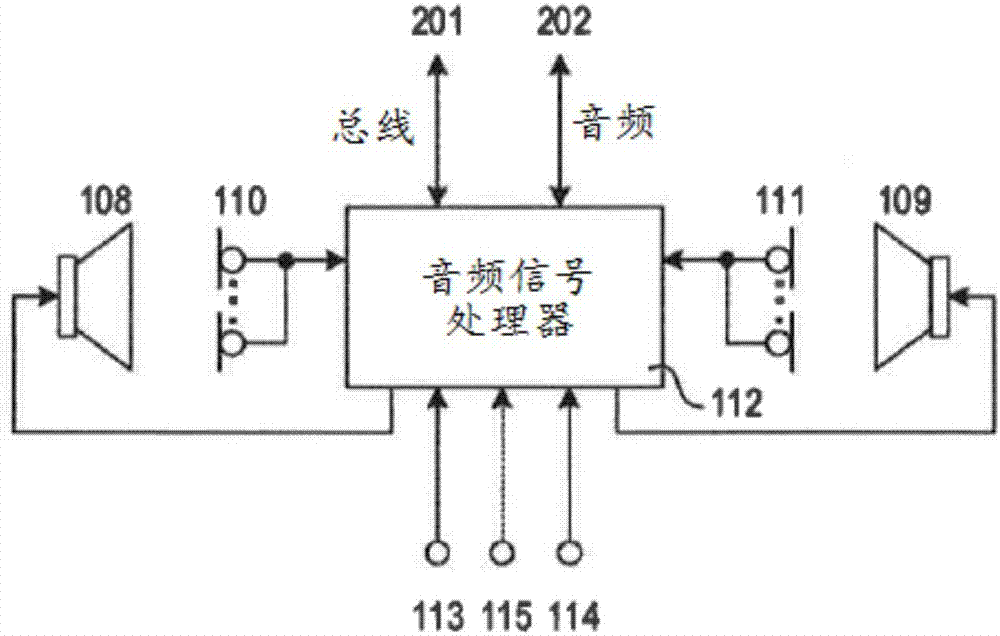
每个耳罩105、106可以部分地容纳例如内置于耳罩105、106中的扬声器108、109或其他类型的声音驱动器或电声换能器或一组扬声器。此外,头盔100可以包括一个或多个声学传感器,例如麦克风阵列110和111,其中每个麦克风阵列具有多个(例如四个)单独的麦克风,所述麦克风可以在壳体内部围绕耳罩105和106布置成圆形。在耳罩或扬声器附近(例如,周围)放置多个麦克风允许声学地匹配例如戴着头盔的不同人的不同耳朵位置。麦克风阵列110和111感测噪声,并且连同扬声器108和109以及音频信号处理器112一起在麦克风阵列110和111(例如每个耳罩105和106中)的位置处有效地消除噪声。扬声器108和109以及麦克风阵列110和111连接到可以包括主动降噪功能的(模拟和/或数字)音频信号处理器112。以这种方式,可以组合被动降噪(如上进一步所述)和主动降噪的益处。音频信号处理器112可以部分地或完全地安装在壳体101内(即,安装在壳体内部中),并且可以通过减振材料与壳体101振动隔离。
或者,音频信号处理器112完全安置在头盔100的外部,并且扬声器108、109与麦克风阵列110和111经由有线或无线连接被链接到音频信号处理器112。此外,音频信号处理器112-无论其被安置在哪里-可以经由有线或无线连接被链接到音频信号总线系统和/或数据总线系统(均未在图1中示出)。音频信号处理器112还可以连接到至少一个(另外)声学或非声学传感器,例如加速度传感器113和114,其被机械地耦合到壳体101(内侧或外侧)并且可以安置在头盔100的相对侧处。除了非声学传感器(加速度传感器113和114)以外或替代地,至少一个声学传感器(例如,声学传感器115)可以声学地耦合到壳体101的外部表面(例如,指向壳体周围环境)。
图2是上面结合图1中所示头盔100描述的系统的信号流程图。麦克风阵列110和111向音频信号处理器112提供表示由麦克风阵列110和111在其相应位置处拾取的声音的电信号。加速度传感器113和114(和/或声学传感器115)向音频信号处理器112提供表示加速度传感器113和114在其相应位置处拾取的壳体101的振动的电信号。音频信号处理器112处理来自麦克风110、111和加速度传感器113、114的信号,并且从其产生供应给扬声器108和109的信号。音频信号处理器112可以另外经由数据总线201和/或音频信号总线202传输或接收数据和/或音频信号。例如,经由数据总线201或音频信号总线202传输的音频信号可以用于在壳体内部播放音乐或语音。
图3示出了上面结合图2描述的音频信号处理器112的一个anc通道300。另一个通道(未示出)可以相同地实施并且连接到相应的其他扬声器、麦克风或加速度传感器,但是接收并提供相似类型的信号。anc通道300包括anc处理器301,其从单个麦克风、麦克风阵列或从连接在多个麦克风或麦克风阵列下游的组合器302接收滤波器输入信号。组合器302可以是加法器,所述加法器将来自例如麦克风阵列(例如图1中所示的阵列中的麦克风阵列110和111)的多个麦克风的信号进行组合(相加)。组合器302可以是如上所述的普通加法器或任何其他类型的组合器,例如加权和/或滤波加法器、多路复用器、(智能)开关等。
此外,可以包括固定滤波器或自适应滤波器的anc处理器301将滤波器输出信号提供给扬声器108(或109)。扬声器108(或109),包括组合器302的麦克风阵列110(或111)和anc处理器301可以形成反馈anc结构或组合式前馈反馈结构的一部分,其中麦克风阵列110(或111)与包括anc处理器301的扬声器108(或109)对来自麦克风阵列110(或111)的信号进行滤波,然后将所述信号供应给扬声器108(或109),使得由扬声器108(或109)产生并且经由扬声器108(或109)与麦克风阵列110(或111)之间的声学路径传送到麦克风阵列110(或111)的声音可以减少或消除在麦克风阵列110(或111)的位置处发生的其他源的声音。
除了噪声降低结构之外,anc通道300还可以包括相关器303(执行交叉相关或自动相关操作中的至少一者),其接收来自加速度传感器113(或114)的信号和表示摩托车特性(例如其电动机的每分钟转数(rpm))的信号中的至少一者。表示摩托车特性的信号可以经由有线或无线数据总线310来传输,并且可以包括对应于电动机的每分钟转数(rpm)的rpm数据。这些rpm数据可以由电动机声音合成器304转换为电声音信号,所述电声音信号表示当以特定的rpm操作时由摩托车(例如,其电动机)产生的声音信号。或者,表示当以特定rpm操作时由电动机产生的声学声音信号的电声音信号可以由在电动机附近拾取原始电动机声音的另一个麦克风(未示出)产生,并且可以通过数据总线310的方式传送到相关器303。
相关器303可以将来自电动机声音合成器304的基本谐波信号与来自加速度传感器113(或114)的信号(其是包括谐波信号分量和非谐波分量的信号)交叉相关。或者或另外,例如在执行交叉相关操作之前,可以对来自传感器113(或114)的信号应用自动相关操作。与外壳连接的加速度传感器113(或114)不仅形成振动传感器,而且形成拾取头盔100附近的周围环境声音和由头盔100产生或在头盔100处发生的声音的一种麦克风。与外壳连接的加速度传感器113(或114)对直接的风噪声不太敏感,这可能导致当使用常见麦克风时对实际周围环境声音的不正确测量。
相关器303输出谐波的或与谐波电动机声音相关的信号(称为相关分量)和非谐波信号或与谐波电动机声音不相关的信号(称为不相关分量)。相关分量对应于来自加速度传感器113(或114)的信号中含有的谐波电动机声音。此电动机声音分量可由增益/滤波器模块305以衰减和/或滤波的方式添加到由anc处理器301供应到扬声器108(或109)的信号,使得其以可听而愉快的方式呈现给戴着头盔100的用户。增益/滤波器模块305包括不同的操作模式,所述操作模式可以由允许用户调谐呈现给他或她的声音的信号来控制。可选地,来自加速度传感器113(或114)的包括来自加速度传感器113(或114)的信号中含有的噪声的信号的不相关分量可以被供应给anc处理器301,以便实施前馈结构或组合式反馈前馈结构,如下面进一步详述。
替代地或除了表示电动机声音的信号之外,表示具有汽车、其他摩托车、喇叭或警笛的特定频率特性的其他期望的谐波分量的信号可以形成相关操作的基础。此信号可以由特定的警告声音合成器306产生,警告声音合成器306可以包括不同的操作模式以解决不同的声音情况,例如在不同的国家中改变警告信号等,并且可以通过信号mod2的方式进行调谐,信号mod2允许用户选择他或她希望听到的警告声。信号mod1允许再次调谐呈现给用户的声音。另外或替代地,不同的控制信号可以存储在存储器中,或者经由有线或无线连接来传输,这取决于头盔当前所在的位置。位置可以例如通过全球定位系统(gps)307来确定,并且使用位置来选择要从由加速度传感器113(或加速度传感器114或麦克风115)提供的信号提取的特定位置的期望谐波分量,例如对于相应位置是典型的警告信号可以与由数据存储器309或经由数据总线308作为信号mod2提供的相应控制数据相关联。
参考图4,在可以用于在图3中所示的布置中在anc处理器301中形成反馈结构或组合式前馈反馈结构的一部分的反馈型anc处理器400中,一个干扰信号d[n](也被称为噪声信号)经由主路径401被传送(辐射)到收听地点,例如用户的耳朵。主路径401具有传送特性p(z)。另外,输入信号v[n]经由次路径402从例如扬声器108(或109)的扬声器传送(辐射)到收听地点。次路径402具有传送特性s(z)。定位在收听地点处的例如麦克风110(或111)的麦克风或麦克风阵列接收由扬声器108(或109)产生的信号和干扰信号d[n]。麦克风110(或111)提供表示这些所接收信号之总和的麦克风输出信号y[n]。麦克风输出信号y[n]作为滤波器输入信号u[n]被供应给反馈anc滤波器403,反馈anc滤波器403向加法器404输出误差信号e[n]。可以是自适应滤波器的反馈anc滤波器403具有传送特性w(z)。加法器404还从相关器303接收经衰减或经预滤波的相关信号作为输入信号x[n],并向扬声器108(或109)提供输出信号v[n]。除了加法器404之外或替代加法器404,减法器405可以从麦克风输出信号y[n]中减去输入信号x[n],以形成反馈anc滤波器输入信号u[n]。因此,可以经由加法器404或减法器405或者加法器404与减法器405两者将期望的相关声音注入到反馈回路中。可选地,形成输入信号x[n]的经衰减或经预滤波的相关信号可以被具有传递函数h(z)(例如低通滤波器特性)的额外滤波器406进行滤波,然后将所述相关信号供应给减法器405。
信号x(z)、y(z)、v(z)、e(z)及u(z)以谱域(z域)表示(离散)时域信号x[n]、y[n]、v[n]、e[n]及u[n],使得描述图4中所示出系统的不同方程式如下:
y(z)=s(z)·v(z)=s(z)·(e(z)+x(z)),
e(z)=w(z)·u(z)=w(z)·(y(z)-h(z)·x(z)),
并且假定h(z)≈s(z),则e(z)=w(z)·u(z)≈w(z)·(y(z)-s(z)·x(z))。
可选地,例如音乐或语音的期望信号可以用anc处理器400播放,例如通过例如以加法器408的方式将来自源407的期望信号m[n]添加到相关信号以形成输入信号x[n]。当信号检测器410检测到相关信号时,期望的信号m[n]可以通过可控(软)开关409静音。例如,当anc处理器400要再现例如喇叭或警笛的警告信号时,只要警告信号存在,开关409即将音乐(例如,由期望信号m[n]表示)静音,即(软)关掉。
图5是示例性前馈anc处理器500的框图,前馈anc处理器500采用滤波x最小均方(fxlms)算法,并且可用作图3中的anc处理器301或可用于anc处理器301中。在图5中,主路径再次指示为p(z)、次(或前进)路径再次指示为s(z)、次路径的估计
在图5中所示的前馈anc处理器中,来自相关器303的相关信号和来自增益/滤波器模块305的经衰减或经预滤波的相关信号由加法器506相加,以提供供应给自适应滤波器501和滤波器503的输入信号x[n]。自适应滤波器501将信号y[n]供应给扬声器108/109,并且具有由最小均方(lms)模块502控制的传递函数w(z)。lms模块502接收来自麦克风110/111的误差信号和来自滤波器503的信号。来自滤波器503的信号表示用作为次路径的估计
e(z)=p(z)·x(z)+s(z)·y(z)=(p(z)+s(z)·w(z))·x(z)
自适应滤波器501的目标(其意指传递函数w(z))是使误差e(z)最小化,在理想情况下,误差e(z)在传递函数w(z)的收敛之后将等于零。因此,在上述方程式中,设e(z)=0,给出最优滤波器如下:w(z)=-p(z)/s(z)。
图6是用于图1中所示的头盔中的示例性麦克风扬声器组合601(而不是耳罩105和106)的透视图。与耳罩105和106相反,麦克风扬声器组合601直接安装到壳体中而没有任何减噪囊封。麦克风扬声器组合601包括容纳扬声器603的外壳602。扬声器603安置在外壳602的内部中,并且具有覆盖外壳602中的开口604的前面。在开口604的外侧上,即在扬声器603前方,横档605穿过开口604。横档605支撑与开口604的区域平行定向的单个麦克风606。替代单个麦克风,可以使用麦克风阵列。图7是用于图1中所示头盔内部中的面颊部件701的透视图。脸颊部件701可以由例如eps的塑料制成,并且可以用软织物(未示出)覆盖。麦克风扬声器组合601可以在头盔用户的耳朵的位置处压配合到面颊部件701中,而无需任何另外的阻尼措施。
图8示出了可以例如由图1-7中所示的系统执行的用于头盔的示例性主动降噪方法。头盔具有刚性壳体,所述刚性壳体在空间上划分壳体内部与壳体周围环境。在工序801中,接收至少一个期望声音信号,所述信号表示在壳体周围环境中出现的至少一个期望声音模式。在工序802中,基于至少一个期望声音信号产生反声,所述反声被配置为通过叠加来与壳体内部中发生的内部声音相互作用。内部声音包括第一内部声音分量和第二内部声音分量,所述第一内部声音分量不对应于至少一个期望声音模式,而所述第二内部声音分量对应于至少一个期望声音模式。所述反声还被配置为衰减所述第一内部声音分量,并且使所述第二内部声音分量放大、不衰减或衰减到比所述第一内部声音分量小的程度。
图9示出了用于具有刚性壳体的头盔的示例性认知方法,所述刚性壳体在空间上划分壳体内部与壳体周围环境。在程序901中,接收至少一个播放声音信号。在程序902中,在壳体内部中产生来自至少一个播放声音信号的播放对应的声音。程序903包括接收并处理表示在壳体周围环境中发生的声音的至少一个周围环境声音信号以检测至少一个期望声音信号。当检测到至少一个期望声音模式时,暂停至少一个播放声音的产生(步骤904)。
参考图10,用于具有刚性壳体的头盔的示例性自动噪声控制方法可以包括:基于至少一个输入信号,结合安置在壳体内部中的至少一个扬声器在壳体内部中产生反声(工序1001),所述刚性壳体被配置为在空间上划分壳体内部与壳体周围环境。所述反声被配置为通过相消叠加来衰减所述壳体内部中发生的声音。程序1002包括通过以下各项中的至少一者来提供至少一个输入信号:在壳体内部中的扬声器附近拾取声音(子程序1003);拾取壳体的振动(子程序1004);以及在壳体外部附近拾取声音(子程序1005)。
本文描述的头盔、系统、方法和软件允许衰减、减少或消除非谐波声音,例如由风或雨产生的噪声。然而,例如摩托车的电动机声音、警笛和喇叭等所有或选定的谐波信号仅减少到令人愉快的程度。此外,当警告信号等发生时,可以将音乐静音,以指示摩托车手充分注意警告信号。
注意,上面所示的所有滤波器可以是固定的、受控的或自适应滤波器,并且可以像上述示例中的所有其他信号处理部件一样以模拟或数字硬件或以软件实现。滤波器可以具有任何结构,并且可以任何类型(例如,有限脉冲响应、无限脉冲响应)应用。使用的扬声器、麦克风和anc通道的数目是不受限制的,并且这些可以被布置成任何可能的群组(例如,每四个麦克风结合两个anc通道、两个非声学传感器和两个扬声器的两个群组,或者每两个麦克风结合每个麦克风一个anc通道、一个非声学传感器和两个扬声器的两个群组等。anc通道可以具有可适用的任何结构,例如反馈、前馈或组合式前馈反馈结构。此外,替代对来自非声学传感器的信号和表示电动机或摩托车特性的信号进行交叉相关操作,可以仅对来自非声学传感器的信号应用交叉相关操作。替代非声学传感器,可以使用声学传感器。如本文所述的摩托车头盔包括可以类似方式使用的所有类型的头盔。此外,上述系统和方法可以与所有类型的主动噪声控制系统一起使用。
虽然已经描述了本发明的各种实施例,但对于本领域普通技术人员来说显而易见的是,在本发明的范围内,更多的实施例和实施方案是可能的。特定地,技术人员将认识到来自不同实施例的各种特征的可互换性。尽管已经在一些实施例和示例的上下文中公开了这些技术和系统,但应理解,这些技术和系统可以超出具体公开的实施例被延伸到其他实施例和/或其用途和明显的修改。因此,除了鉴于所附权利要求书及其等效物之外,本发明不受限制。
- 还没有人留言评论。精彩留言会获得点赞!